基盤システムの保守運用では、常に会社の変容に対応していくことが求められます。
ビジネスの価値を高めることはもちろん、システムとしての可用性や利用方法の適正性など、求められるレベルは年々高まっていきます。
「ビズリーチ」、「キャリトレ」、「HRMOS」、「ビズリーチ・キャンパス」の4事業部を支えながら、私たちSalesforce運用チームが、どのようにこれらの課題と向き合ったのかご紹介したいと思います。
あるべきユーザ権限と実際の運用の適正性
私たちは、主にプロダクトの営業活動や業務効率化を促進させるために、Salesforceのユーザ、すなわち社内の仲間をサポートする立場にあります。
仕様についての質問から、アカウント作成・権限付与などの定型業務、エンハンス開発のご相談まで、Salesforceおよび連携システムに関わるありとあらゆるお問合せにチームで対応しています。
その際、いつも気をつけているのが”あるべき正しい運用”です。
効率を追求するあまりに、ともすると見落としがちですが、必要な適切な権限が割り振られていること、その業務のあり方が正しいことを守り続けることを大切にしています。
システム制限の限界とデータ量増加に伴う性能低下への懸念
私たちが主に担当しているSalesforceは、利用を開始してから10年以上の時が経っています。
当初は社内の要望に次々と応え、運用できていたカスタマイズ機能の数々も、求められるビジネススピードの加速とデータの肥大化に伴って、各所にほころびが出てきつつあります。
リスクを事前に検知し、障害を未然に防ぐ仕組みづくりは私たちの課題のひとつでした。
リスク検知する仕組みへの取り組み
上記課題への対応として、SalesforceのAPIを利用して、私たちは様々な監視バッチを作成しました。
- ストレージ残量やメール送信残量をSlack通知
- 外部システム連携が正常に行われているかのチェック
- Bulk APIによるデータ投入の失敗を検知し、欠落したデータを自動で復旧
- 権限設定変更と変更したユーザを監視
などなど。
こうした取り組みによって監視の有用性が見えてきた頃、ちょうどコーポレートガバナンスの観点から、イベントモニタリングが導入されました。
イベントモニタリング利用の試み
イベントモニタリングは、Salesforce Shieldという有償機能のうちのひとつです。
ユーザのレポートやダッシュボードへの詳細ログや、アクセス状況の可視化(Analytics)、データアクセス時のアラートによる検知などを行うことが可能です。

導入のきっかけとして着目した機能
当初着目していた機能は、ログ分析機能およびリアルタイム監視機能です。
しかしこれはまさに、“あるべきユーザ権限と実際の運用の適正性"を守る足がかりになるものでした。
サーバの操作履歴を追跡することで不正利用を追跡する(ログ分析機能)
イベントモニタリングではユーザの様々な行動ログが取得可能で、さらにデータをビジュアライズすることができます。
これにより、例えば特定のアカウントからの不審なアクセスや、不適切なユーザからのレポート実行などを監視することが可能になります。
セキュリティポリシーの自動実行を可能にする(リアルタイム監視機能)
拡張トランザクションセキュリティを利用することで、ユーザの操作をリアルタイムに監視し、さらに制御することができます。
例えばお客様情報の照会・ダウンロードを実施した際に、ユーザごとにブロック・通知をすることもできるので、不正なアクセスをリアルタイムで検知したり、そもそも閲覧できなくしたりといったことが簡単に実現できます。

イベントモニタリングの活用
イベントモニタリングの検証を重ねていく過程で、“システム制限の限界とデータ量増加に伴う性能低下への懸念"もモニタリングによって解決に導くことができるのではという期待が膨らみました。
従来の運用では、Salseforceからエラー通知が来たり、ユーザから異常を知らせるお問い合わせが来てから調査するという、後手の対応となっていました。
上限ギリギリのデータ量で運良く動いているだけの画面や、たまたま事故が起きていないだけで制限を超えうるロジック、Salesforceのパフォーマンスに影響が出るような外部アクセスを事前に検知することができれば、障害を未然に防ぐ仕組みとして使えるのではないか。
そこで、イベントモニタリングの日次ログから、Salesforce内の各所のアクセス数・データ更新量・データロックの頻度・制限超過をグラフ化し、しばらくの間、試験的に毎日推移をチェックするようにしたのでした。
では実際、その期待は応えられたのでしょうか。
以下に一例をご紹介します。
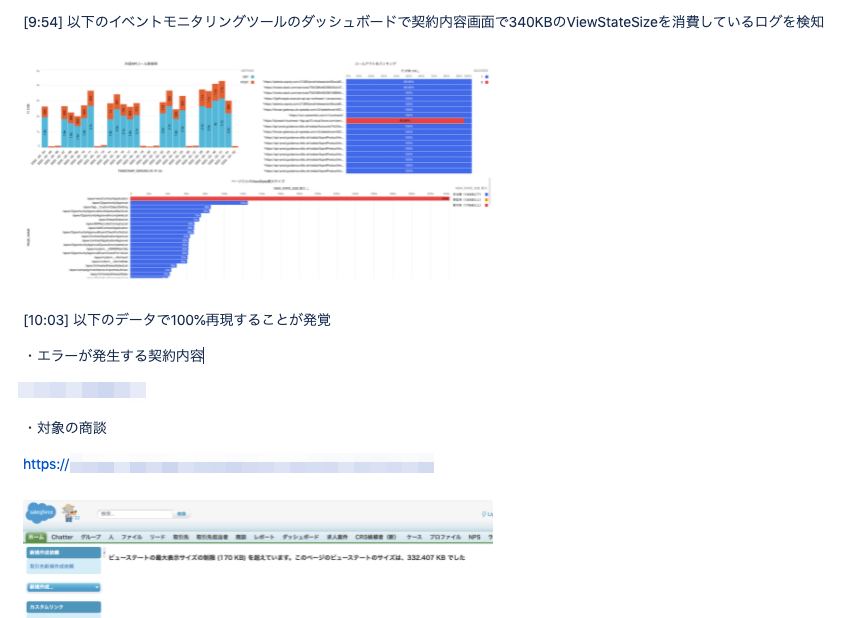
Visualforceのビューステート最大表示サイズの超過
ビューステートはVisualforceページの状態を維持するための暗号化された非表示の文字列ですが、170KBという上限サイズが定められており、超過したページはエラーにより表示できなくなります。
これに対し、ページごとのビューステートの最大サイズを出すことで、超過リスクの高いページを見つけることができました。
現在、超過リスクの高いページを無くすべく、恒久対応を進行中です。
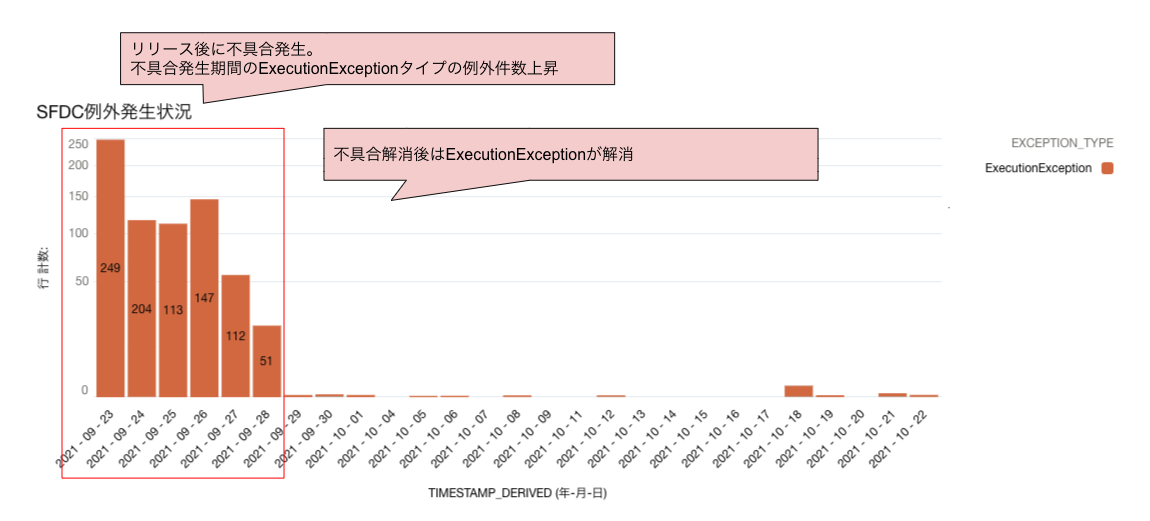
例外発生状況の監視
日毎の例外発生件数を例外タイプ別やエラーメッセージ別に確認することで、例外がどこで多く発生しているかの調査や、今まで出てこなかった例外が突然増えた場合のリスク検知、CPUやデータ件数の上限例外による負荷分析、障害発生時はその収束までの推移確認など、幅広い情報収集に使っています。
外部アクセスの負荷検知と是正
Salesforceには数多くのガバナ制限があり、APIコール数もそのうちのひとつです。
Salesforceに連携している外部システムからのアクセスをモニタリングし、負荷を軽減させ、ガバナ制限に抵触するリスクを回避したりといった改善につなげた一例がこちらです。
-
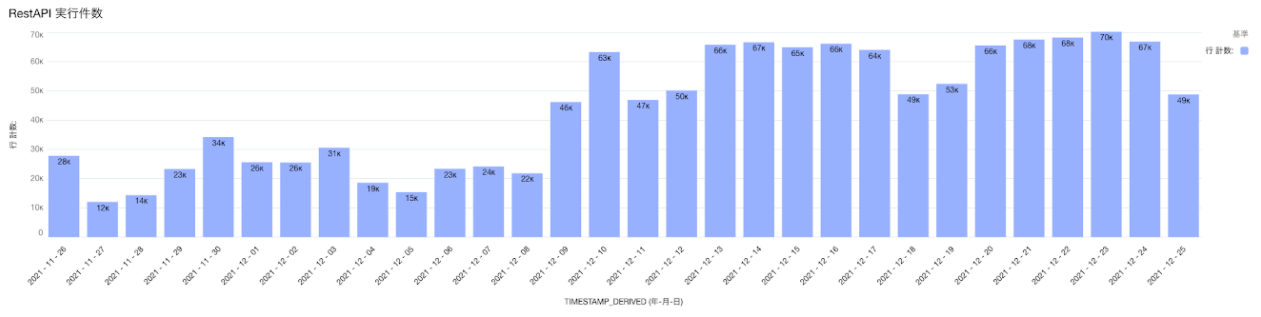
ある日からAPIのアクセス数が上昇傾向にあることを検出しました。
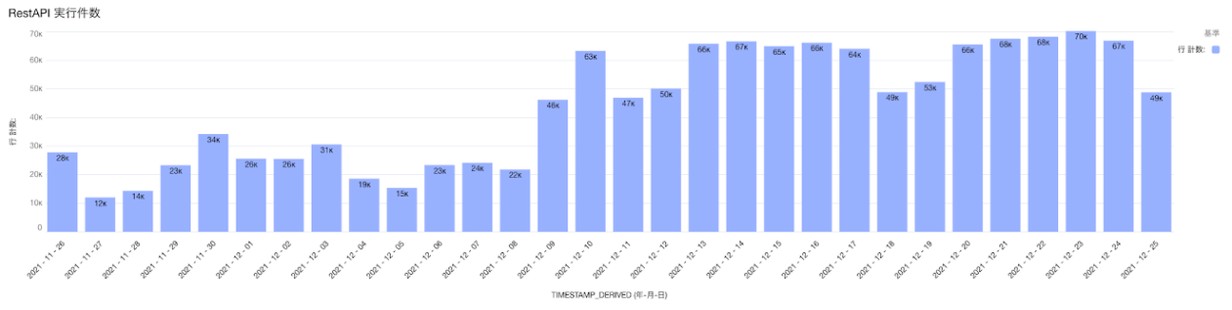 例:APIアクセス数推移
例:APIアクセス数推移 -
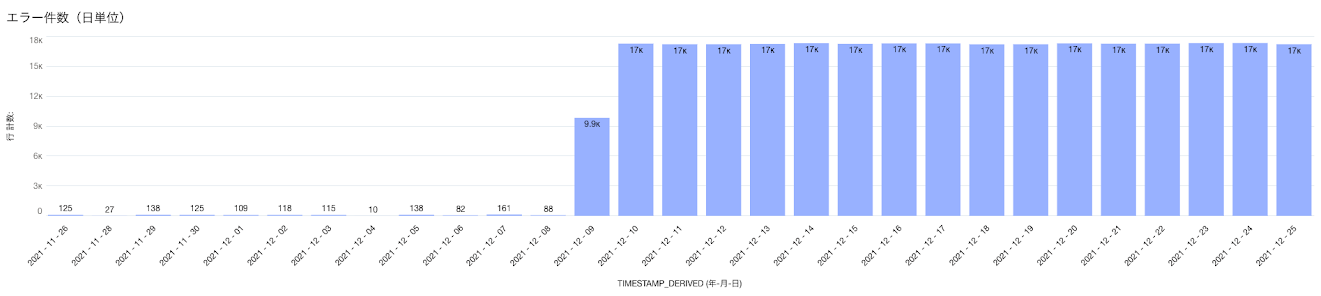
同時期からリクエストエラーが増えていることも読み取れます。
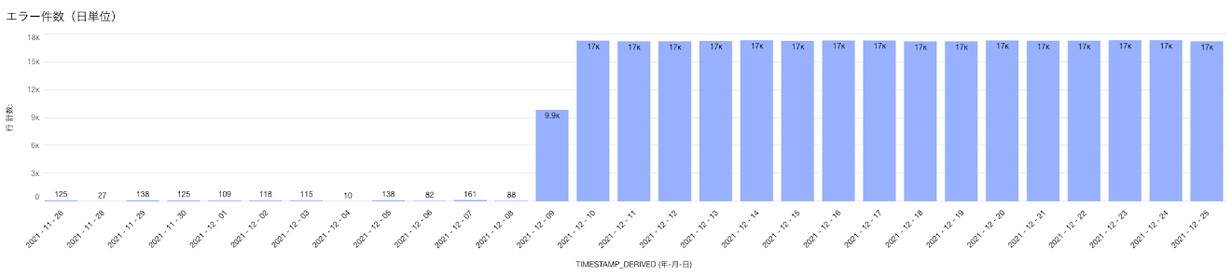 例:リクエストエラー件数推移
例:リクエストエラー件数推移 -
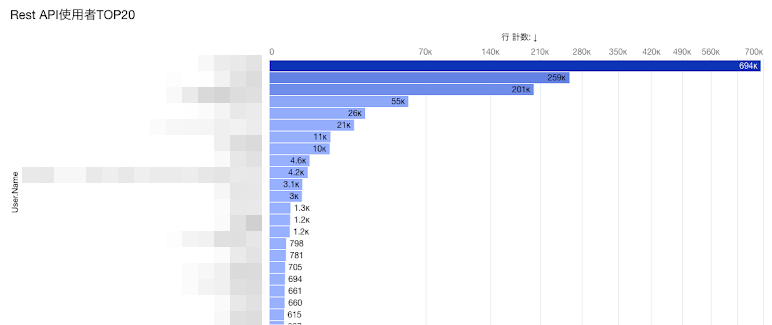
APIアクセス数をユーザごとに順位付けし、APIイベントにて原因と思われるユーザを特定します。こうして見ると、トップのユーザのアクセス数が明らかに他と比較して突出していることがわかりますね。
このユーザは、ある外部システムのシステムユーザでした。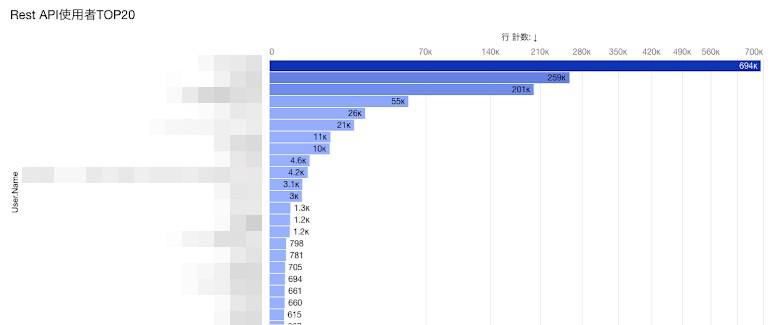 例:API使用ユーザTOP20
例:API使用ユーザTOP20 -
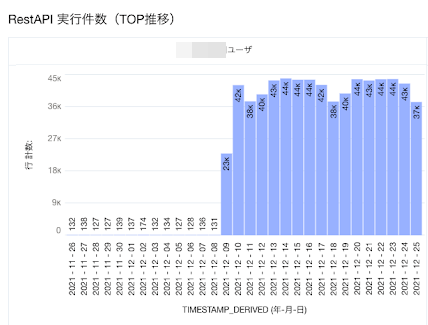
トップのユーザのAPIアクセス数推移を出してみると、時期が全体のAPIアクセス数推移とエラー件数推移にほぼ一致しています。
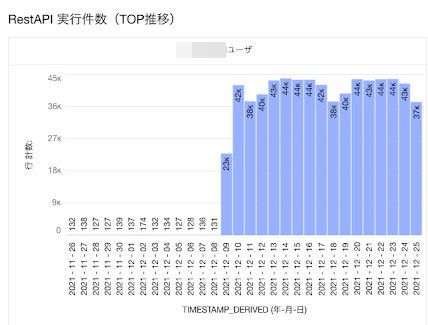 例:特定ユーザのAPIアクセス件数推移
例:特定ユーザのAPIアクセス件数推移
これらのデータをもとに関係者に確認したところ、このグラフの時期に、外部システムから一定時間置きにSalesforceへAPIアクセスし、データを取得するようになったことがわかりました。
そこでエラーが頻発していることやAPIコールの上限数について説明し、データの取得間隔を空けていただくことで、リスクを軽減させることができました。
チームとしてリスクを軽減していく仕組みづくりへ
イベントモニタリングの活用をしていく上で痛感するのは、当然ですが、ツールは手段に過ぎず、最終的には取得したデータをもとに、どのようにユーザに働きかけていくかが肝要だということです。そのためには、私たちチームメンバーそれぞれが、まずは当事者意識をもってデータを捉え、活用できる土壌を作る必要があります。
そこでまずはチームで今まで発生した障害の振り返りを行い、いくつかの観点を導き出し、その観点をもとに作成した値やグラフを持ち回りで毎週分析する時間を設けるという形で、試験運用を始めています。
まだ不慣れで試行錯誤の積み重ねではありますが、チームで行うことによって様々な立場からの視点が得られることはやはり貴重だと感じています。
将来的にはAWSなど外部サービスとも連携し、柔軟で長期に渡る分析や未来予測を見える化することによって、よりスムーズに他部署と情報を共有し合ってシステムの健全性や安全性を高め続けることが目標です。
おわりに
長い間をかけて蓄積してきたシステムの負債や業務の抱える課題は一朝一夕で解決できるものではありませんが、だからこそ、取り組み甲斐があるとも言えます。
私たちのチームでは、「その行動で、ブレイクスルー」というバリューを体現すべく、保守運用に関しても”ブレイクスルー”の姿勢を信条としています。 様々な技術を積極的に学び、持てるスキルを駆使し、基盤システムとしての信頼性とあり方を問い続けながら、プロダクトのさらなる成長に貢献できる道を一緒に模索できるエンジニアを、私たちは歓迎します。





