
先日行われました AWS JAPAN SUMMIT ONLINE 2020 にて、「大規模な組織変遷と100以上のAWSアカウントの横断的セキュリティガードレール運用について」のテーマにて、私たちのグループで取り組んでいる全てのAWSに対する横断的な取り組みを ビジョナルCTO竹内 と ビジョナルCIO園田 より発表させていただきました。
今回は、その発表内容について、発表の中で伝えきれていない内容などより詳細にお話しさせていただきます。
こんにちは、システム本部 プラットフォーム基盤推進室ORE (Organizational Reliability Engineering) グループ の 長原 です。
私が在籍するグループでは、 Visionalグループの全事業のクラウドや非機能要件等に対して、横断的にエンジニアリングによる課題解決に取り組んでいます。
複数事業・マルチアカウント運用で生まれた課題
株式会社ビズリーチは、2020年2月よりグループ経営体制に移行し、新たにVisionalグループとして、「新しい可能性を、次々と。」というミッションのもと、様々な領域で事業創出を続けています。
グループ全体で運用しているAWSアカウントの数は100を超えています。
多くのAWSアカウントを運用する中で、以下のような課題がありました。
- 品質・セキュリティレベルの問題
- ⼀定以上の品質・セキュリティが満たされていない
- 各事業部のエンジニアにおけるクラウドやAWSの知⾒のばらつき
- 設定不備や操作ミスによる障害やセキュリティインシデントの潜在化
- 会社が把握していないシャドウクラウドの存在
- 監査・統制の非効率
- 100以上のAWSアカウントに対する監査・統制を⾏なうための作業の増加
- グループ全体のリスク把握が不十分
- 開発の非効率
- 新規作成アカウントの初期セットアップの手動対応などの手間
- 類似課題に対して各事業部で個々に対応することによる全体効率の悪さ
管理対象のAWSアカウントが増加するにつれ、課題感は顕在化してきました。
ソリューション
以下の大きく2つのソリューションにて解決を図りました。
ガードレール
アカウントに対して硬すぎる制限を設けるのではなく、できるだけ自由を確保しつつ望ましくない領域のみ制限、または発見できるソリューション
従来多く行われていた「ゲート」によるブロッカーとなる制御から、「ガードレール」として禁止操作を制限して危険な設定を検出することでアジリティを維持してガバナンスコントロールを実現することができます。
ガードレールには2つの種類が存在します。
- 予防的ガードレール (制限) : 対象の操作を実施できないようにするガードレール
- 発見的ガードレール (検知) : 望ましくない操作を行った場合、それを発見するガードレール
アカウントベースライン
マルチアカウント/マルチリージョン環境の共通リソースの設定を自動化するソリューション
組織内のAWSアカウントにおけるガードレールを実現するために、複数のAWSアカウントそれぞれに必要とされる共通の設定を一括で導入することを可能にします。
新規作成アカウントの初期セットアップやベースラインの更新に伴う一括変更を可能とし、効率的かつ確実性の高いマルチアカウント運用を実現することができます。
取り組みの全体像
前述したソリューションを実現するため、以下の取り組みを1年程度の期間で進めてきました。
| No | ソリューション | 概要 | 概説 |
|---|---|---|---|
| 1 | Visional-Baseline | アカウントベースライン管理 | ・ AWSアカウントに対して、ベースラインとなる共通設定項目を管理・適用する仕組み。ベースラインの構成管理及び、構成ドリフトを定期的に確認して差分を検出して通知する。 |
| 2 | AWS Organizations | 組織アカウントの一元管理 予防的ガードレール |
・ AWS Organizationsにて組織のアカウントや一括設定が可能なものは、Visional-Baselineと併用して組織の設定を管理・適用する仕組み。 ・ 組織全体で禁止する一部の操作のポリシーを管理/反映し、予防的ガードレールを実現。 |
| 3 | Amazon GuardDuty + AWS SecurityHub | 発見的ガードレール (セキュリティ脅威検知) | ・ 全アカウントのセキュリティ脅威をAmazon GuardDutyにて自動検出し、AWS SecurityHub経由で結果を集約して可視化及び重要度の高いものは通知する発見的ガードレールの実現。 |
| 4 | AWS Config | 発見的ガードレール (コンプライアンス遵守) | ・ 全アカウントに対して予め規定したルールへのリソースの準拠状況を自動評価し、評価結果を集約して可視化及び重要度の高いものは通知する発見的ガードレールの実現。 |
| 5 | Trusted Advisor Dashboard | 発見的ガードレール (AWSベストプラクティス評価) | ・ 全アカウントに対してAWS Trusted AdvisorによるAWSのベストプラクティスに則ったチェックを自動的に行い、チェック結果を集約して可視化及び一部通知する発見的ガードレールの実現。 |
※ AWS SUMMITの発表内容からNo.2 “AWS Organizations予防的ガードレール” を追加しています。
各々の取り組みの概略図は以下の通りです。
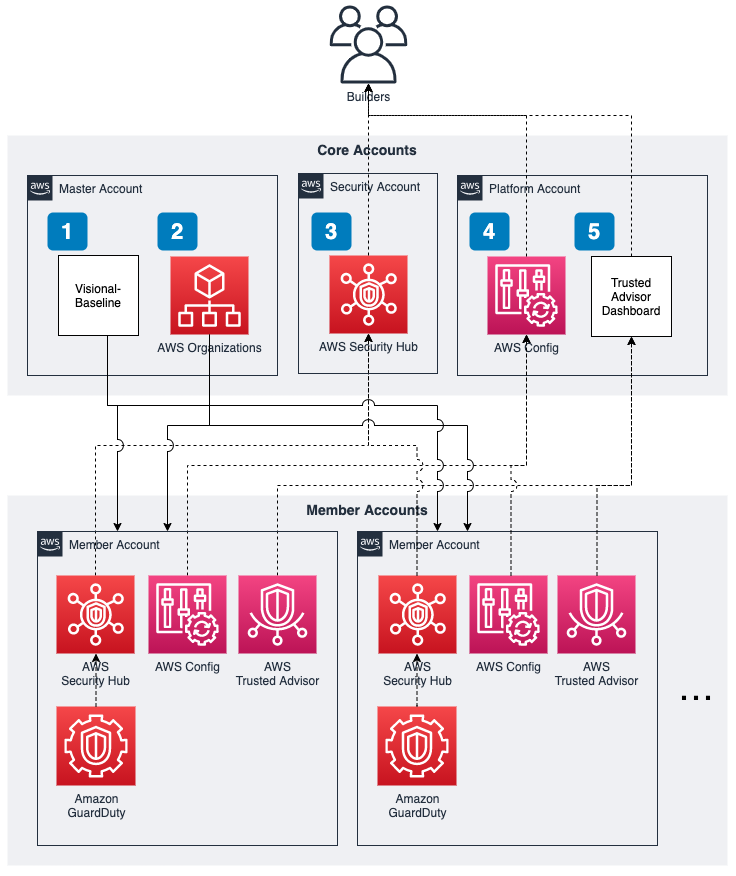
当社のAWSのマルチアカウント構成は以下の通りです。1
- Core Accounts : 組織 (AWS Organizations) にて、組織のアカウント群の管理が目的のアカウント群
- Master Account : 組織管理用のマスターアカウントです。一括支払設定やAWS Organizationsを利用した設定、組織全体ベースライン管理などを行います。必要最低限の機能のみを配置します。
- Security Account : セキュリティの部署が主に利用するアカウントです。脅威検出結果の確認等で利用します。
- Platform Account : プラットフォーム基盤推進室が主に管理するアカウントです。各種ソリューションのグループ向けのダッシュボード等を提供します。
- Member Accounts : 事業部のサービス利用や社内向けサービス等の目的のアカウント群
- Member Account #1, #2, #3, …
また、AWS Organizationsなど組織レベルで扱うAWSサービスや構築する機能検証のために、当社では2つのAWSの組織を構成しています。
検証用の組織には、上のCore Accountsの検証用アカウントを用意して、グループ全体のアカウントへの影響を排除した環境にて私たちの部署のみで利用しています。
ここからは、それぞれの取り組みの詳細について説明します。
アカウントベースライン
Visional-Baseline
Visional-Baselineは、マルチアカウント/マルチリージョンの組織内アカウント共通設定を管理するための独自の仕組みです。2
マルチアカウントの構成管理としては、 AWS Organizations とVisional-Baselineの2つの機能を利用して実現しています。
- AWS Organizationsによる構成管理
- AWS Organizationsの機能で、AWS Configのルール管理 / SCP (Service Control Policy) の禁止ポリシーの制御などAWSの組織に対してマスターアカウントで適用可能なものについては、AWS Organizationsの機能を優先して利用しています。
- Visional-Baselineによる構成管理
- AWS OrganizationsでサポートされていないAWSサービスの有効化や設定、リソースの作成などは、Visional-Baselineを利用して独自に構成管理を実現しています。
実現方式
Visional-Baselineは、構成管理 (IaC) の手段として Terraform を採用しています。
Terraformにてアカウントベースラインとなる設定を1つのリポジトリにて一元的に管理し、ターゲットとなるアカウントを指定してマルチアカウントへ並列実行できる仕組みにしています。
概略の構成と動作イメージは以下の通りです。
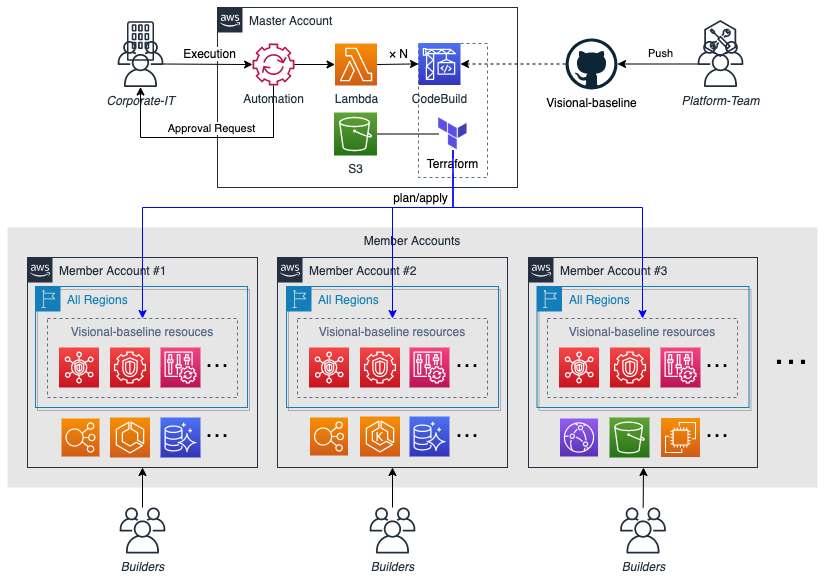
Visional-Baselineの機能は、AWSのマスターアカウントに配置しており、実行は AWS Systems Manager の Automation にて、実行の種類 (plan / apply) と対象アカウントを指定して実行します。
マスターアカウントは組織全体のAWSへの変更の権限を持つため、実際のオペレーションは厳格なプロセスによって内部不正のリスクを回避できるように設計しています。
私の所属する部門 (図のPlatform-Team) はマスターアカウントの参照権限のみを保持するようにしており、ベースラインのコードの開発を行っています。アカウントベースラインの設定が事業のサービスや運用へ影響がないことを予め考慮するため、主要事業部のSREのレビューを行い、マージ後に適用可能な状態となるようにしています。
実行のオペレーションはAWSのROOTアカウントの管理などマスターアカウントの全権限を持つ情シス部門 (図のCorporate-IT) が行い、Automationの承認ステップにて許可された承認者の承認後に実際の適用が行われます。
Automationの承認リクエストの送信や各アカウントへ適用後の結果は、Slackへの通知を組み合わせてオペレーションの簡略化と操作の透明性を高める工夫を行っています。
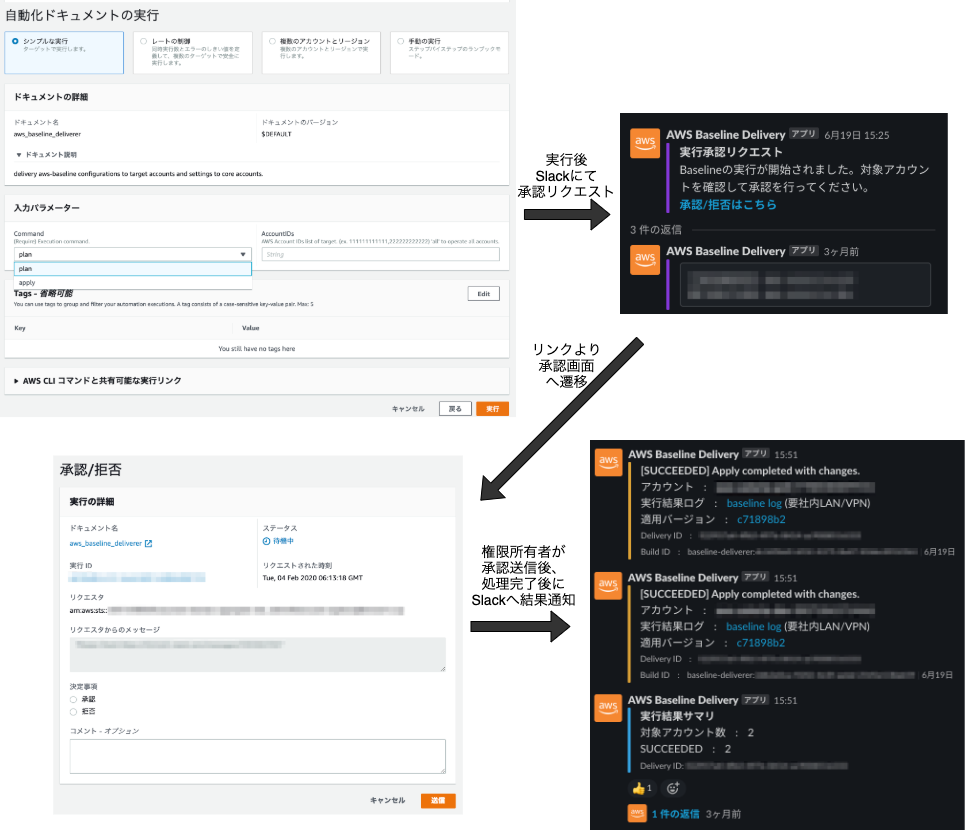
実際のオペレーションは以下流れとなります。
続いては、 Visional-Baselineのアーキテクチャです。
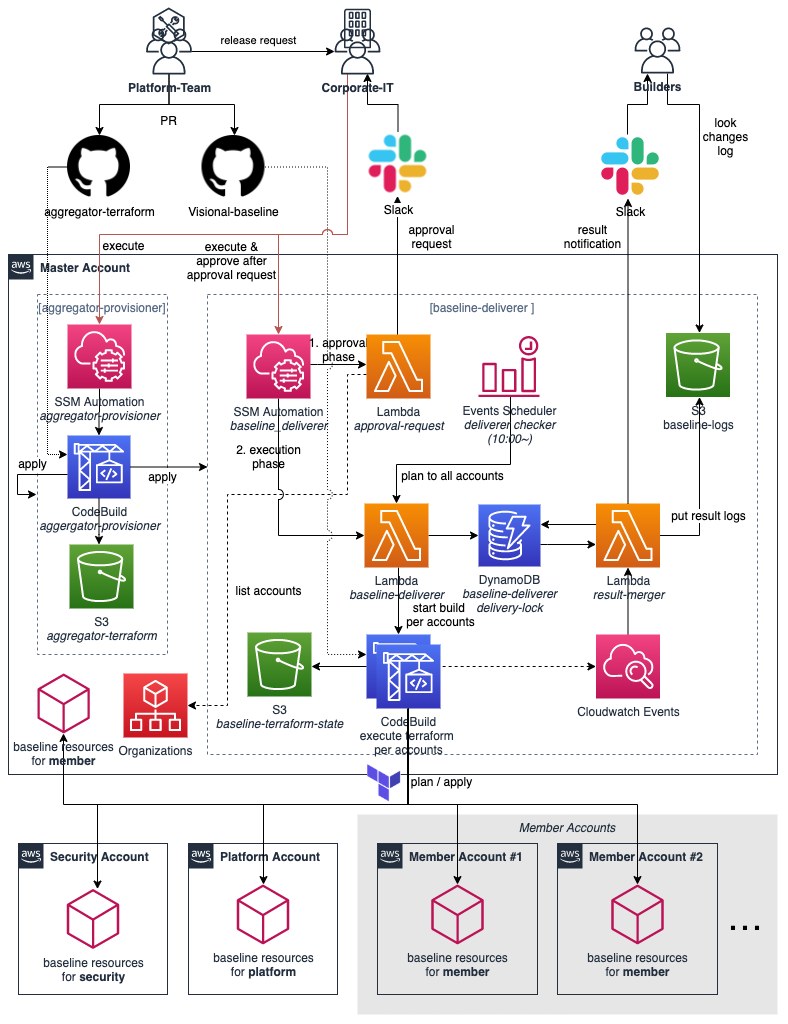
マスターアカウントの構成管理 (aggregator-provisioner)
マスターアカウントのTerraformのCI/CDの仕組みです。
ベースラインの仕組み (baseline-deliverer) の構成管理などを含みます。
ベースラインの実行機能 (baseline-deliverer左部)
オペレーションの実行I/Fには前述したAutomationを利用しており、実行後ははじめにApprove Phaseとして、 approval-requestのAWS Lambdaにて入力値の検証やAWSアカウントIDからアカウント名の逆引きを行い、ターゲットアカウントリストの情報など含めて承認リクエストをSlackで通知します。
承認処理が行われると、 AutomationよりExecution Phaseとして、 baseline-delivererのAWS Lambdaがinvokeされます。
baseline-delivererでは、ターゲットとなる複数のアカウントへ並列でTerraform実行して効率化するため、 AWS CodeBuild をアカウント数分実行しています。
AWS CodeBuildの実行は非同期の呼び出しで時間を要するため、 Automationは実行開始が確認できたら完了となります。
ベースラインの実行結果通知 (baseline-deliverer右部)
各アカウント分複数呼び出したAWS CodeBuildの実行結果の確認を簡略化するため、 Slackへ実行結果を通知しています。
全てのAWS CodeBuildが完了したことを検出するために、 Amazon CloudWatch Eventsの 終了のイベントを トリガにAWS Lambdaを実行しています。予め、 AWS CodeBuild呼び出し時にAutomation実行単位のIDとAWS CodeBuildの開始されたビルドIDをDynamoDBへ保管し、 AWS Lambdaでは、終了したAWS CodeBuildのビルドIDを突き合わせることで実行全体の完了を判断しています。3
個々のAWS CodeBuildの実行完了後、変更結果をSlackにて通知します。
Terraformの実行結果のログをメンバーアカウントの担当者へ閲覧可能とするため、 AWS CodeBuildの実行結果のAmazon CloudWatch LogsをS3へエクスポートし、変更結果の通知メッセージへそのログへのリンクを含めています。S3バケットは社内限定で参照可能としています。
また、全てのAWS CodeBuildの実行が完了した際には、実行全体の結果サマリをSlackへ通知し、ベースライン実行の結果を確認しています。
考慮点
Terraformのマルチアカウントサポート
Terraformにてマルチアカウントの構成管理を行っています。
マスターアカウントから、ターゲットのアカウントへTerraformを実行するには、 AWS Provider を定義する際に assume_role にてターゲットのアカウントのIAM Roleを指定することで、クロスアカウントでの実行を実現しています。
|
|
TerraformのStateファイルをマルチアカウントで管理するには、Terraformの Workspaces の機能を利用しています。
実行前に、ターゲットのAWSアカウントIDでworkspaceを切り替えてから実行します。
Stateファイルを管理するバックエンドは、S3 Backendにて全てのアカウントのStateファイルを管理しています。
構成ドリフトの検出
ベースラインでセットアップする設定がメンバーアカウントにて意図せずに変わった場合、ベースラインで設定する機能動作に支障をきたす恐れがあります。
そのため、日次で自動的にTerraformのplanを全アカウントへ実行することで、構成ドリフト (構成管理と実環境との設定差分) が発生している場合には、Slack通知を通じて検知しています。
この機能によって、ベースラインの設定が常に組織全体に対して適用されている状態を確認することが可能となっています。
また、完全に変更を禁止すべきものについては、後述する防御的ガードレールのSCPの機能によって対象リソースの変更操作を禁止することができます。
Terraformの採用理由
Terraform以外に、AWSではAWS CloudFormationをマルチアカウント/マルチリージョン向けに展開するためのStackSetsが提供されています。
StackSetsでは、CloudFormationテンプレートを指定したアカウントとリージョンに対して、一括で展開することができます。
ベースラインを導入した2019年時点では、StackSetsとTerraformを比較し、 以下の理由などからTerraformでの独自の展開の仕組みを構築することを選びました。
- StackSetsの強み
- AWSの公式のサポートを受けられる (当社のエンタープライズサポートの恩恵)
- マネージドサービスのためマルチアカウント/リージョンへの展開の作り込みが不要
- 同時実行数や耐障害性の失敗判定閾値のパラメータで実行制御が可能
- ターゲットへOUs (organizational units) を指定でき実行対象の管理が容易
- StackSetsの弱み
- その他考慮点
- 社内のクラウドのIaCはTerraformの利用がほとんどのため学習コストが少ない
また、StackSetsを内包して後述するガードレールを含めたランディングゾーンを構築する AWS Control Tower のサービスもありますが、AWS Control Towerは、東京リージョンではサービスが提供されていないこと、及び2019年時点では既存のAWS組織やアカウントの管理ができなかったため、採用は見送りました。5
効果
- これまでは、共通の設定を全体へ展開する場合は各々のAWS担当者と調整が必要となっていましたが、 最低限の工数で100以上のAWSアカウントへ共通設定の導入 できるようになりました。
- 複雑な設定を展開することは敷居が高かったですが、全て構成管理ツールで適用するため、 設定内容に左右されずに共通設定を導入 できるようになりました。
- 人手を介さない仕組みにより 全てのAWSアカウントへ確実に適用 できます。
- 万一共通の設定へ意図しない変更が行われた場合は、構成ドリフトを検出するため、 ベースラインの設定状況を担保 できます。
予防的ガードレール
サービスコントロールポリシー (SCP)
対象の操作を実施できないようにするガードレールとしては、AWS Organizationsの SCP (サービスコントロールポリシー) を活用しています。
発見的ガードレールにて望ましくない操作を検出しますが、明確に禁止された一定の操作を制限することで、リスクを回避することができます。
当社で禁止しているポリシーの一部は以下の通りです。
- AWS組織管理を維持するためのポリシー
- AWS Organizations脱退禁止
- AWS Organizations関連IAM Role削除禁止
- ガードレールの動作を保証するためのポリシー
- Amazon GuardDuty無効化/変更禁止
- AWS SecurityHub無効化/変更禁止
- AWS Config無効化/変更禁止
- デフォルトで無効になっているリージョンの有効化禁止
- アカウントベースラインの管理リソースを保証するためのポリシー
- 各種共通リソースの変更禁止
- 会社のルールとして禁止される操作を制限するポリシー
- IAM UserのConsole Access設定禁止
実現方式
AWS OrganizationsのSCPは、ポリシーを作成して、Root / OU / Accountに対してアタッチ可能となっています。
また、ヒエラルキーに従ってポリシーは配下のOU / Accountへ継承されます。
当社では、これまでAWS Organizationsでアカウントは管理していましたが、 OUs (Organizational Units) を活用しておりませんでした。
今後、OUを活用可能としていくため、現在ではトップレベルのOU (図のGlobal OU) を構成してそこに禁止ポリシー (図のDenyGlobal) をアタッチしています。

考慮点
ポリシーのアタッチ箇所について
SCPは、マスターアカウントで実行されたアクションについては制限することができません。
組織全体の禁止ポリシーはRootにアタッチすることも可能ですが、その場合には万一特定のユーザで禁止ポリシーを一時的に例外にしたい時に一時的に組織全体からデタッチする必要があります。
そのため、トップレベルのOUに全体の禁止ポリシーを付与しておくことにより、一時的に例外にするアカウントをRoot配下に移動させることで運用回避できる手段を用意しておくことができます。
特定のプリンシパルをポリシーの対象外とする
アカウントベースラインの適用は、TerraformにてメンバーアカウントへAssume Roleして操作するため、それも制限の対象となります。
SCPのポリシーのConditionにて aws:PrincipalARN で 除外するIAMロールを指定することで対象外にすることが可能です。
対象のIAMロール へAssume Roleを許可する信頼関係をマスターアカウントに限定し、そのIAMロールの変更についてもSCPで制限をかけておくことで、アカウントベースラインからの操作のみ許可した状態でメンバーアカウントでの操作のみを制限することができます。
効果
- これまでベースラインの設定などをメンバーアカウントで意図せず変えてしまうことで、発見的ガードレールの仕組みの機能不全に陥ったことが過去に発生していましたが、意図しない変更を抑止して 発見的ガードレールの動作を保証 することが可能となりました。
- 会社で禁止する操作がしばしば検出されていましたが、 禁止することでリスク回避 を実現しました。
発見的ガードレール
発見的ガードレールの仕組みにおいては、以下の共通の方針で設計しています。
- 全AWSアカウントの評価
- 組織内の全てのAWSアカウントを対象に評価を行います。
- AWSアカウント増減自動対応
- AWSアカウントが増減した場合の対応は基本的に全て自動化します。
- 評価結果の集約可視化
- 全体の状態を俯瞰して把握できるようにするために、結果は組織全体で集約して可視化します。
- 評価結果の公開性担保
- 社内利用を促進するため、機微情報を除いてダッシュボードは、社内に限定して公開します。
セキュリティ脅威検知 (AWS SecurityHub / Amazon GuardDuty)
発見的ガードレールのうち、AWSアカウントのセキュリティの脅威となりえる悪意あるアクティビティや不正な動作を検出するための Amazon GuardDuty とセキュリティアラートの一元的な管理を行うための AWS Securityhub を活用しています。
これまでは、組織内の全てのAWSアカウントで脅威検知を行っていなかったため、脅威の事実把握が十分ではない状況でした。
過去に発生したセキュリティインシデントでも、検出までの時間を要していたことで対処が遅れるといった事例もありました。
そのため、組織全体で脅威検知を導入してセキュリティインシデントの情報を集約して可視化と通知の仕組みを導入することで、セキュリティの部署にて統合的にモニタリングして、適切な対応を取るプロセスの構築しました。
実現方式
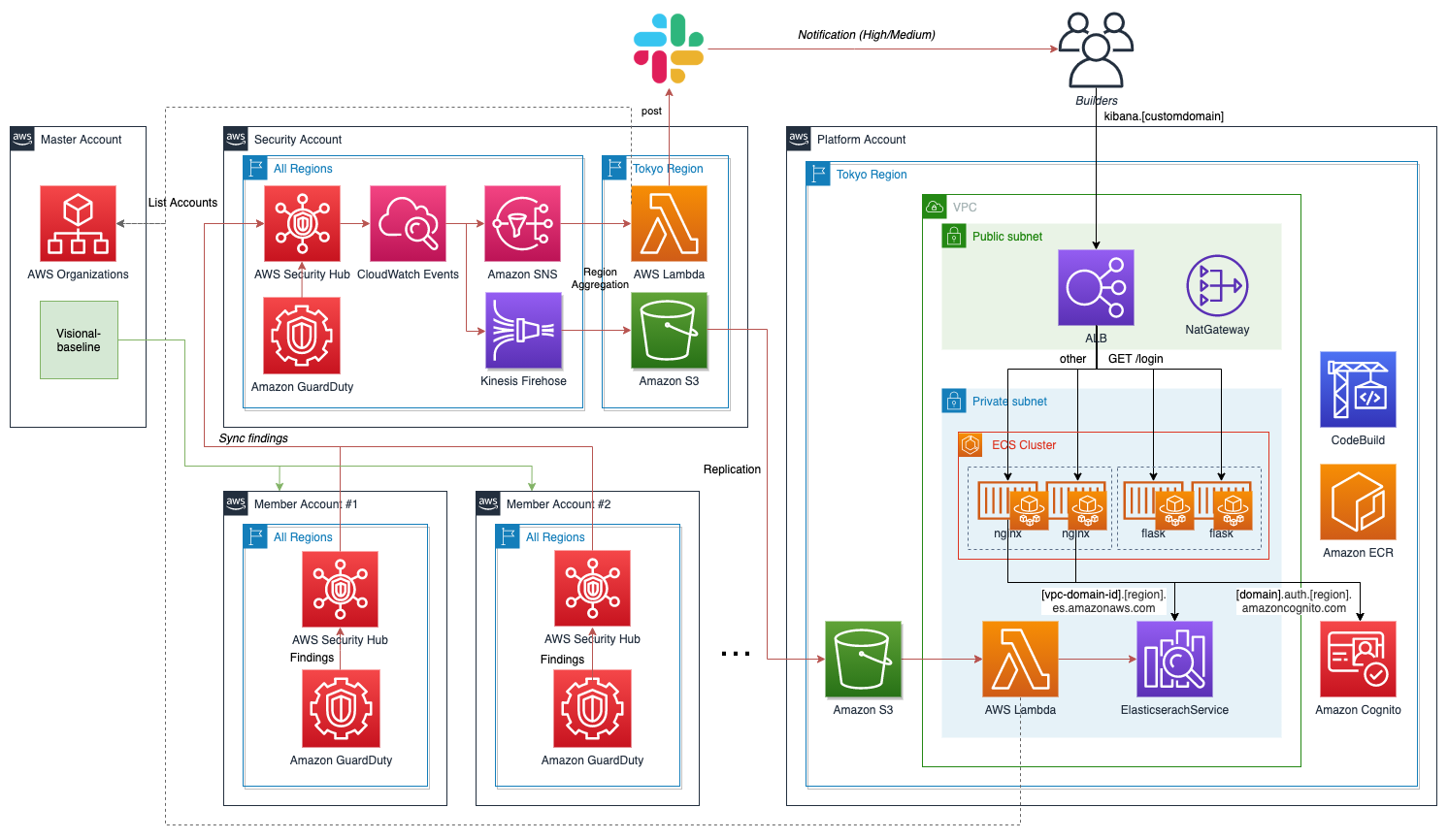
Amazon GuardDutyの全体構成は以下の通りです。
検出結果集約
Securityアカウントを組織内のAWS Securityhubマスターアカウントとして全てのセキュリティに関する情報を集約します。
Visional-Baselineによりメンバーアカウントの全リージョンのAWS SecurityHub及びAmazon GuardDutyのサービス有効化とSecurityアカウントのAWS SecurityHubと連携設定を行います。
各AWSアカウントでは、 Amazon GuardDutyとAWS SecurityHubを有効化することで、検出結果は自動的にAWS SecurityHubへ取り込まれます。
AWS SecurityHubのマスターアカウントへ連携しておくことで、自動的にSecurityアカウントへ結果が集約されます。
Securityアカウントでは、 Amazon CloudWatch EventsのAWS SecurityHubに関するイベントを全てのリージョンにて Amazon Kinesis Data Firehose で1つのS3バケットに出力することで、リージョンを集約して組織全体の検出イベントを保存しています。
Slack通知
SecurityアカウントのAWS SecurityHubへ連携された検出結果は、Amazon CloudWatch Eventsを通してSNSで東京リージョンへ全リージョンのイベントを集約して 東京リージョンのAWS LambdaでSlackの処理を行っています。
以下のイメージでSlack通知を行っています。
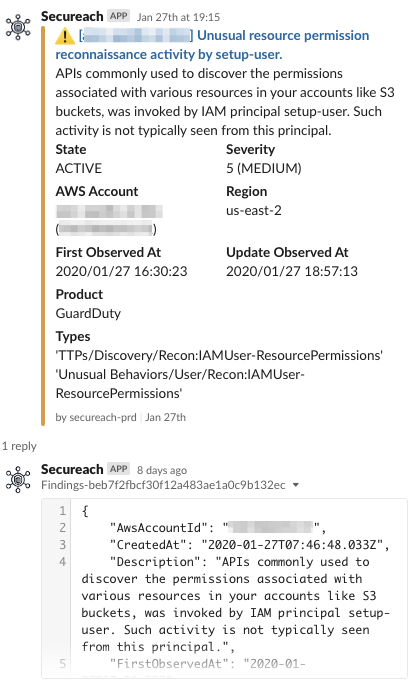
Slackメッセージは、対象アカウントや検出結果にて構成し、スレッドにてイベントのrawデータを閲覧可能としています。
AWS SecurityHubのSeverity Label (重要度ラベル) がHIGH又はMEDIUMの検出結果のみを通知対象とし、 LOWは除外しています。
また、通知機能には検出の除外フィルタを独自で実装しています。
Amazon GuardDutyは、機械学習や行動モデルを用いた脅威検出のため、通常業務における操作をMEDIUMで検出することがしばしば発生します。組織全体の検出結果を一元管理して追跡する場合は、大量の通知により健全な運用を行うことができません。
Amazon GuardDutyでは、抑制ルール によって自動アーカイブする機能が提供されていますが、 AWS SecurityHubにて集約した場合にはそれを利用することができません。
そのため、通知機能のAWS Lambdaの処理にて、findings (調査結果) のフィールド条件に合致した場合は通知を抑制する除外フィルタを提供しています。
Kibanaによる可視化
AWS SecurityHubのマルチアカウントかつマルチリージョンの検出結果を一元的にKibanaにて可視化しています。
可視化は、ガードレールの取り組みで共用するPlatformアカウントのAmazon Elasticsearch Serviceを利用しています。
Securityアカウントの全イベント保存用のS3バケットをレプリケーションして、PUTトリガーでVPC内のAWS Lambdaにてデータを加工して、Elasticsearchへ投入しています。
可視化したダッシュボードは以下の通りです。
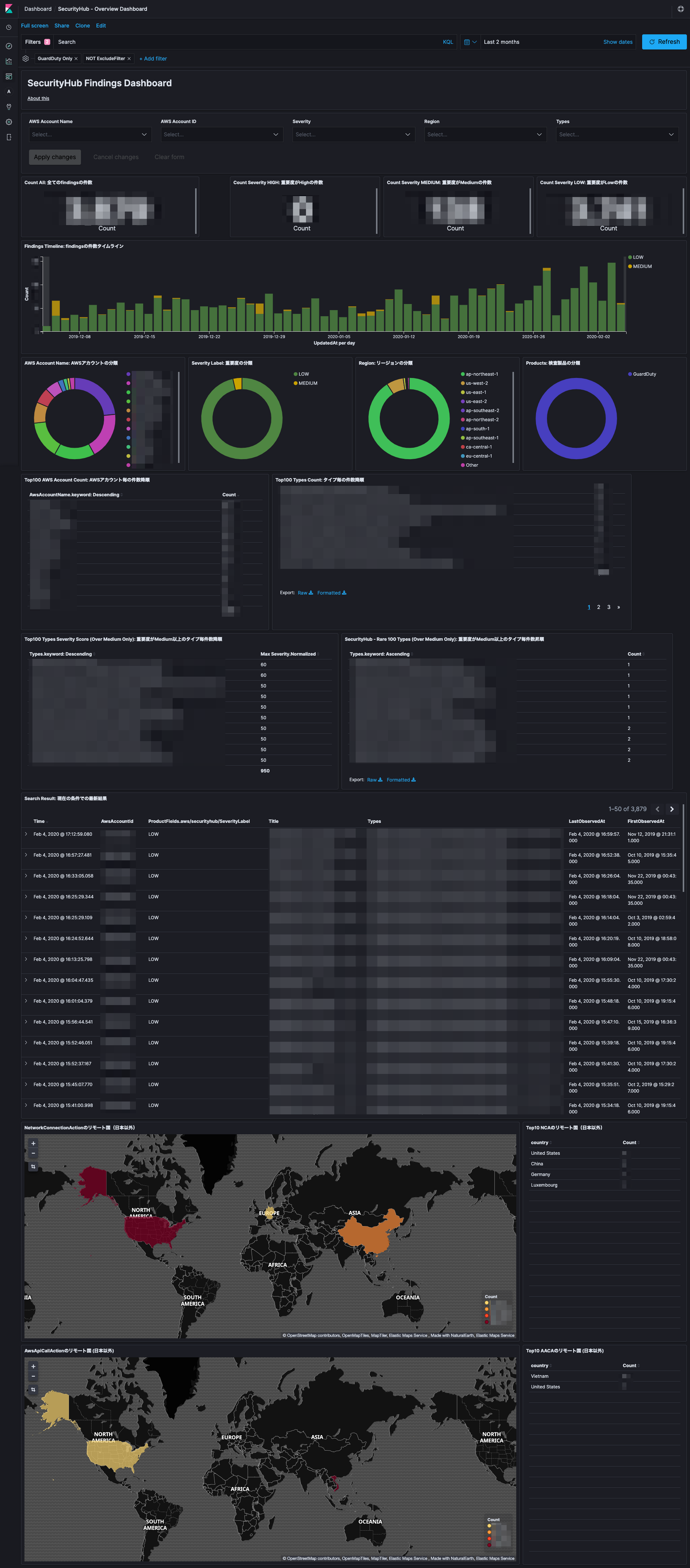
組織の全てのアカウントやリージョンで検出された検出結果の集約結果を表示し、結果タイプ毎やアカウント毎の発生状況などを確認できるようになっています。
考慮点
AWS SecurityHub経由の集約理由
Amazon GuardDutyでもマスター/メンバー構成を取ることで、マスターアカウントへ検出結果を集約することが可能ですが、AWS SecurityHubに集約して通知や可視化を行う手段を選択しています。
理由は、AWSのセキュリティ系のサービスでは、AWS SecurityHubにて AWS SecurityHub Findings Format (ASFF) と呼ばれる標準的な検出結果形式に自動変換して統合的に取り扱えるようにすることで、今後導入を拡大する場合に拡張しやすくするためです。
今回のガードレールには含まれていない Amazon Macie や Amazon Inspector 、IAM Access Analyzer などのAWSサービスを利用しているAWSアカウントの検出結果は既に自動でAWS SecurityHubへ連携されてダッシュボードでも閲覧できる状態となっています。
Amazon Elasticsearch Serviceの活用方法
Amazon Elasticsearch Service (以下、AES) のKibanaは、社内エンジニアへ参照権限で閲覧可能としています。
RBACを実現するためにAmazon Cognitoによる認証認可を行っています。
当社ではAESはVPC内部に立てるルールが設けられており、その構成を取るためには、こちら の構成を参考にしています。6
リバースプロキシ用のnginx及び、参照のみのユーザでログインするためのカスタムログインページを返すFlaskアプリケーション をECSサービスで運用しています。
効果
- 脅威検出時に早急にインシデントレスポンスが可能となり、 有事の際に被害を最小化 するプロセスを実現できました。
- 全てのAWSアカウントの安全性を確認 することができました。
- 各事業でも導入のリクエストが多く、横断組織で全社一斉に導入したことで 全社の対応工数を最適化して生産性にも寄与 しました。
コンプライアンス評価 (AWS Config)
AWS Config を利用して、AWSリソースの設定や関連性及び変更内容を記録し、規定のルールに基づいてAWSリソースを継続的に評価することで、セキュリティのリスクや信頼性を損なう可能性のある不適切な設定を特定して対処を促します。
AWSアカウントは、事業部の担当エンジニアにより適切に設計・運用されることが好ましいですが、全てのシステムで十分な対策を取ることは困難のため、不備や考慮漏れによる不適切な設定が影響した障害やインシデントは過去に度々発生していました。
そのため、はじめはチェックシートを導入してセルフチェックの評価にて対策してきましたが、チェックシートの運用は以下のような問題を抱えていました。
- 人による評価作業のため、誤りや見落としが存在
- 担当者のセルフチェックによる、評価対象・基準の揺れ
- 各担当者にて評価を行うため、多くの工数が必要
- 一定の間隔やタイミングで評価するため、その間の問題混入は把握不能
そこで、自動的な評価が可能な部分については、 AWS Configのルールを用いた継続的な評価によりルールに準拠しない場合は担当者へ通知し、適切に対応するプロセスを構築しました。
また、組織全体のAWSアカウントの評価結果を集約して可視化することで、状況把握に活用しています。
現在は、30個程度のマネージドルール 及び カスタムルールを採用しています。
実現方式
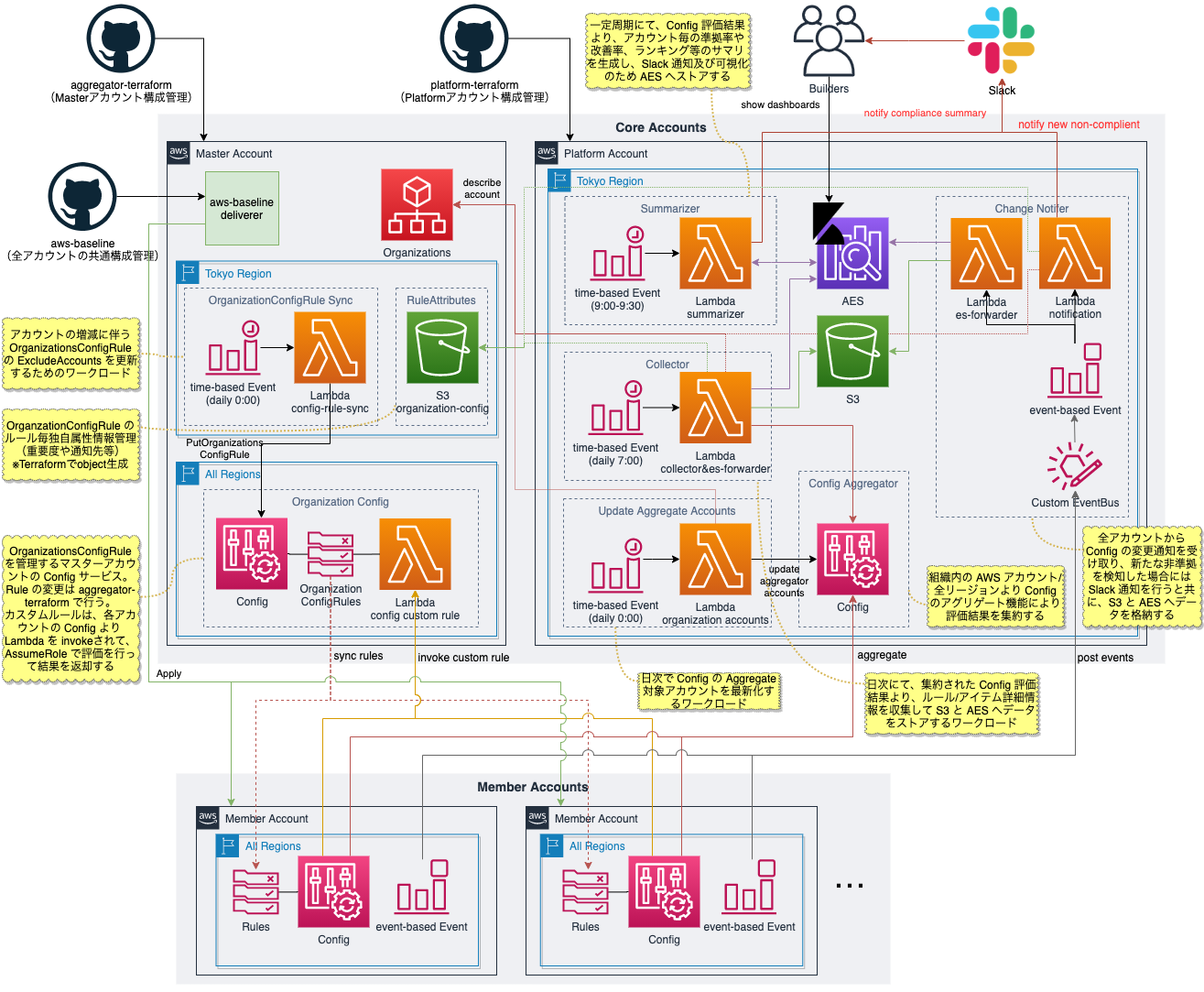
AWS Configの全体構成は以下の通りです。
組織のルール管理
組織全体のAWS Configのルールの管理は、マスターアカウントにてAWS OrganizationsのOrganization Config Ruleの機能を利用しています。
put-organization-config-rule で設定したルールは、組織のAWSアカウントのAWS Configへ自動的に反映されるため、ルールを一元的に管理する仕組みとなっています。
メンバーアカウントのAWS Config設定
Visional-Baselineにより、メンバーアカウントの全リージョンのAWS Config設定を行っています。
AWS Configの有効化、及びPlatformアカウントの東京リージョンをAWS Configのアグリゲート先として設定することで組織全体の評価結果を集約する設定を行います。
また、Amazon CloudWatch Eventsにて、 AWS ConfigのイベントをPlatformアカウントの東京リージョンのEvent Bridgeのイベントバスへ送信する設定を行うことで、全リージョンの評価のイベントも集約しています。
Kibanaによる可視化
AWS Configはリージョナルサービスのため、マルチリージョンの評価結果を一元的に可視化するため、アグリゲートアカウントに集約された各リージョンの結果をAESへ投入してKibanaにて可視化しています。
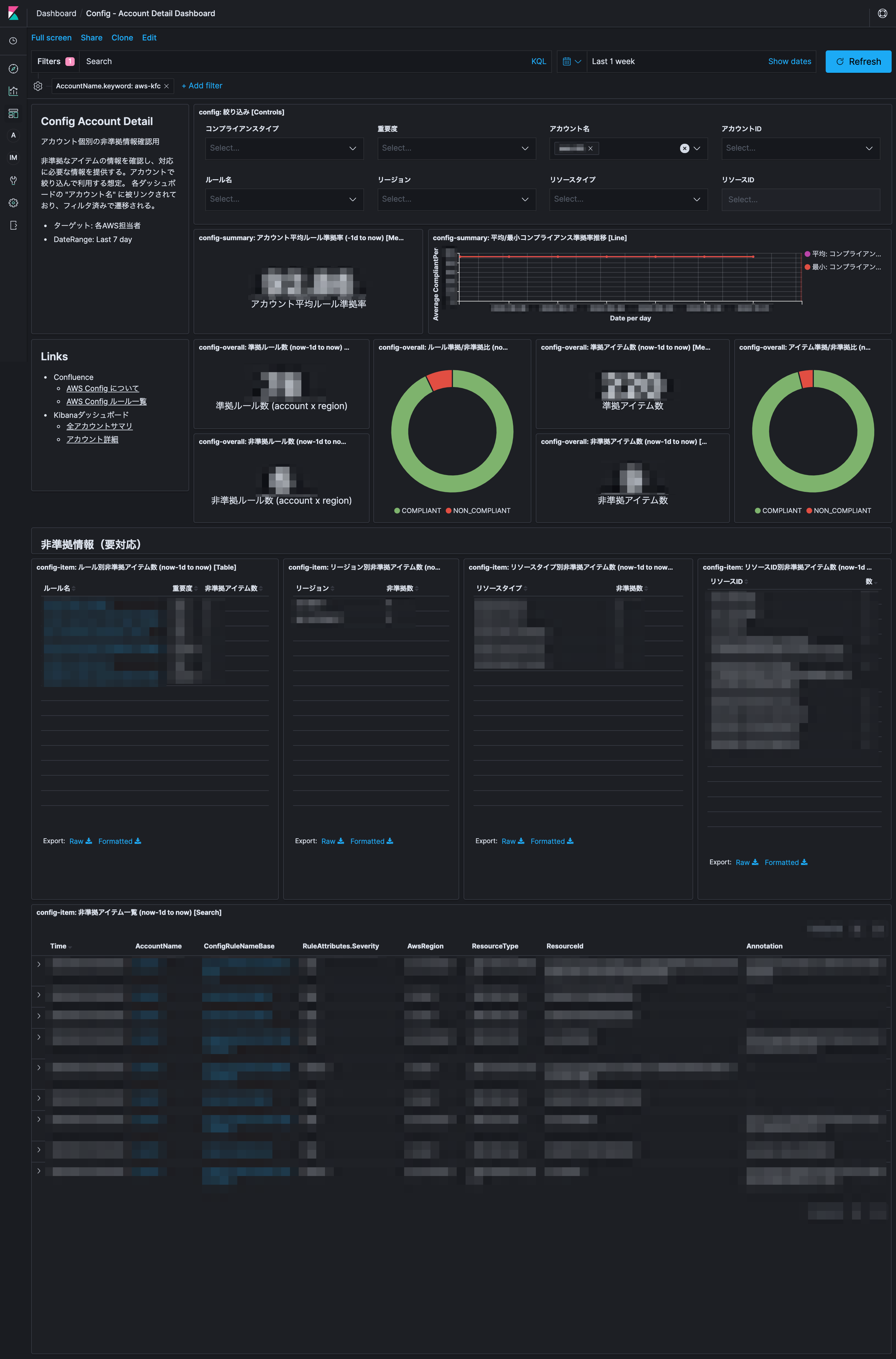
可視化したダッシュボードの一部は以下です。
| Overview Dashboard | Account Detail Dashboard |
|---|---|
| 組織全体のAWS Config評価結果 | アカウント毎の非準拠結果詳細 |
|
|
リアルタイム非準拠通知
メンバーアカウントにて自動的に評価結果がイベントとして、Platformアカウントのイベントバスへ送られています。
イベントバスのAWS Configのイベント発生をトリガーとしてAWS Lambdaを実行し、新規で非準拠となった場合には、 Slackにて以下のような通知を行っています。
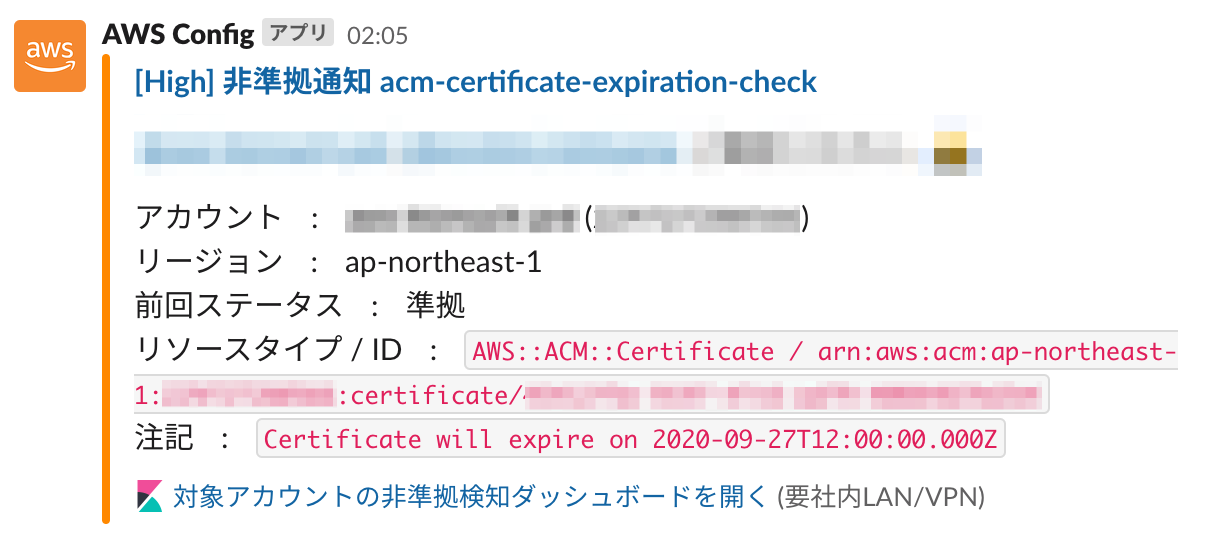
考慮点
マネージドルールの選定
AWS Configでは、 AWSより提供される マネージドルール と独自でAWS Lambdaにて評価を実装する カスタムルール が存在します。
AWS Configをはじめに導入する際には、どの評価ルールを採用するか検討が必要となります。
現在は、コンフォーマンスパック と呼ばれるコンプライアンス基準や業界ベンチマークに合わせてマネージドルールの組合せの単位で選定することも可能です。適合パックは、選定時に提供されていなかったため、個別のマネージドルールから選定を行っています。
選定においては、主要事業部のSREとセキュリティ部門と合同で、全社で共通して必ず守るべきルールを条件として選出しました。当時で100個程度のルールから30個程を選出しています。
また、現状ではカスタムルールもいくつか運用しています。
カスタムルールの管理
カスタムルールは独自の評価をAWS Lambdaにて実行してマスターアカウントに展開します。
カスタムルールは、特定のリソースタイプの設定変更でトリガーされて評価を実行するか、定期的にトリガーされて評価を実行するかを選択することができます。
各種アカウントのAWS Configより評価が実行されると、マスターアカウントのAWS Lambdaがルールやリソースの情報をインプットとして実行されます。評価結果をAWS Configの putEvaluations APIで送信します。
カスタムルールの関数を管理するものとして RDK (Rule Development Kit) がOSSで公開されています。 AWS Lambdaのいくつかのランタイムをサポートしたロジックのテンプレートが公開されているため、ロジック部分を参考にしています。
RDKはCompliance as Codeのためのクライアントとして動作するツールとなっており、直接展開やCloudFormation Templateを出力する機能を備えています。 私たちはTerraformによる一元化した構成管理を実現するため利用していませんが、そうでない場合は有益な選択肢となり得ます。
ルールの評価対象区分の管理
AWS ConfigのルールをOrganization Config Ruleにて組織全体へ展開する場合、通常では全てのアカウントへルールが適用されます。
しかし、当社ではルールの評価対象アカウントとして、Production用途のみに限定したいケースが存在しました。
例えば RDS インスタンスのバックアップ有効化 (db-instance-backup-enabled) のルールでは、 Production用途以外のアカウントの一部のRDSにおいては、コスト観点や用途次第でバックアップを必要としないケースも存在するため、組織全体で必須とする評価対象としてはProduction環境に限るといったものです。
そこで、AWSアカウントのタグに環境種別をアカウント開設時から設定しておき、そのタグに応じて put-organization-config-rule の excluded-accounts オプションを利用してルールの評価対象に含めるかどうかを制御しています。
ルールの重要度の管理
AWS Configで非準拠を検出した際には、担当者へSlackで通知して対応を促しますが、多くのルールの中でも実際に重要度は異なります。
例えば RDS スナップショットパブリック禁止 (rds-snapshots-public-prohibited) のルールで非準拠が発生した場合には、データ次第で個人情報流出に繋がる可能性もあり、特にリスクが高いため早急に状況を確認すべき状況です。
しかし、全てのルールの非準拠検出時に同じ緊急度で対応を必要とするものではなく、また、導入当初は既存のリソースや設定に対する非準拠件数が一定量存在するためルール毎の重要度を設定して高いものから優先的に対応すべき方針として定めることにしました。
重要度は3つに分類し設定しています。
- Critical : 即時対応を実施
- セキュリティ事故に直結する可能性があるもの
- クリティカルな異常に気付けない状況にあるもの
- AWS Rootアカウントに関連するもの
- High : 2-3営業日内対応を実施
- ログ出力設定でアカウントやVPC全体に関わるもの
- サービスの信頼性やセキュリティに関わる事故が発生する可能性のあるもの
- Medium : 計画的対応を実施
- 多層防御の1レイヤーで、セキュリティ事故に直結しないもの
- 漏洩リスクを含むが、公開範囲が限定的なもの
- ログ出力設定で局部のみに関わるもの
重要度の管理方式としては、 Organization Config Ruleはタグをサポートしていないため、付加情報を持たせることができません。
そこで、ルールの構成管理はTerraformを利用しているため、ルール毎に付加情報を定義し、それらをセットでJSONでS3へ出力し、可視化のためのElasticsearchへ投入する機能や通知の機能で読み込むことでルールの付加情報の利用を実現しています。
Config Rule List社内公開
Config Ruleをリスト化して社内公開することで、非準拠を検出した際に、担当者が検出理由やリスクを正しく理解できるようにしています。
また、対応方法に参考となるドキュメントや対応済みのTerraformのコードのリンクを載せることで、対応工数を減らす工夫を行っています。
リストの内容例
- ルール : 識別子 / 和名
- ルール説明 : ルールの評価内容、準拠及び 非準拠の条件
- 重要度 : Critical or High or Medium
- 評価対象区分 : 全アカウントor Productionアカウント限定
- トリガータイプ : 定期的or設定変更
- リスク : 非準拠時に発生するリスク
- 対応アクション : 準拠のための対応アクション (ドキュメントリンク/ Terraformへのリンク/ Tipsなど)
効果
- 従来のチェックシートで実施していた評価を一部 自動化したことで評価が効率化 されて、対応にかかる工数を削減することができました。
- 非準拠として検出された結果は ファクトに基くため問題箇所が明確で改善アクションに繋げやすい 仕組みを実現しました。
- 新たに検出された非準拠の結果を担当者へ通知することで、 発生するリスクを直ちに対処することが可能 となりました。
- 機械的な評価により これまで見過ごされていた望まれない設定を検出 し、 多くの改善点を可視化 できたことで改善に向けた動きを取れるようになりました。
ベストプラクティス評価 (Trusted Advisor)
AWS Trusted Advisor は、セキュリティ / フォールトトレランス / パフォーマンス / コストなどの観点でAWSのベストプラクティスに従っているかをチェックするサービスです。
AWS Configは利用者が定めたルールに従って評価を行いますが、 AWS Trusted Advisorは、AWSの推奨するチェックとなるため、AWSの最適な活用を支援するための位置付けで利用しています。
他のガードレールと同様に組織全体のAWSアカウントの結果集約と可視化、通知を実現しています。
実現方式
AWS Trusted Advisorの全体構成は以下の通りです。
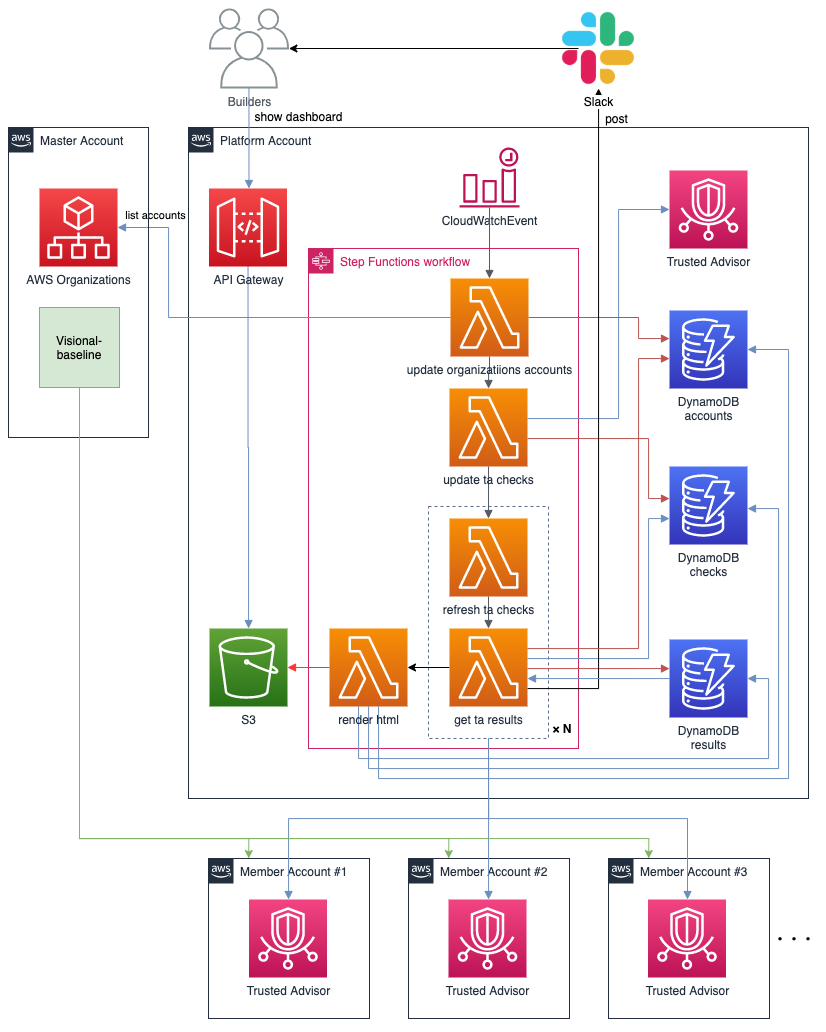
導入時点では、Organizations View の機能は提供されていなかったため、各AWSアカウントのAWS Trusted Advisorのチェック結果をStepFunctionsのワークフローを利用して、定期的にクローリングして収集する仕組みを取っています。
収集した結果はDynamoDBへ書き出し、全ての結果を取得後にテンプレートへ結果をレンダリングしたファイルをS3へPUTし、 API Gatewayを経由して開発者から閲覧します。
可視化ダッシュボード
可視化したダッシュボードは以下の通りです。

- アカウント一覧画面
- 各アカウントのカテゴリ毎error / warn / ok件数一覧化
- error / warnの件数は被リンクで対象のチェック結果画面に遷移
- チェック結果画面
- error / warnのみ閲覧可能で、チェック結果の詳細を一覧化
- チェック識別子は被リンクで対象のチェック内容画面に遷移
- チェック内容画面
- AWS Trusted Advisorのチェック項目 (チェック方法、アラート基準や推奨アクション) を一覧化
Slackへの通知
新たに検出された結果は 以下のようにSlackへ通知しています。

考慮点
AWS Trusted Advisorのチェック自動化
定期的にチェック結果をクロールするため、 メンバーアカウントでは定期的にチェックを実行する必要があります。
下記に記載の通り、個々のアカウントでAWS Trusted Advisorダッシュボード へアクセスがない場合は最長で1週間前のチェック結果 (ビジネスまたはエンタープライズサポートを利用時) となってしまうことが理由です。
AWSサポートFAQ より
- Trusted Advisorダッシュボードにアクセスすると、直近の24時間以内に更新されなかったチェックは、自動的に更新されます。
- ビジネスまたはエンタープライズサポートのお客様の場合、Trusted Advisorデータは毎週自動で更新されます。
最新の結果をダッシュボードで閲覧可能とするため、ワークフロー内で各メンバーアカウントの全てのチェック項目に対して RefreshTrustedAdvisorCheckRequest を送信しています。7
RefreshTrustedAdvisorCheckRequest 後のチェックは非同期処理となります。基本的に1時間以内にはチェックが行われることが確認できています。
そのため、ワークフローは現在3時間周期で実行し、3時間以内のAWS組織全体のチェック結果を可視化及び通知しています。
カスタムSlack通知メッセージ
他の発見的ガードレールも同様ですが、Slack通知は AWS Chatbot を利用することで、 AWSのマネージドサービスでのSlack通知を実現することが可能です。
しかし、 AWS Chatbotの通知メッセージは、AWSアカウントIDを含むためマルチアカウントに対応できますが、 AWSアカウントIDだけでは可視性が悪いため、 AWS Organizationsへ list-accounts の結果よりAWSアカウント名を逆引きしてカスタムフォーマットのメッセージへ含めて通知しています。
効果
- 可視化により組織のAWSアカウントのAWS Trusted Advisorのチェック結果の状況が把握できるようになりました。
- コストカテゴリへの対応を全社で推進したことで AWS全体の 約5% のコスト削減 を実現しました。
まとめ
AWSマルチアカウントの管理と運用の様々な課題に対して、AWS Organizationsやアカウントベースライン、ガードレールを導入することで解決を図りました。
AWS Organizationsやアカウントベースラインでは、効率的なマルチアカウントの管理を実現しました。
ガードレールでは、自動検出するセキュリティの脅威や望まない設定等へ適切に対処することで、適性なアカウントの運用の仕組みを実現しました。
これらのソリューションによって、従来トレードオフと考えられていた変化に柔軟かつ素早く対応する「アジリティ」と適切に統制された管理運用を行う「ガバナンス」を両立することができます。
変化の速い現代においてスピードを失わずにリスクを最小化することで、運用上の優秀性を向上させてビジネスを加速させることができると考えています。
今後の展開
今後もマルチアカウントを更に安全に効率的に運用していくために拡張・改良していきます。
- アカウントベンディングマシン (AVM) の確立
- AWSアカウント作成からセットアップまでの一貫したオートメーションの実現
- ガードレールの洗練・拡充
- 信頼性やパフォーマンス、フォールトトレランスの観点における評価の拡張
- AWS組織全体で未導入のAWSサービスや3rd Partyのソリューションを費用対効果を検証して導入の検討
- 検出結果に対する改善推進
- 検出された問題が放置されずに継続的な改善を支援するためのソリューションの提供と推進
また、今回の話ではAWSをターゲットとしていますが、 GCPにおいても同様の課題感を抱えているため、そちらの整備も進めていきます。
-
当社のマルチアカウント構成におけるCore Accountsは、少しコンウェイの法則に寄った状態となっています。特にPlatform Accountは部署の意味合いが強く出ており、役割に沿った切り口で適切に構成することをお勧めします。AWSのマルチアカウントのベストプラクティスの推奨アカウントが設計の参考となります。 ↩︎
-
社内では、 AWS-Baselineという名前で提供していますが、AWS公式のサービスの名称として誤認される恐れがあるため、社外向けにはVisional-Baselineという名称で取り扱っております。 ↩︎
-
現在はAWS StepFunctionsにて複数のエントリに対して動的並列処理を行うための Map のStateが提供されているため、AWS CodeBuildのステータスを個別に管理せずに実行から完了までの一連の手続きをStep Functionのワークフローで構築することでシンプルに実現できます。 ↩︎
-
2019年11月にStackSetsの構成ドリフト検出をサポートしています。未確認ですが、 Change Sets相当の変更点の確認についても確認できる可能性があります。 ↩︎ ↩︎
-
2020年4月にAWS Control Towerにて、既存の組織やアカウントを管理するをアップデートがリリースされました。東京リージョンは2020年10月現在もサポートされていません。 ↩︎
-
このnginxの設定ファイルではupstreamのエンドポイントをDNSキャッシュし続けるため、
resolverディレクティブのvalidオプションでttlを設定して、cognito-authやAESのエンドポイントのインスタンスの切り替わりを考慮する必要があります。 ↩︎ -
AWS Trusted Advisorを含むAWS Support APIを使用するには、ビジネスまたはエンタープライズのAWSのサポートプランが必要です。 ↩︎









