
はじめに
「HRMOS」では主にAWSを利用してサービスを運用しているのですが、 この度稼働中のサービスをオレゴンから東京にリージョン移行を行う という一大プロジェクトを遂行しました。 AWSも今や東京や大阪リージョンがあり、日本でサービスを展開するならばこれらを利用すると思われるのでリージョンまるごと移行する機会というのはなかなか出会えないのではないかと思います。
このプロジェクトは私たちSREチームが2020年11月ごろから約1年ほどかけて実践したもので、主になぜこのようなプロジェクトを実施する必要があったのか、どのように進めていったかを中心にご紹介します。 プロジェクトで実践した技術的な話を詳細に書いているととても長くなってしまうため、そちらはまた別の機会にご紹介したいと思います。
プロジェクト発足
「HRMOS」の従業員データベースシステムというのは「HRMOS」シリーズの人事データベースを担っています。今後はこの従業員データベースシステムをプラットフォームとして据え、「 HRMOS採用」「 HRMOSタレントマネジメント」など他シリーズとの連携を強化して「HRMOS」シリーズの体験を向上しようという方針で事業が進んでいます。
現在「HRMOS」シリーズの多くがAWSを利用していて、かつ東京リージョンで稼働しているのですが、従業員データベースシステムだけはオレゴンリージョンで環境が構築されていました。
そもそも従業員データベースシステムがなぜオレゴンリージョンでサービス展開したのかというところですが、事業立ち上げ当時は海外展開も視野にいれていたため日本に近いアメリカ西海岸のリージョンのうち、展開サービス数や速度が早いオレゴンを選んだという経緯がありました。立ち上げから数年経てば、事業やプロタクトを取り巻く環境も大きく変化するものです。「HRMOS」では、それらの変化に対し随時柔軟に適応しています。
このままでは連携の度に東京 - オレゴン間の通信が発生し、遅延が発生してしまいます。 実際に当時の「 HRMOSタレントマネジメント」の認証は内部的に従業員データベースシステムの認証を使うようになっているのですが、仕組み上複数回のAPIコールを必要とするため移行前のレイテンシは認証だけで 1秒弱 ととても遅いものでした。
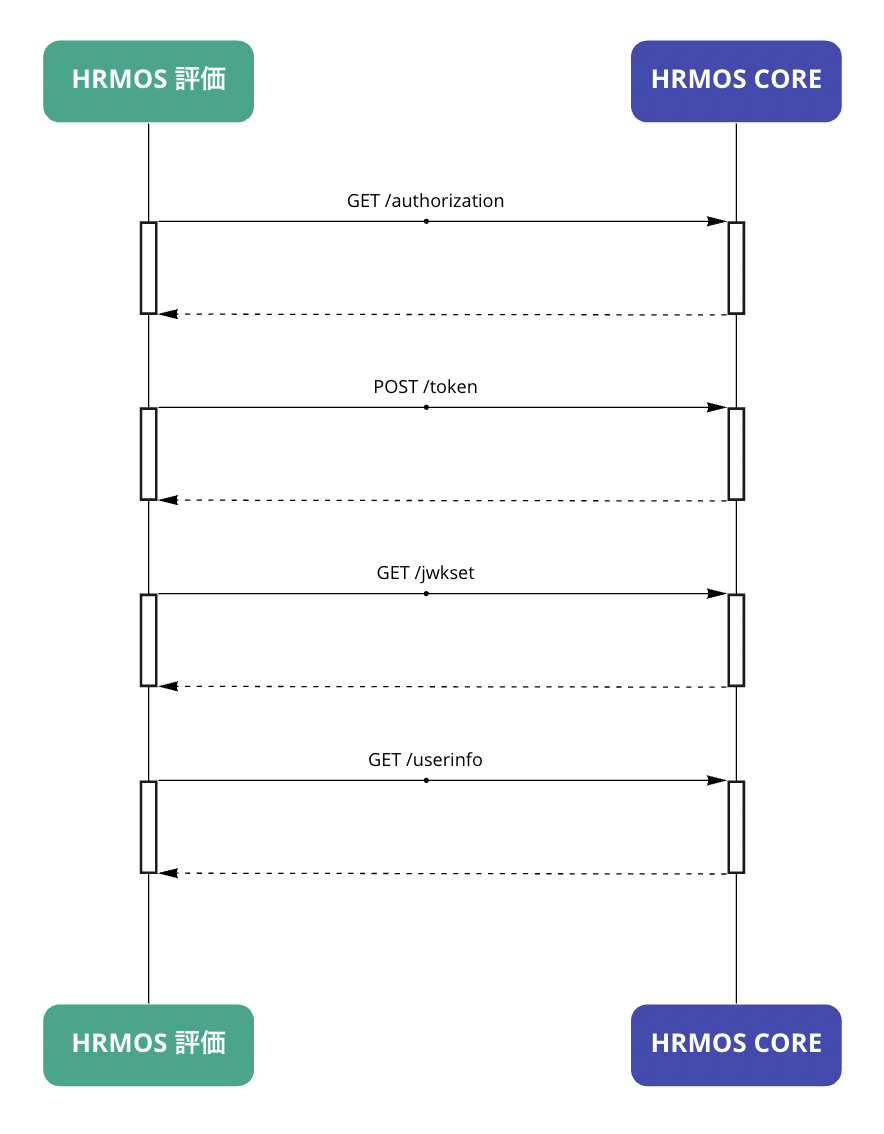
このように従業員データベースシステム - 他プロダクト間連携を強化していく未来において必ずレイテンシの問題に遭遇するだろうというのは容易に想像できます。そこでSREチーム主導で事業部のロードマップから逆算し連携が本格化する前に従業員データベースシステムのAWSリージョンを東京に移行するプロジェクトを遂行することになりました。
移行作業
移行の要件定義
まずは移行の要件を整理するところから始めました。 SRE ・ソフトウェアエンジニア・ PO (プロダクトオーナー)・ CS (カスタマーサクセス)など多くのステークホルダーと協議し、以下のような要件を満たすように移行を進めていくことになりました。
- 既存の機能開発は極力止めないこと
- データロストしないこと
- プロダクトが保持するデータ
- ログ
- 計測している各種メトリクス
- 移行に伴うユーザー影響を極力少なくすること
- メンテナンス回数・時間
- ユーザーアクション
チームメンバーはほとんどソフトウェアエンジニア出身のメンバーで、皆AWSの知識や経験をある程度は持っているものの、稼働中のサービスのリージョン移行を経験したことのあるメンバーはいませんでした。そのため、現時点のリソースをそれぞれどのように移行していくべきかをAWSのドキュメントやサポートケース、担当していただいているソリューションアーキテクトの方のアドバイスを元に手探りでメンバー全員で考えていきました。
Cognitoユーザープールの移行
RDSやS3などに保持しているデータなどはレプリケーションなどを利用して比較的簡単に移行することができるのですが、 Cognitoユーザープールの移行は一筋縄ではいかなかったので少々ピックアップします。
従業員データベースシステムではAWS Cognitoを利用してユーザーの認証を行っていて、ユーザー情報はすべてCognitoユーザープールに保持しているのですが、これらのユーザーデータおよびパスワードを一括で移行するような方法はAWSから提供されておらず、 Lambdaを利用した移行方法で移行していくことになりました。
移行Lambdaは移行先のCognitoにユーザーが存在しない状態で、以下の操作を行うことで実行されます。
- サインインを行う
- パスワード再設定を行う
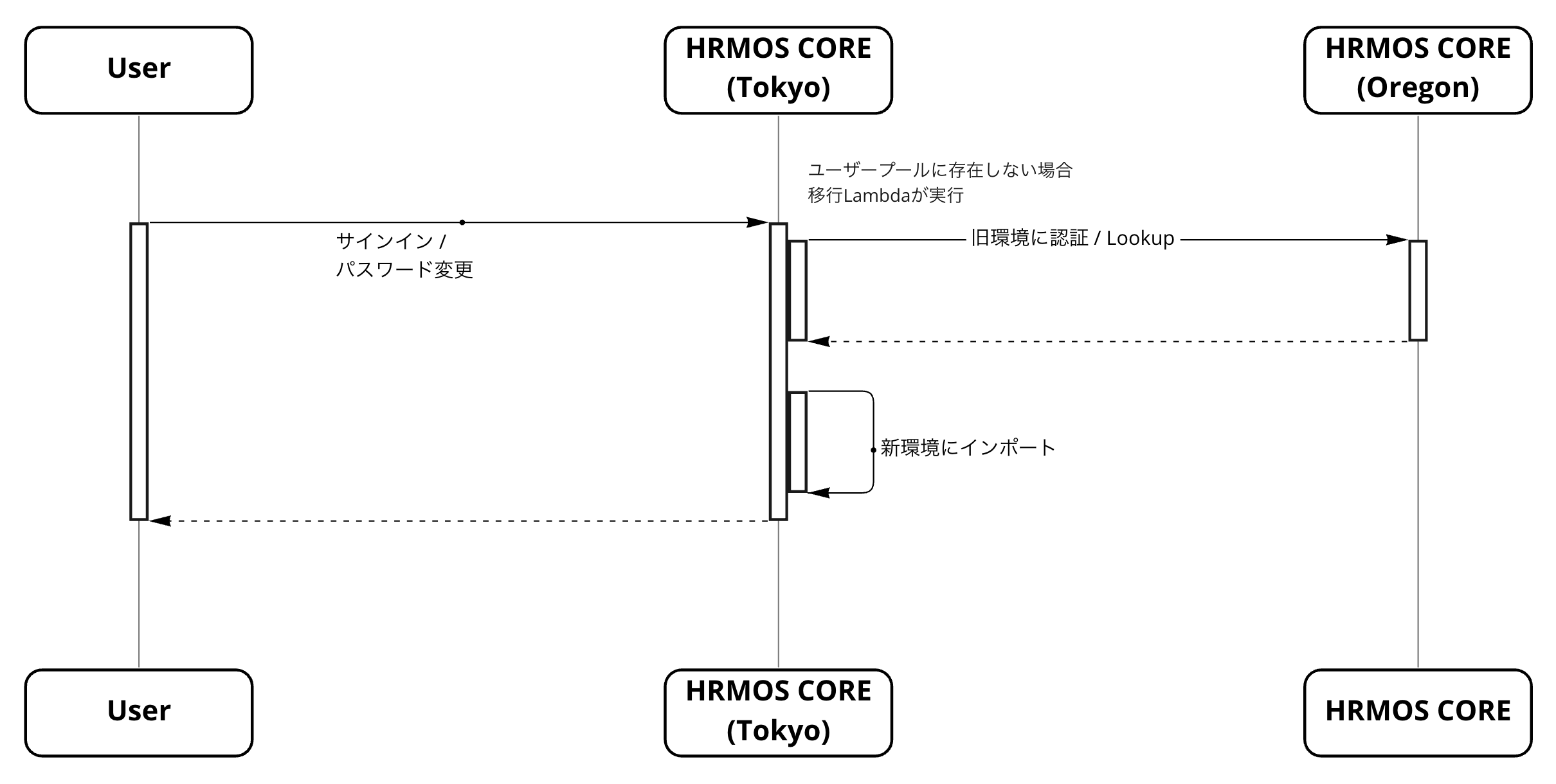
つまりCognitoユーザープールの移行はユーザー操作が伴うため、移行Lambdaを設定してからしばらくの間 旧ユーザープールを残したまますべてのユーザーの移行が完了するまで待つ 必要があります。とはいえ、長期間ログインしないユーザーも一定数存在するため、従業員データベースシステムの移行ではログインUU数の実績から約3ヶ月で90%以上のユーザーはログインするだろうという予測のもと、3ヶ月程度様子を見てその後一括で移行することになりました。
一括移行はアプリケーションの状態とも整合を取る必要があったため、アプリケーションの開発チームと協力しながら進めました。具体的な方法としては旧Cognitoユーザープールに残っている未移行ユーザーを対象にパスワードを除くユーザーデータのみを新Cognitoユーザープールに移行するバッチを別途作成し、パスワード再設定を促すメールを送信するというものです。
実際にユーザー移行を開始すると、 Cognitoユーザーの移行とアプリケーションの状態の不整合が発生してしまうケースも少なからずあり、その際には適宜対応が必要でした。また、ユーザー移行の進捗が想定より遅く、予定の3ヶ月を過ぎても70%程度でした。
ユーザーの一括移行にはパスワード再設定というユーザーアクションが発生してしまうため、可能な限り移行Lambdaでの移行を待ちたかったのですが、不整合によるユーザー影響や対応コストなども考慮して、当初の計画通り3ヶ月で一括移行を実施するという判断になりました。
ちなみに移行LambdaではCLIベースで取得できる情報であれば移行が可能であるため、 MFAの設定なども移行可能となっています。ただし、当然ながら CognitoのSMSを利用していることが条件 であり、 Authenticatorなど外部アプリを利用したMFAはCognitoの管轄外であるため移行できません。 従業員データベースシステムでもSMSやアプリを利用したMFA機能を提供しているのですが、アプリ利用のMFAに関しては移行後にユーザーに再設定をお願いすることになりました。
移行準備とテスト・当日作業・移行後
移行前には東京リージョンでドメインを変更した新環境を稼働させ、事前にリグレッションテストを実施しておくことで、移行当日は必要なデータ移行とドメインの切り替え、軽い動作確認のみ実施すればよい状態にし、メンテナンス時間が短くなるようにしました。機能開発についても移行前に大きな変更が入らないよう調整してもらい、仮に移行後に何か不具合があった場合でも原因の切り分けが容易になるようにしました。
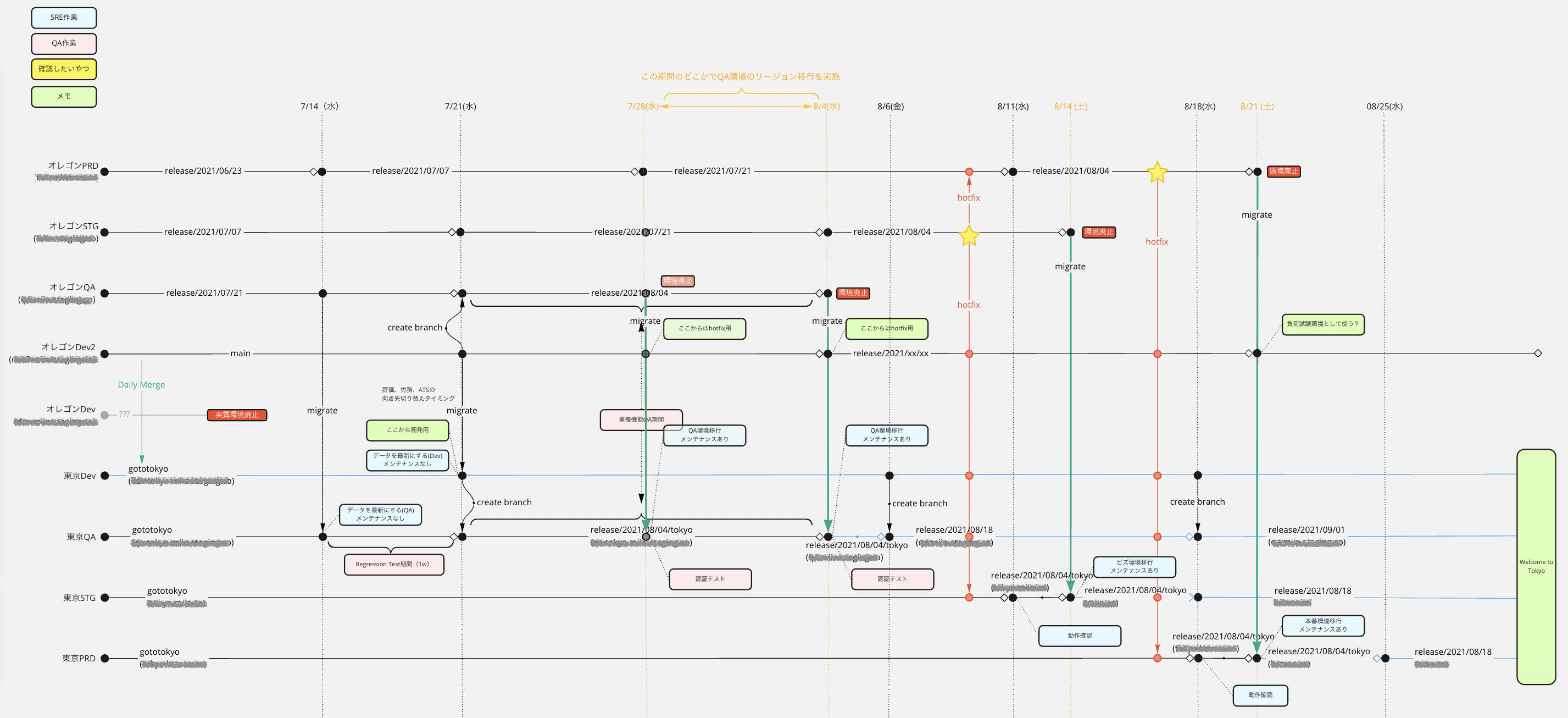
メンテナンス当日に必要になる作業においても 事前準備・当日作業・切り戻し手順 に分け、各作業にかかる予測時間と具体的な作業手順を記載しておき、チームメンバー全員で手順の間違いはないか、計画している時間内に終わるかということを確認し、当日の作業者でなくともいざとなれば チームメンバー全員が作業できるような属人性の低い状態にすること を意識しました。こうすることで、当日作業者の突然のトラブルや移行時のトラブルにも素早く自発的に動くことができると考えます。
実際には移行当日はSREと関係プロダクトのエンジニア数名が参加し、 POやCSの方には緊急時に連絡がつくように待機してもらいましたが、大きなトラブルもほぼ想定通りに移行を完了させることができ、ほっとしました。
さて、移行の結果ですが、前述した認証のレイテンシは1秒弱かかっていましたが、移行後は 200〜300 ms まで短縮され、なんと約3倍の速度向上 を確認できました。未来に対する改善なので現時点で体感的にそこまで大きな効果は感じられませんが、今後高頻度で従業員データベースシステム - 他プロダクト間連携が行われるようになった際に体感で3倍遅いということ、そしてそれが発覚してからあわてて改善しなければいけなくなることを想像すると、やはり事前に実施しておくべき案件だったと改めて思います。
SRE観点で振り返る
2020年11月ごろはまだSREチームとして活動を始めたばかりで、あまりSRE的な観点を意識していませんでしたが、今当時の要件を振り返るならどのようなアプローチをするだろうかということを考えてみました。
SLOに基づいて計画し、結果を評価する
SREの原則に SLI/SLO というものがありますが、これはプロダクトが目指すサービスレベルを指標化し( SLI )、内部的あるいは外部的な目標値( SLO )を定義するものです。 SLI/SLOは客観的なメトリクスとしてプロダクト関係者が認知でき、その目標値に対して共通的な認識を持つことで エンジニアの枠を超えてサービスの状態や許容できる信頼性について会話すること を手助けしてくれます。
今回のケースだと「メンテナンスの回数・時間」という要件に対して活用できるでしょう。 当時はSLI/SLOの定義がまだなかったこともあり、「極力少なくする・短くする」というような努力目標に近いものしか設定できませんでした。 SLI/SLOがしっかり定義・運用できている場合、定量的な目標値を設定することができます。
一般的な定義に当てはめた場合、例えば、 SLIに可用性としてシステムへのリクエスト成功率を、 SLOに 30日間に99.9% を設定すると、単純計算で 約43分間 サービスを停止することができます。 BtoBなサービスであれば夜間や休日の方が利用頻度が下がることもあるでしょうから、夜間/休日ならさらに長くサービスの停止が可能かもしれません。
このように客観的かつ定量的な目標値を設定できることで、必要以上に早く完了させるために多くのコストを払う選択をしてしまったり、平日の夜間など利用頻度が低い時間帯での作業で十分なところを休日対応としてしまうなど、過度な対応コストを支払う選択を避けることができます。 そしてなにより、エンジニア以外の多くのステークホルダーに対して行うこれらの交渉事がよりスムーズに進むでしょう。
おわりに
以上、従業員データベースシステムのリージョン移行プロジェクトについて、抜粋して紹介させていただきました。 顕在化していない課題に対して取り組むというのは大きな意思と関係者全員の理解が必要で、特に変更コストが高いインフラ領域だと半年や1年先を見越して動いていく必要があるため、プロダクトの状態を適切に可視化しておき、事業のロードマップと連動していくことが大切だと思います。
今回の記事ではあまりSREには触れませんでしたが、「HRMOS」のSREはプロダクトの信頼性を向上・維持していき、高いユーザー価値を届けるために日々SREingを実践しています。今回紹介できなかったより細かい技術的な内容や、SREチームの組織的な話なども今後ご紹介していければと思います。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










