
HRMOSでは顧客満足を最優先し、価値あるソフトウェアを早く継続的に提供するため、スクラムに加え、Site Reliability Engineeringをプロダクト開発に適用し、SLI/SLOを定め、運用しています。また、エラーバジェット枯渇時にどのように行動するのか、その運用ルールも定めています。
私たちと同じようにエラーバジェットを運用する組織において、枯渇後のアクションとしてリリース凍結1を視野に入れようとする場合、プロダクトや関係者に与える影響は大きいため、そのルールの策定や調整に頭を悩ますケースも多いのではないでしょうか。
HRMOSの中でも特に歴史の長いプロダクトであるHRMOS採用では、SREチーム内や関係者との間で議論を重ねてルールを見直してきたため、これからエラーバジェットの運用を開始しようとしている方々の参考になればと思い、現在どういった点を考慮して運用しているかを紹介させていただきます。
エラーバジェットとは
エラーバジェットとは、SLO(サービスレベル目標)2から導かれる、許容される信頼性3損失の度合いです。
例えば、SLI(サービスレベル指標)の1つとして、全リクエストに対する正常レスポンス率を採用しているとします。さらに、このSLOを99.99%と定めていたとします。
この場合、エラーバジェットは100% - 99.99% = 0.01%であり、エラーレスポンス率0.01%までは「予算」として許容した上でサービスを運用します。
エラーバジェット運用の目的
プロダクト開発において、プロダクトオーナーや開発チームはユーザーや市場にとって魅力的な機能を次々とリリースさせていくことが求められます。一方でSREチームは、プロダクトが期待した時に期待通りに動くこと、つまり信頼性に強い関心を持ちます。
両者の目指す方向はともすれば相反するところがあり、機能の開発速度を重視しすぎると、それは障害のリスクを高め、ひいては信頼性を脅かします。逆に信頼性を過剰に求めると、プロダクトは硬直化し、市場での魅力を失うことになります。
よって、開発速度と信頼性のバランスを取ることが重要となりますが、これを両チームやステークホルダーとの間での「交渉」や「力関係」といったものではなく、共有された客観的なメトリクスに基づいて判断可能とするためにエラーバジェットを運用します。
エラーバジェット枯渇時のアクション
このエラーバジェットが枯渇した時、SLOは未達状態にあります。これは過去の一定期間に渡ってサービスはユーザーに対して好ましくない体験をさせ続け、それが許容できないレベルに達してしまっていることを意味します。
そのため、SLIの値、すなわち信頼性を回復するための行動を取ります。基本的な方向性としては、以下のようなものとなります。
- さらなる信頼性低下のリスクを抑えるために機能の開発やリリースを凍結し、信頼性回復のための改修に注力する
ただし、こうした行動を取ることは、プロダクトがユーザーへ新たな価値を提供するという面においては停滞をもたらし、状況やタイミングによってはビジネス上の強いインパクトを与えることになりますので、関係者との協議の上、慎重に決定するようにしています。
エラーバジェット枯渇後の大まかな流れとしては以下となります。
- SREチームはプロダクトオーナー、開発チーム、ステークホルダーにエラーバジェットが枯渇したことを周知し、臨時の会議体を設ける
- エラーバジェット枯渇の要因を分析した上で、機能リリースを凍結するかしないかを協議する
- 機能リリースの凍結を決定した場合にはその凍結解除基準を策定する
このようなプロセスを取ることについては、エラーバジェットの運用を開始するより以前にあらかじめ各関係者の合意を取り、ルールとして定めるようにしています。そうした合意がなければ、エラーバジェットが単なるメトリクスに留まり、組織の意思決定ツールとしての機能を果たすことができないためです。
なお、スクラムにおいてはプロダクトに対してリリースを行なっても良いかどうかの基準として、Doneの定義がありますが、私たちはその中の一項目として、「SLOを下回っていないこと(つまり、エラーバジェットが枯渇していないこと)」を組み込んでいます。
このシンプルな工夫により、スクラムに関わる全員が、自然とエラーバジェットを意識したプロダクト開発を行うようになることを実現しています。
エラーバジェット枯渇後の運用において考慮していること
ここからは、エラーバジェット枯渇後の運用において考慮している以下3点について解説したいと思います。いずれもリリース凍結に関わる事項となります。
- 許容するリリースを定めておく
- 機能リリース前の開発作業の凍結に対する方針を定めておく
- 凍結解除基準を策定する
1. 許容するリリースを定めておく
リリース凍結、といっても一律にあらゆるリリースを凍結することはしていません。
凍結前後に発生した本番障害への緊急対応(hotfix)や、今回のエラーバジェット枯渇を契機に着手した信頼性回復のための改修(5xxエラー4改善、レイテンシー改善等)はリリース可となります。
その他、凍結判断以前からリリース時期が決定しており変更が困難なもの、例えば対外的に時期を約束しているものに関しては例外的にリリースを許容しています。
どのようなリリースを許容しているのかについては、あらかじめエラーバジェット運用ルールに盛り込み、関係者と事前に共有するようにしています。そうすることで、SREと関係者でいざリリースを凍結する・しないを協議するとなった際に、お互いに同一の前提をもって円滑に議論できるようにしています。
2. 機能リリース前の開発作業の凍結に対する方針を定めておく
リリース凍結の指す範囲が、本番への機能リリース行為だけでなく、そこに至るまでの一連の開発作業も含めるのかどうかを方針として定めています。
これに関しては、機能の開発作業についても停止の検討対象としつつも、最終的な判断はプロダクトオーナーに委ねることとしています。
| リリース内容 | リリース可否 | 開発作業の可否 | |
|---|---|---|---|
| 本番障害への緊急対応 | 可 | 可 | |
| 信頼性回復のための改修 (5xxエラー改善、レイテンシー改善等) | 可 | 可 | |
| 上記以外を目的とする機能リリース | リリース時期変更が困難なもの | 可 | 可 |
| 上記以外 | 協議の上で決定 | プロダクトオーナーにて判断 | |
まず、前提としてリリース凍結を行うことでどういった効果を期待しているかというと、本番のプロダクトへの変更を禁止することで新たに障害やバグが発生するリスク自体を排除し、信頼性のさらなる低下に歯止めをかけることです。
そこに加えて機能の開発作業を凍結するのは、信頼性回復のための改修を最優先で実施するにあたり、必要となる開発リソースを捻出するためです。
しかし、開発チームの規模がある程度大きい場合、信頼性回復のためにリストアップした全てのタスク量に対して、エンジニアが余剰気味になってしまうことがありえます。かといって、1人で担当できるタスクに2人以上を割り当てても、それらタスクが半分以下の時間で終わるわけでもありません。
そのため、信頼性回復のためのタスクに充分なエンジニアをアサインできたのであれば、その他のエンジニアには通常の機能開発を進めてもらうといった総合的判断を取ることができるようにしています。
なお、開発チーム内に特別な目的を持って契約した有期の業務委託エンジニア(例えば、今後リリースを予定している新機能開発に必要となる特定技術に精通している等)がいる場合にも、このエンジニアには信頼性回復よりも本来の新機能開発を進めてもらうことになります。
3. 凍結解除基準を策定する
前述の通り、リリース凍結を決定した際には併せて凍結解除基準も策定します。
「エラーバジェットが枯渇、つまりSLIの値がSLOを下回ったことでリリース凍結に入ったのだから、再びSLOを上回るようになったら凍結解除する」というのがシンプルかつ明解なのですが、一律にそうした基準にはせず、凍結解除基準は関係者と協議の上で都度策定するようにしています。
というのも、SLOは「現時点から見て過去30日などの一定期間(以後、これを時間ウィンドウと呼びます)」のデータに基づいて算出されたSLIの値と照らし合わせているわけですが、障害などを契機に急速にSLIの値が下がった場合、障害の一次対応収束後も時間ウィンドウ内に障害発生時期が含まれる限りはSLO未達状態が続くことが見込まれます。
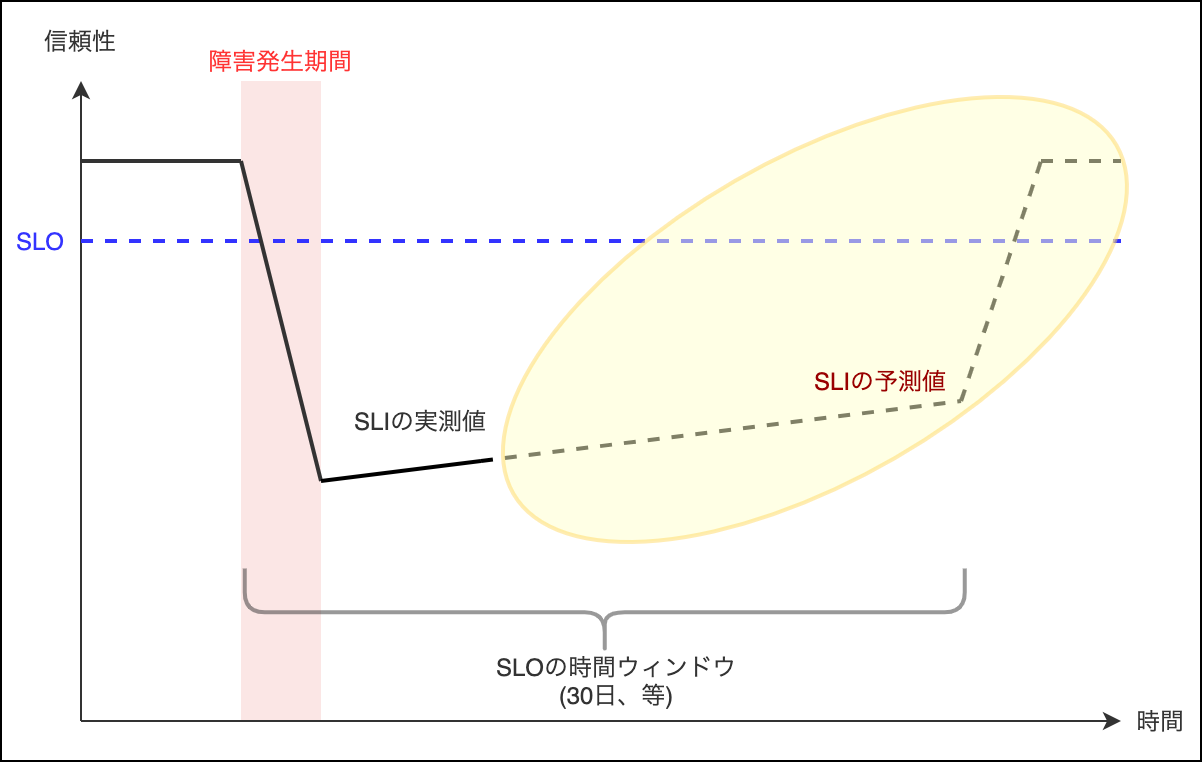
つまり、SLOの時間ウィンドウが30日である場合、向こう約30日はリリース凍結期間が続くことになります。
しかし、「信頼性を毀損した直接の原因である障害自体は既に取り除かれていて、信頼性はSLO未達ながら回復へ向かっているにも関わらず、30日の間に渡って機能のリリースを再開できないこと」に対して、プロダクトオーナーや開発チームの立場からするともどかしい思いをするかもしれません。また、30日という期間は特に市場での競争の激しいプロダクトであれば大きな痛手となる恐れもあります。
そういったことも考慮し、凍結解除基準には一律にSLOを採用するのではなく、その他の要素も加味できる余地を持たせています。例えば、今回の説明では障害によるエラーバジェット枯渇を取り挙げていますが、そのポストモーテムで決定したアクションアイテムのうち、特に重要なものが完了していることを凍結解除基準とする、といった具合です。
- 障害の再発防止策が実施済みとなっていること
- (障害対応時の動きに課題があれば)障害対応訓練が実施済みとなっていること 等
なお、ここからは凍結解除後の話となりますが、エラーバジェットが枯渇した状態でリリース凍結を解除することとなった場合、引き続きSLIの値がSLOを下回っている間においてはエラーバジェットはやはりゼロですので、SLIの値がそこからどの程度下がったら再度のリリース凍結の検討に入ることとするのかをあらかじめ考えておく必要があります。
これに関しては、通常よりも短い時間ウィンドウ(7日など)のSLIの値を計測し、これがSLOを上回っているかどうかで判断するようにしています。
そして、通常の時間ウィンドウ(30日など)のSLIの値がSLOを上回るようになったら、従来通りこちらを元にエラーバジェットの運用を行います。
ルールの変更と継続的改善
今回紹介したエラーバジェット運用ルールは完成されたものというわけでなく、SREチームや開発チーム、プロダクトオーナー、その他ステークホルダーから変更を提案できるルールとしています。エラーバジェットに基づいた意思決定を組織として継続して行っていくためには、その運用方法に対する各関係者のコミットメントが不可欠です。そのためにも改訂のプロセスをルール内に明文化するようにしています。なお、運用ルールの変更だけでなく、SLI/SLOの変更に関しても提案可能としています。
変更の提案が行われる状況としては、プロダクトオーナーや開発チーム側であれば、過度な信頼性向上のために機能開発が阻害されていると感じる場合、SREチーム側であれば、過度な労力を投下しなければSLOを遵守できないと考える場合などを想定しています。
また、本記事ではエラーバジェットを中心とした説明となりましたが、その算出の元となるSLI/SLOについても重要な継続的改善の対象と捉えています。具体的にはSLOの妥当性や、SLIそのものがお客様の満足度と相関しているかといった点について検証し、より洗練させていきたいと考えています。
終わりに
以上、エラーバジェット運用における様々な取り組みや考慮点について紹介しました。
最後となりますが、エラーバジェットの円滑な運用に向けては、運用ルールをしっかりとドキュメント化した上で関係者と合意を取るとともに、日頃からSREと関係者の間で信頼関係を醸成しておくことが何より重要かと思います。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










