
株式会社ビズリーチ、検索基盤グループの中瀬です。
検索基盤グループでは、即戦力人材と企業を繋ぐ転職サイト「ビズリーチ」において、検索システムの技術的負債解消や検索品質の向上に取り組んでいます。
本記事では、検索エンジン(Elasticsearch)へのデータ同期システム(indexer)を刷新し、データ反映時間を600秒から30秒へと短縮した事例について、採用したアーキテクチャと共にご紹介します。
なお、本記事の内容は2024年に開催されたAWS SaaS Builders Forum 2024の登壇資料をベースに、当時から拡張した内容も踏まえ、ブログ記事として再構成したものです。
旧indexerが抱えていた課題
刷新前のindexerは、事業成長に伴うデータ量の増加に対し、アーキテクチャが限界を迎えており、以下のような課題が顕在化していました。
- データ鮮度の悪化:
- RDBのリソース逼迫等により、検索結果に反映されるまでのタイムラグが平均10分、最大で1時間超
- 設定変更・障害復旧の困難さ:
- Elasticsearchの設定変更や障害時にはRDBから全件同期し直す必要があり、要する時間は約15時間
- オーナー不在:
- 各プロダクトチームが共有利用していた背景から特定の管理者がおらず、保守・改善の責任所在が曖昧化
これらの課題はサービス品質の低下に繋がっており、将来的なデータ増加にも耐えきれないことが懸念されていました。そこで、根本解決に向けたリアーキテクティングを行いました。
解決策: AWS DMSとFlinkによるストリーミングETL
課題解決のアプローチとして採用したのが、「AWS DMSのCDC(変更データキャプチャ)をトリガーにした分散ストリーミング処理によるETL」です。
アーキテクチャの概要
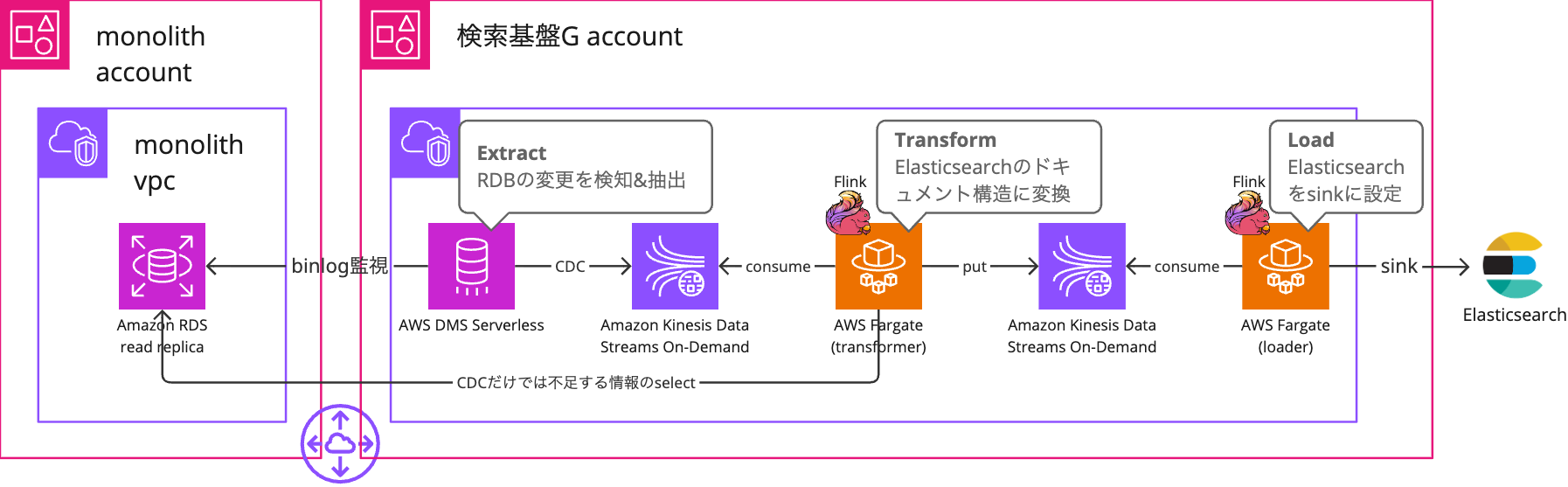
主なデータフローは以下の通りです。
- Extract:
- AWS DMS (Database Migration Service) でRDBの変更をCDCで検知しAmazon Kinesis Data Streamsへ送信
- Transform:
- AWS Fargate上で稼働するApache Flinkアプリケーションがストリームを処理しElasticsearchのドキュメント構造に変換
- Load:
- 同じくApache Flinkアプリケーションが処理結果をElasticsearchへ反映
これらを別途作成した検索基盤グループ専用のAWSアカウント内に移管することで、オーナーシップを明確化しました。
技術選定の理由
このアーキテクチャを実現するために選定した主要技術は以下の通りです。
1. AWS DMS Serverless
- マルチAWSアカウント同期:
- 本番DBアカウントと検索基盤アカウントが異なる環境下でも、容易にデータ同期が可能
- CDCによる更新検知:
- CDCに更新内容が含まれているため、同期対象データ取得用のselectが一部不要となり、RDBへの負荷(IOPS)を軽減
2. Amazon Kinesis Data Streams On-Demand
- Kinesisの「時間指定による再取得」機能:
- 障害時には、Elasticsearchのスナップショットをリストアし、特定時点からストリームを再処理するだけで復旧が可能
- デプロイやindex再構築にも応用可能
3. Apache Flink & AWS Fargate
- JVM系言語(Kotlin)の採用:
- 社内に知見の多いJVM言語で開発でき、Window処理など高度なストリーミング機能を利用可能
- サーバーレスなコンテナ実行:
- EMR等と比較して学習コストが低く、必要最小限の構成で運用負荷を軽減
アーキテクチャと実装の工夫
単にマネージドサービスを組み合わせるだけでなく、アーキテクチャ設計からアプリケーションの実装詳細に至るまで、拡張性とパフォーマンスを最大化するための工夫を取り入れています。
① Kinesisによるアプリケーションの疎結合化と拡張性
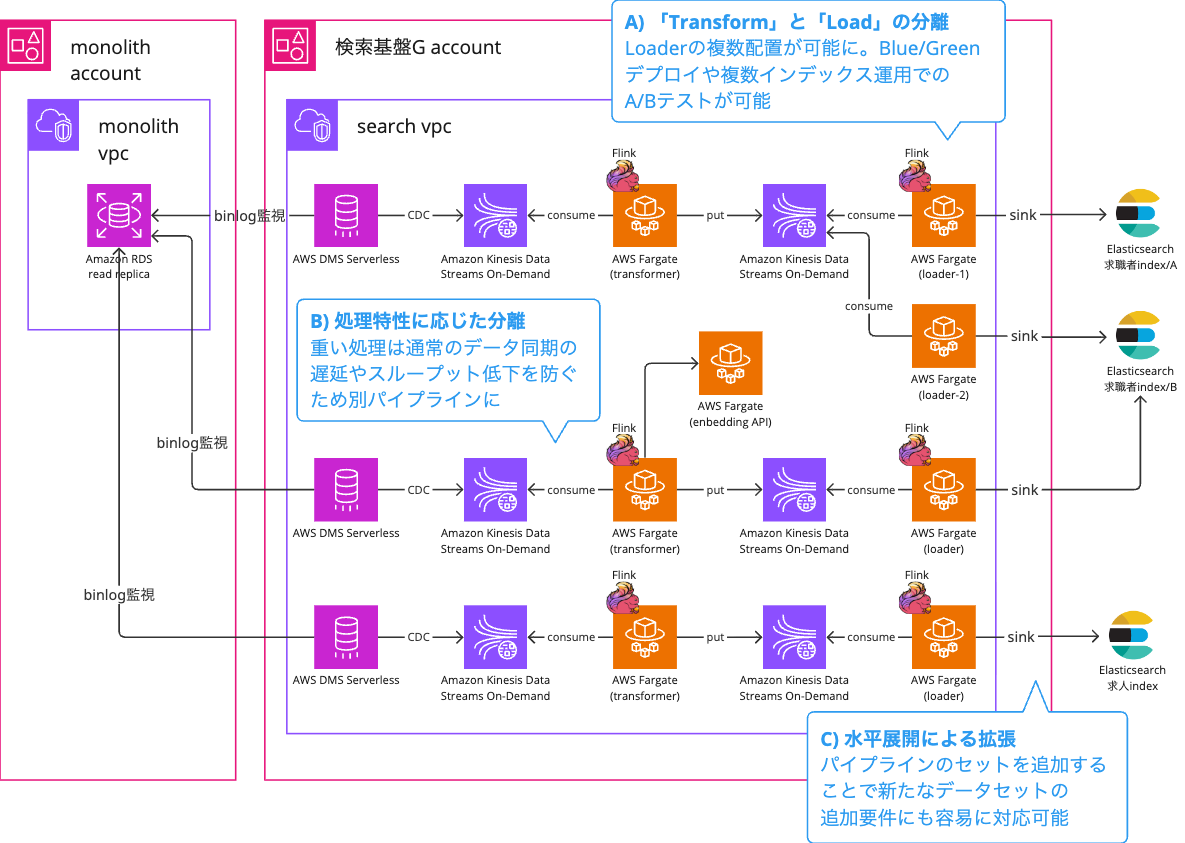
A) 「Transform」と「Load」の分離
ETLの「Transform」と「Load」の間にKinesisを挟むことで、アプリケーションを分離しました。
これにより、図中の loader-1 loader-2 のように複数のLoaderを配置することができ、Elasticsearchのバージョンアップ時のBlue/Greenデプロイや、複数インデックス運用でのA/Bテストが可能になりました。
B) 処理特性に応じた分離
例えば、応答に時間がかかるEmbedding API(ベクトル化)へのアクセス処理を独立したパイプラインに切り出すことで、通常のデータ同期の遅延やスループット低下を防ぐ工夫を取り入れています。
C) 水平展開による拡張
図の下段にある求人情報の同期追加も、IaCによるインフラ構成の共通化とLoader/Transformerの再利用により、設定の追記とデータマッピングのみで完結しました。
※ B)、C) は2024年AWS SaaS Builders Forum登壇当時から拡張した内容
② Window処理によるスループット向上
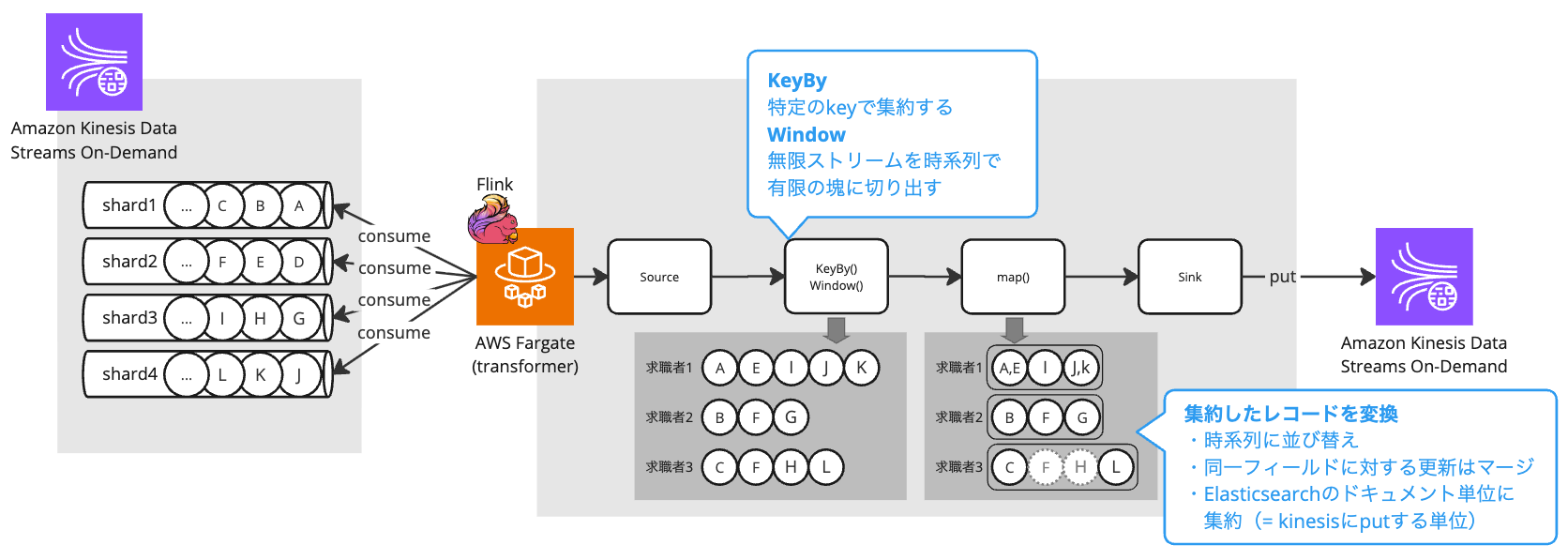
Flinkアプリケーション内でWindow処理を実装し、求職者ごとのデータ更新を一定時間集約してから処理するようにしました。これにより、RDBへの再アクセスおよびElasticsearchへの書き込み回数を抑え、スループットを高めています。
③遅延データのハンドリング(順序性の担保)
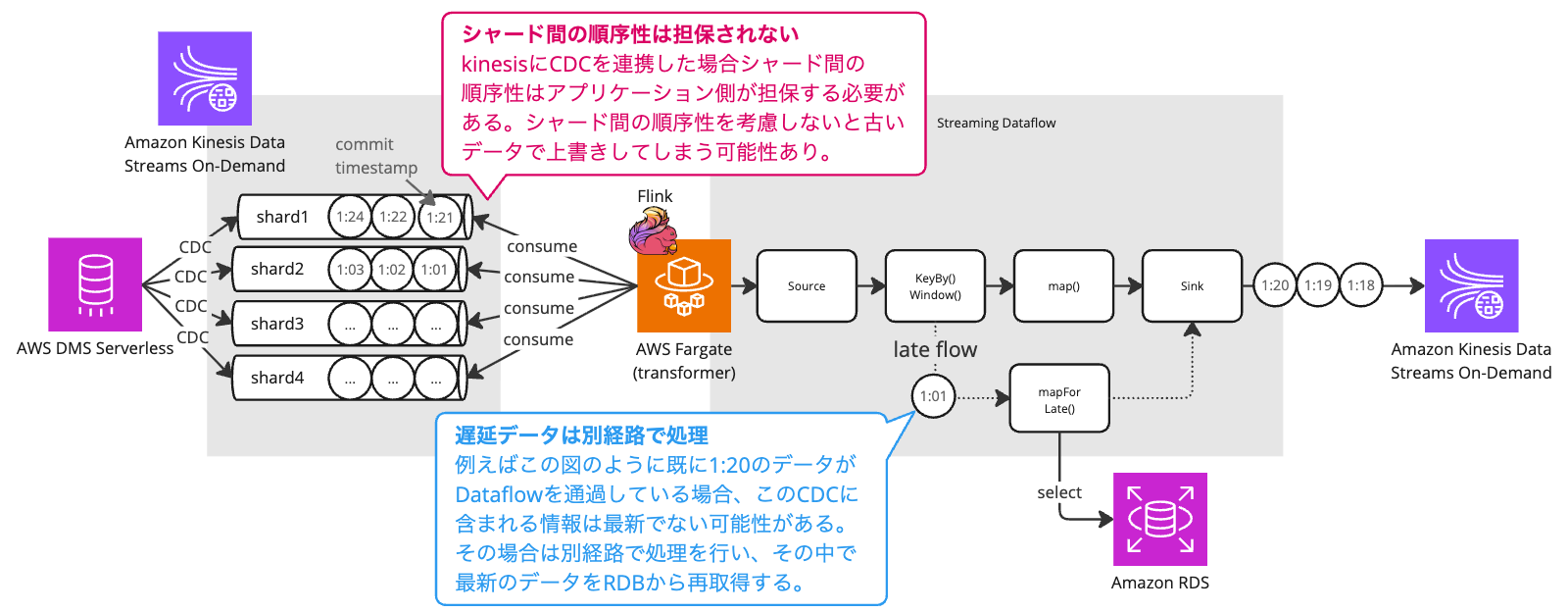
シャード間で順序保証されない「遅延データ」は、図の通りLate Flowへ分岐させます。ここでRDBから最新情報を再取得して処理することで、古いデータによる上書き(先祖返り)を確実に防ぎ、データの整合性を担保しています。
得られた成果
この刷新プロジェクトにより、当初の課題に対して以下のような成果が得られました。
- データ同期時間: 600秒→ 30秒 (20倍の高速化)
- 障害復旧時間: 15時間→ 2時間 (1/8に短縮)
- RDBへの負荷: 旧システム比で 1/10 に減少
パフォーマンス改善にとどまらず、運用改善も併せて行い、属人化の解消や変更コストの削減も実現しています。 例えば登壇資料でも言及した「indexの再構築」の仕組みにより、Elasticsearchの設定変更はオンラインで誰でも容易に実行できるようになりました。
これらの成果により、組織として継続的に変化へ対応できる仕組みが整い、長期的な事業成長に耐えうる基盤を構築することができました。
おわりに
今回の刷新は、将来的なマイクロサービス化を見据えた第一歩でもあります。 現在はマルチAWSアカウント間でのストリーミング処理により安定したデータ同期を実現しましたが、今後はドメイン整理をさらに進め、より最適な仕組みへと進化させていく予定です。
最後までお読みいただきありがとうございました。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。









