
はじめに
採用管理システム「HRMOS採用」は、企業の採用活動の効率化や採用データの可視化・分析により、採用決定数の向上につなげることができるクラウドサービスです。
この度、HRMOS採用のSREチームでは、技術負債解消のためにログ運用基盤のDatadog Logsへの移行を行いました。その取り組み内容を紹介します。
計画以前のログ基盤構成と課題
サービス開始以降、ログの運用管理はEFKスタック1で構築された基盤を利用していました。サービスが成長にするにつれログ増加などの環境変化も伴い、時間経過とともに様々な課題が生まれてきました。
なお、トラフィックの規模感としては数百万件/日(平日)、数十億件/月ほどログ件数があります。
移行以前のログ基盤の構成イメージを以下に示します。
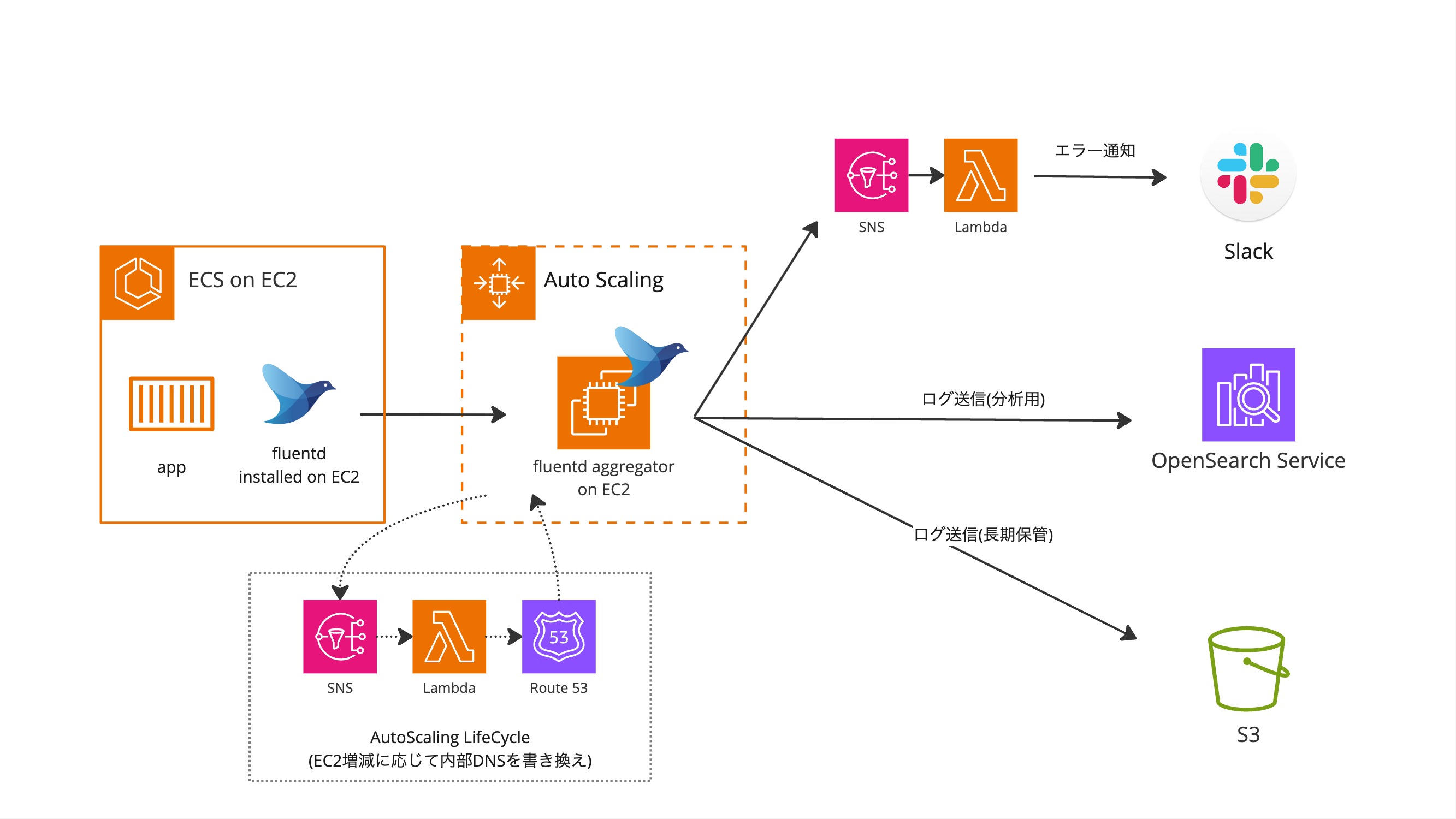
課題1インフラの運用負荷が高い
OpenSearchの運用負荷
Amazon OpenSearch Service(以下、OpenSearch)のストレージサイズの調整が度々発生していました。サイズ変更にはインスタンスの総入れ替え(blue/greenデプロイ)が必要2で1回の作業に多くの時間を要していました。また、セキュリティパッチやEoL対応で定期的にアップデート作業も必要でした。
Fluentd Aggregatorの運用負荷
Slack, OpenSearch, Amazon S3(以下、S3)の3つの転送先に振り分ける構成により設定が複雑化していました。初期構築に関わったメンバーもチームから居なくなっており、変更のために既存設定を一から読み込む必要があり非効率でした。また、Amazon EC2(以下、EC2)のOS・パッケージのアップデート作業も定期的に必要でした。
課題2クラウドコストの割高感
コスト(主にOpenSearchとEC2の費用)が全体の約13%を占めており、担っている役割に対して割高な印象がありました。
課題3利便性が低い
エラーログの通知を1件ごとにSlack通知する仕組みで、エラーが大量発生した場合にレートリミットで送信できなかったり、アクションが必要なログが埋もれる可能性がありました。
その他、Slack通知にエラー箇所を示すKibana画面への直リンクを埋め込むのが難しく、利用していたライセンスではログのエクスポートもできず、不便に感じることが多くありました。
ログ基盤移行を決断した理由
上述した課題を抱え運用を続けてきましたが、DBのアップグレード対応など高優先度の対応が完了したことや、アプリケーションコンテナのAWS Fargate(以下、Fargate)化に伴いログ設定の変更が必要だったこともあり、23年の5月ごろにログ基盤移行対応の本格的な計画を始めました。
新環境の構成と要件を整理してドキュメント化
最初のステップとして設計・構築に移る前に上述した課題や新基盤に盛り込む要件や構成イメージをドキュメント化しました。 なお、移行先のサービス選定については、元々モニタリング監視用に利用していたことや他部署での利用もあったDatadog Logsが候補となり、以下の観点から採用となりました。
- マネージドサービスあり、インフラ基盤のメンテナンスが不要(インフラ運用の課題が解消できそう)
- 既存構成と比較して利用コストが下回る試算になった
- 既存の監視運用と相性がよい
以下は新基盤の構成イメージになります。3
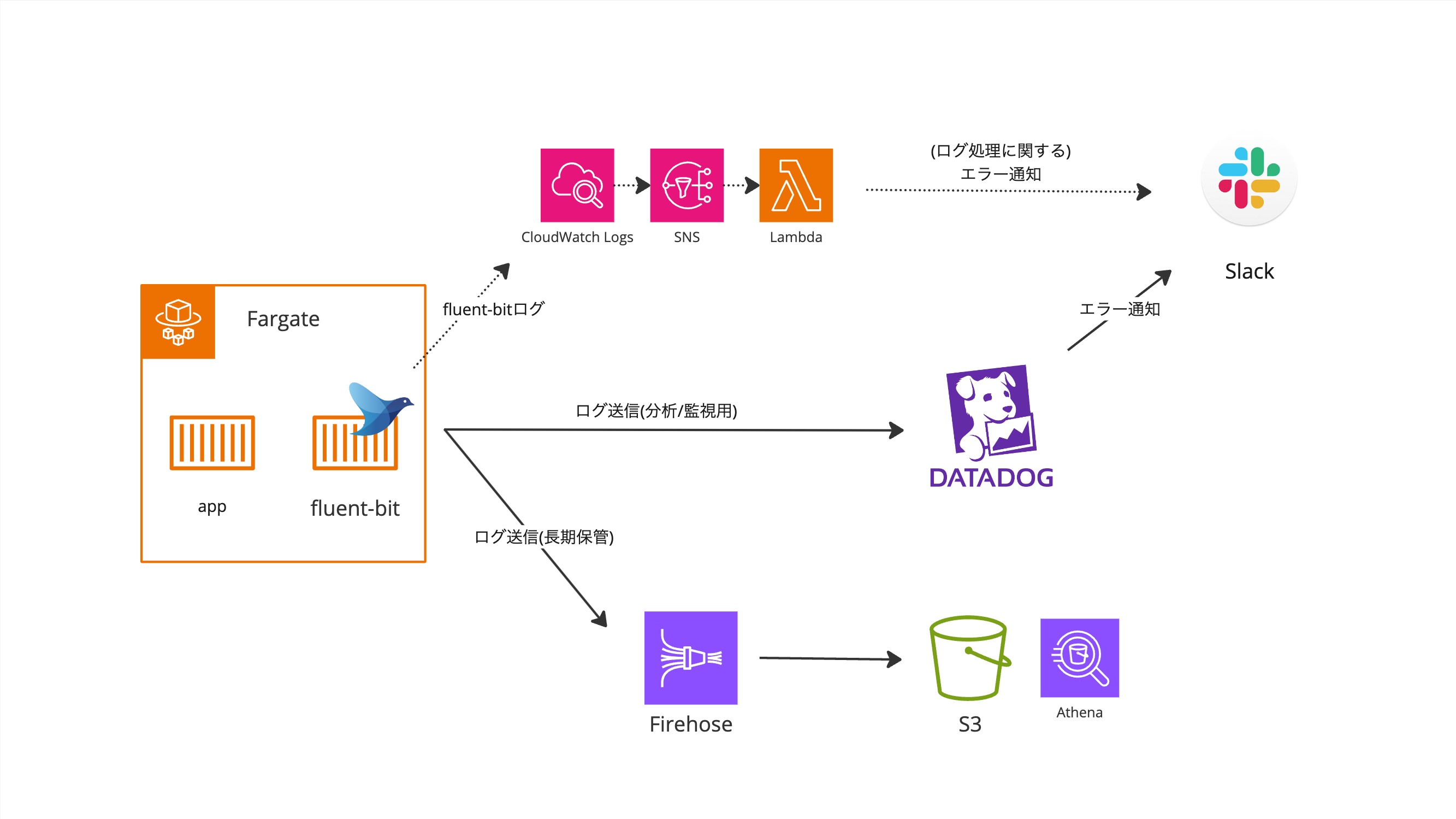
以下、主な変更内容と考慮した点です。
- アプリケーションの実行基盤をECSonEC2からFargateへ移行し、DatadogLogsへの送信は、APPコンテナのサイドカー(fluent-bit)から直接送信することにした。
- Datadogで障害が起きてもログが欠損することのないように、Firehose経由でS3にも送信するようにした
- S3に保管されたログも表示・検索できるようにAthenaのtableを作成したり、日付やコンテナ名で動的パーティショニングがされるようにS3 Prefixを設計しPartition Projectionを設定した
- fluent-bitのエラーは、Datadog経由で通知するとDatadogの障害時に通知されないことが想像できたため、監視経路を分離することにした
安全にリリースするための移行計画
要件と設計を固めた後は、実装と並行して安全にリリースするための移行計画を考えました。ポイントを2つ紹介します。
1. 段階的なリリース
HRMOS採用では従来よりアプリケーションをある程度まとまった機能群でモジュール分割するアーキテクチャを採用しています。そのモジュールはECS Serviceと対になっており、モジュール単位でデプロイが可能な構成でした。 今回の対応はFargate移行とログ送信先変更という2つの大きな変更を行うもので、できる限り1回のリリース範囲を小さくしたいという目的があり、このモジュール単位で段階的にリリースしていくことを考えました。
リリース順序の考え方
どの順番でリリースしていくかは各モジュールの特性に応じて以下の考えで決めました。
- 初回リリース: 社内向け管理機能を担うモジュール
- 社内のサポートメンバーが利用しており、リリース失敗により停止しても直接お客様への影響がない
- 2回目: レポート機能を担うモジュール
- 比較的リクエストが少なく、提供機能の特性上、万が一問題が起きても日々の採用業務へ影響が少ないと考えられる
- 3回目以降:
- ある程度、類似性のある機能を複数個を1つの単位としてまとめてリリースしていった
2. 段階的なトラフィック切替え
さらに、各リリースで不測の自体があっても影響範囲を少なくできる(異常に早く気づき早く解消できる)ように、ALBの加重ターゲットグループを利用した段階的なトラフィック切替えを行いました。
具体的な手順
事前に新規コンテナ用のターゲットグループを作成しておき、当日まず10%のトラフィックを新コンテナに流し、次に30%、70%、最終的に100%といった具合に徐々に増加させていく方法を取りました。 ちなみに、この4段階はリリース工程の途中からしたもので、当初は10%から100%と2段階でリリースしていました。(「移行する過程で直面した課題」に経緯を記載)
結果
一度、切り戻しが発生したリリース(「移行する過程で直面した課題」で詳細記載)がありましたが、ターゲットグループを切り戻すことで迅速にロールバックすることができ、影響を最小限におさえることができました。それ以外は問題なくリリースすることができ、安全にリリースをするという目的は達成できたと思っています。
移行する過程で直面した課題
上記のようにリリースを進めていきましたが、すべて順調に進んだ訳ではなく一度切り戻しをしたケースもありました。以下、その詳細について触れたいと思います。
3回目のリリース後に起きた事象
3回目のリリースを行った直後、ログ転送が失敗する事象が発生しました。 新環境の構成で述べたように、S3への転送にKinesis Firehoseを利用していましたが、Fluent-bitコンテナからFirehoseへの送信エラーが発生したのが事の発端でした。
エラー発生の要因と行動分析
3回目のリリースは、一番アクセスが多い(=ログ量が多い)モジュールを対象にしたリリースでしたが、Firehoseのサービスクォータ(Delivery Stream Throughput)によるスロットリングが発生したのが直接の原因でした。
サービスクォータの存在は事前に把握していましたが、スループットの見積もりに関しては、今回の移行に併せてログのフォーマット変更等も行っており事前に転送量の見積もりが難しかったため、段階リリースをしていく中で実測した流量から判断しようとしていました。そして、2回目をリリースした時点でクォータの1%も満たないログ量だったため問題ないだろうと判断をしていました。ここでモジュールごとのログ量から相対的に評価していれば、事前に気づくことができたかもしれません。
エラーの対処方法と再発防止アクション
サービスクォータに関しては、残りモジュールのログ流量を見越した緩和申請を行いました。 また、今後の再発防止として以下のアクションを行いました。
- 再発時にすぐ対処できるようにクォータ申請方法を手順化
- リリース時のトラフィック流量のステップを細分化して各ステップで確認する指標を明確にした(2段階だったのを4段階とした)
学び
今回の課題からデータ流量の見積もりの重要性を再認識しました。一方でLBの切り替えにより迅速にロールバックできたことは影響を最小化できたという意味でよかったことだと思います。
今回、クォータ上限に達したのはデータストリームのスループット(Delivery Stream Throughput)でしたが、デフォルトの上限値は状況によっては足らない可能性があるので、Firehoseの利用される方は気にされたほうがいいかもしれません。
DatadogLogs移行後の効果と変化
無事移行を終え課題は解消されたのか、その後の効果や変化について紹介します。
課題1インフラの運用負荷
Before
- ストレージサイズ変更や定期アップデートなど、長時間に及ぶ作業が度々発生していた
- Fluentd Aggregatorの振り分け設定が複雑で認知コストや変更コストが高かった
After
- ストレージ管理やサーバのアップデートといったインフラ管理が不要になった
- 現時点では、Datadog移行によって新たに生まれた運用業務はない
- 将来的にDatadog-agentのアップデートが発生する可能性はあるが、以前の管理コストに比べて大幅に削減できた
- fluendの設定がシンプルになり、認知負荷が軽減された
- 設定変更もコンテナイメージの差し替えやTerraformの変更によって対応できるため、作業工数や変更リスクも低くなった
課題2クラウドコストの割高感
Before
- ログ基盤のクラウドコストが全体コストの約13%を占めており割高な印象だった
After
-
計画当初と移行後の請求費の単純比較で、約9%の削減、ログ増加の影響を差し引くと約17%の削減となった。 (OpenSearch, EC2のコストとDatadogLogsの利用料の対比)
これはインフラ運用の改善による業務工数の削減も達成できていることを考えると、大幅にコスト効果があったと言えます。
課題3利便性が低い
Before
- エラーが大量発生した場合、通知の取りこぼしや他ログの見逃しが起きる可能性があった
- Slack通知やログエクスポートなどの細々とした機能の不足があった
After
- ログエクスポートはDatadogに標準で搭載されていた機能で、Slack通知もDatadogの変数などを使って容易に実現することができた
- エラー監視については、Error Tracking for Logsを利用することで大量発生時の課題が解消されただけでなく、様々なメリットがあった
Error Tracking for Logsは、最近登場した機能であり情報が少なく実装時に苦労した点も合わせて、少し機能紹介をします。
Error Tracking for Logsについて
Error Tracking for Logs はエラーログの検出や対応を効率化するものです。APMやRUMにもError Trackingと呼ばれる機能がありますが、そのLogs版と捉えています。
Datadog側で同種エラーを一つのIssueとしてまとめてくれるので、以下のようなメリットがあります。
- 同類のエラーが大量発生しても通知が大量に発生しない
- Issue単位でミュートやIgore等のステータス管理ができる
- 通知設定(monitor)が簡素化できる。
- issue.idでグルーピングできるため、以下のように “Issue単位で直近◯分間に◯件以上起きたら通知” のようなクエリが書ける
|
|
なお、ErrorTracking上にIssueとして表示させるには、error.stack, error.message, error.kind という3つのログ属性をすべて含める必要があります。
HRMOS採用のアプリケーションはScalaで書かれており、Pipeline LibraryにあるJava用のPipelineを通すことで通常のExceptionは上記3つの属性値にうまくパースされました。しかし、ログ出力の実装によってはExceptionがないパターンもありIssueとして認識されないケースがありました。
色々検討した結果、Errorレベルで error.stack がない場合は、“no stack trace” のような固定文字を挿入するようPipeline処理を組みました。
メンバーの入れ替わりによる環境変化
約半年以上に及ぶ長期間のプロジェクトで、移行期間中にはメンバーの入れ替わりという環境変化もありました。
対応開始時は3人の担当メンバーで始めたプロジェクトでしたが、後半は一人が育休に入り2名体制となりました。 単純にこなせる業務量が減ること以外に、以下のような懸念があがりました。
- 割り込みタスク(インシデント、他チームからの依頼等)に影響を受けやすくなって計画が滞るのでは
- 少人数なことで困った時に議論の幅が広がらない、間違った方向にいったときに気付けないのでは
上記に対して行った工夫としては、以下を実施しました。
- チームのタスクを整理して他チームに移譲可能なものは移譲して定型タスクの量や依頼タスクの頻度を減らした
- 週一で行っている振り返りの場にチーム外の人にも参加してもらって違う意見をもらう
実際にはプロジェクトの山場である主要モジュールのリリースが完了していたこともあり、品質の低下を感じたり判断に迷うケースは少なかったです。反対にお互いやってることがクリアに把握できており、共有に割く時間が減ったといったメリットなどもありました。
最後に
長期間のプロジェクトでしたが、結果を振り返ると、重大なミス(切り戻しは一度ありましたが)もなく、概ね狙い通りに課題解決ができたと思っています。やり残したことや、今後やりたいこともあるので、これからも改善の取り組みを続け、より良いSREの実践を続けていきたいと思います。
HRMOSでは採用管理業務の効率化と改善を支援するための取り組みを行なっています。少しでも興味をお持ちいただいた方は、ぜひご連絡ください!
最後までお読みいただきありがとうございました。
-
Elasticsearch、Fluentd、Kibanaを使ったログの収集・解析・可視化のためのプラットフォーム ↩︎
-
現在は機能アップデートによりblue/greenデプロイなしで変更可能です。 Amazon OpenSearch Serviceでブルー/グリーンデプロイを使用しないクラスターボリュームの更新が可能に | aws.amazon.com ↩︎
-
AWS Batch等、他のログ経路もありますが主要部分のみに簡略化しています ↩︎
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










