
はじめに
検索基盤グループに所属する齊藤です。
検索基盤グループは2022年に発足した組織です。検索精度改善や機械学習モデルの開発とそれを活用した検索機能の実装、さらには技術的負債を解消するための基盤システムの刷新まで、幅広い技術領域の取り組みを推進しています。
「ビズリーチ」では、Elasticsearchの運用基盤として、Elastic社が提供するマネージドサービス「Elastic Cloud」を採用しています。クラウドプロバイダーは主にAWSを利用しているため、本記事もその環境を前提としています。
Elastic Cloudは高可用性やスケーラビリティに優れる一方、インスタンス選定などには独自のノウハウが求められます。ここで紹介する最適化の考え方はその特性を踏まえたものですが、基本的な原則はセルフホスティング環境にも応用できるはずです。
Elasticsearchは非常に強力な検索・分析エンジンですが、その運用、特に大規模環境や多様なユースケースを単一クラスターで賄っている場合には、様々な課題に直面することがあります。
本記事では、私たちが運用していたモノリシックなElasticsearchクラスターが抱えていた問題点と、それを解決するために実施した「クラスター分割」のアプローチ、そしてその結果得られた多くのメリットについて解説します。
モノリシックなクラスターが抱えていた課題
かつて、多くの機能を単一のElasticsearchクラスター(モノリスクラスター)で運用しており、当初は I/O Optimization タイプのインスタンスを利用し、様々な検索ニーズに対応していました。
このクラスターでは、主に以下のような機能を提供していました。
- レジュメ検索: 候補者の職務経歴書(レジュメ)を検索する機能。複雑なクエリが実行されることがあります。
- 求人検索: 求人情報を検索する機能。こちらも多様な条件での検索が求められます。
- メッセージ検索: ユーザー間のメッセージ内容を検索する機能。データ量が膨大になる傾向があります。
- 新着通知バッチ: 新着会員や新着求人を検知し、関連するユーザーに通知するバッチ処理。ここではPercolatorクエリを利用していました。
これらの機能はデータ量、クエリの特性、スループットなどがそれぞれ異なっていましたが、全てが同じリソースを共有していたのです。
| 機能 | データ量 | クエリの特性 | スループット |
|---|---|---|---|
| レジュメ検索 | 中 | 複雑 | 大 |
| 求人検索 | 中 | 普通 | 中 |
| メッセージ検索 | 大 | シンプル | 小 |
| 新着通知バッチ | 小 | 複雑かつPercolator利用 | 大 |
単一クラスターでの運用は、初期構築こそシンプルですが、規模の拡大や機能の多様化に伴い、以下のような多くの課題が顕在化してきました。
- キャパシティプランニングの困難さ:
- 特定の機能の負荷が予測しづらく、クラスター全体の適切なリソース(CPU、メモリ、ストレージ)を見積もることが困難でした。
- 結果として、過剰なリソースを割り当てるか、逆にリソース不足による性能劣化のリスクを抱えることになりました。
- メトリクス監視の複雑化:
- クラスター全体のメトリクス(CPU使用率、JVMヒープ使用率、検索/インデックスレイテンシなど)を監視しても、どの機能がボトルネックになっているのか特定するのが困難でした。
- 問題発生時の原因究明に時間がかかりました。
- ノイジーネイバー問題:
- 特定のインデックスに対する負荷(例えば、大量データのインデックス処理や複雑な検索が頻発するなど)が急増すると、他の全く関係ない機能のパフォーマンスまで低下させてしまう、いわゆる「ノイジーネイバー問題」が頻繁に発生していました。
- ある機能のためのメンテナンスが、他の機能のサービスレベルに影響を与えることもありました。
- バージョンアップの重荷:
- Elasticsearchのバージョンアップを行う際、影響範囲が先ほど挙げた機能全体に及ぶため、全ての機能に対する事前調査、テスト、互換性確認が必要となり、膨大なコストと時間がかかりました。
- 結果として、セキュリティパッチの適用や新機能の利用が遅れがちになり、バージョンが古いまま放置されるリスクも高まっていました。
これらの課題は、サービスの安定性、開発・運用効率、コスト最適化の観点から無視できないものとなっていました。
課題への対処:機能ごとのクラスター分割
これら課題を解消するため、私たちはモノリスクラスターを機能ごとに分割するというアプローチを選択しました。
分割にあたっては、単にクラスターを分けるだけでなく、各機能の特性(データ量、クエリの複雑さ、更新頻度、求められる性能要件など)を再評価し、それぞれに最適なインスタンスタイプ (Optimization Type) を選択し直しました。
Optimization Typeの基礎と選定指針
Elastic Cloudの「ハードウェアプロファイル」は、特性に合わせてCPU・メモリ・ストレージのバランスを最適化した、インスタンスのテンプレートです。 また、m6gdやr6gdといったプロファイル名は、その実体であるAWSのEC2インスタンスファミリーに直接対応しています。そのため、名前を見ればそのインスタンスがどういう特性を持つかを判断できます。
- General Purpose(aws.es.datahot.m5d / m6gd)
- 特徴: バランス型・標準モデル。CPU、メモリ、ストレージのリソースが均等に割り当てられています。
- ユースケース: ワークロードの特性が不明確な場合や、様々な処理が混在する場合の第一候補。
- Storage Optimized(aws.es.datahot.i3 / i3en)
- 特徴: ストレージ特化型。NVMe SSDによる高速I/Oと、i3enによる高密度なストレージ容量が特徴です。
- ユースケース: ログや時系列データなど、データの書き込み・保持が中心となるワークロード。
- CPU Optimized(aws.es.datahot.c5d / c6gd)
- 特徴: コンピューティング特化型。vCPUコアあたりのメモリ・ストレージ比率が低く、純粋な計算能力を最大化しています。
- ユースケース: 複雑なクエリやAggregation、頻繁なインデクシングなど、CPU負荷が高い処理。
- Vector Search Optimized(aws.es.datahot.r6gd)
- 特徴: AI検索特化型。メモリ最適化(r)をベースに、Gravitonプロセッサ(g)による高速なベクトル演算、NVMeストレージ(d)による高速I/Oを組み合わせた構成です。
- ユースケース: セマンティック検索、画像検索、RAGなど、ベクトル検索を前提とするアプリケーション全般。
選定の原則
Elastic Cloudのプロファイルは随時更新されますが、選定時には次の2点を押さえておくと安全です。
- ボトルネックを特定する
- お使いの環境の主要なボトルネックが「CPU・メモリ・ストレージ」のどれかを明確にする。最適なプロファイル選定の第一指針になります。
- ARM系の互換性を確認する
- c6gdやr6gdなどのGravitonプロファイルはコスト効率に優れますが、アプリケーションやプラグインがARMアーキテクチャに対応しているか事前に確認する。
参考: Selecting the right configuration (Elastic Cloud) / AWS EC2 Instance Types
最適なリソース配分:分割パターンの詳細
機能特性に合わせて、主に以下の3つのパターンでクラスターを設計しました。
パターン1: クエリが複雑(データ量中くらい) - バランス型
- 具体例: レジュメ検索、求人検索
- 要求特性:
- 検索クエリが複雑で、多くのフィールドや条件を組み合わせることがある。
- データ量は膨大というほどではないが、それなりに大きい。
- CPUリソース(検索時のアグリゲーションやスコアリング計算)とメモリ(キャッシュや集計処理)をバランス良く消費する。
- 選択したOptimization Type: General purpose (ARM)
- CPU、メモリ、ストレージのバランスが取れたGeneral purpose (ARM)を選択し、複雑なクエリ処理に対応できるようにしました。
- 将来的にベクトル検索をElastic Cloud環境で実現することを想定していたのでVector Search Optimizedも選択肢には上がったが、現時点では少々コストがもったいなかったので見送りました。
パターン2: データ量膨大(クエリはシンプル) - ストレージ特化型
- 具体例: メッセージ検索
- 要求特性:
- 単純なキーワード検索や期間指定検索が主で、クエリ自体は比較的シンプル。
- データ量が非常に大きい(テラバイト級になる可能性も)。
- CPUやメモリへの要求は高くないが、大量のデータを効率的に保存・アクセスできるストレージ性能が重要。
- 選択したOptimization Type: Storage optimized (dense)
- 大容量かつコスト効率の良いストレージを持つStorage optimized (ARM)を選択しました。
パターン3: Percolator利用 - コンピューティング特化型
- 具体例: 新着会員や新着求人の通知バッチ
- 要求特性:
- Percolatorクエリ(登録されたクエリに対してドキュメントをマッチさせる)を多用する。
- Percolatorのマッチング処理はCPU負荷が高い傾向がある。
- データ量そのものは、他の検索機能ほど大きくない場合が多い。
- 選択したOptimization Type: CPU optimized (ARM)
- CPU性能の高いCPU optimized (ARM)を選択し、Percolator処理を高速化しました。
| パターン | 用途例 | データ量 | クエリの特性 | 主要リソース消費 | 選択したOptimization Type |
|---|---|---|---|---|---|
| パターン1: バランス型 | レジュメ検索、求人検索 | 中 | 複雑 | CPU・メモリをバランス良く使用 | General purpose (ARM) |
| パターン2: ストレージ特化型 | メッセージ検索 | 大 | シンプル | ストレージ容量が重要 | Storage optimized (dense) |
| パターン3: コンピューティング特化型 | 新着通知バッチ | 小 | 複雑(Percolator利用) | CPU負荷が高い | CPU optimized (ARM) |
このように、各機能の要求に合わせてリソースを最適化することで、無駄なコストを削減しつつ、必要なパフォーマンスを確保することが可能になりました。
移行プロセス:段階的な切り替え
モノリスクラスターから新クラスターへの移行は、サービス影響を最小限に抑えるため、慎重に段階を踏んで実施しました。
- Step 1: 現行データフローの確認
- まず、既存のモノリスクラスターへのデータ投入・参照の流れを正確に把握しました。
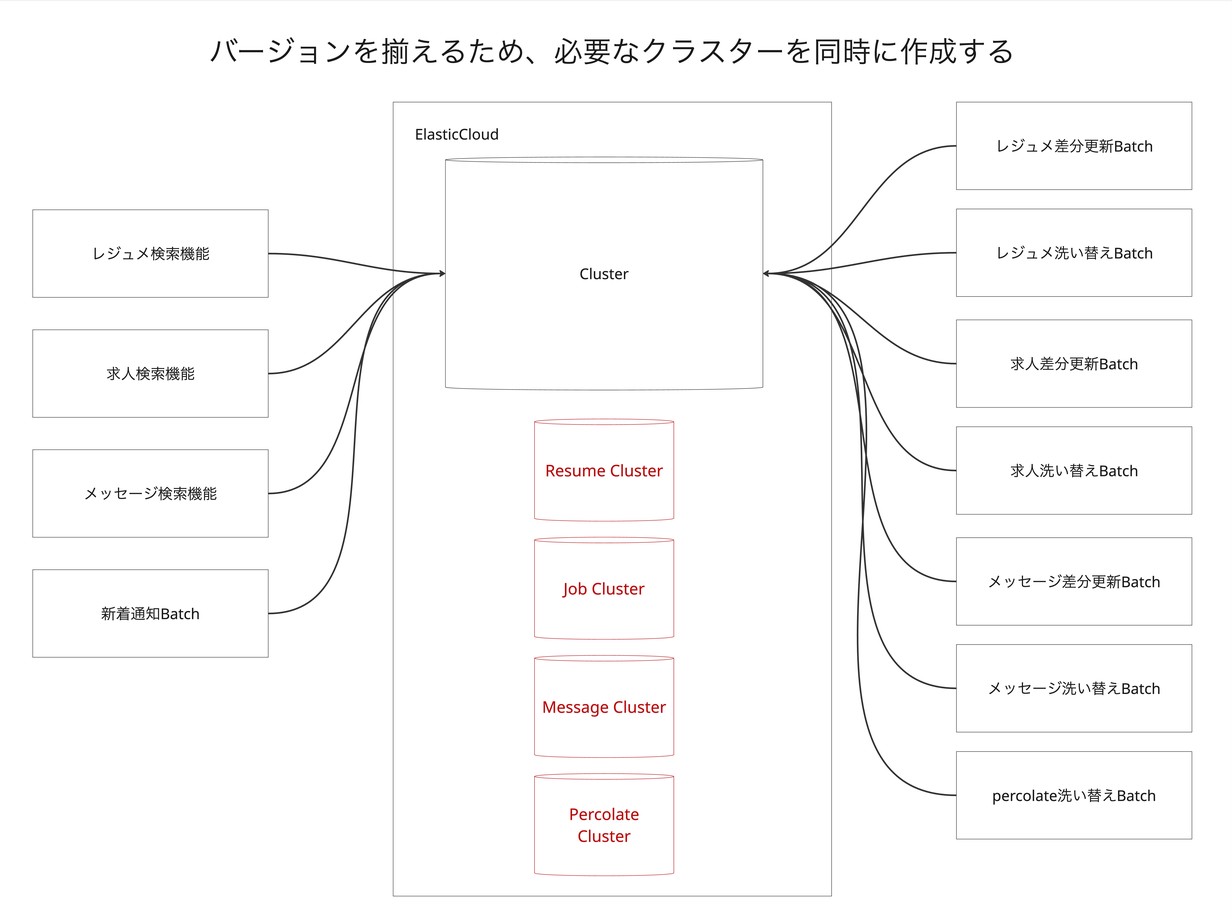
- Step 2: 新クラスター作成
- 各機能に対応する新しいクラスター群を作成しました。
- ポイント: 全てのクラスターを全環境で同時期に作成することが重要です。Elastic Cloudでは、時期によって利用可能なElasticsearchのバージョンが異なる場合があります。テストの整合性を保つ観点から、バージョンを揃えて同時に作成することを推奨します。コストを最小限に抑えるため、最初は最小スペックで作成し、リリース時期にあわせてスケールアップしました。
 移行手順1
移行手順1
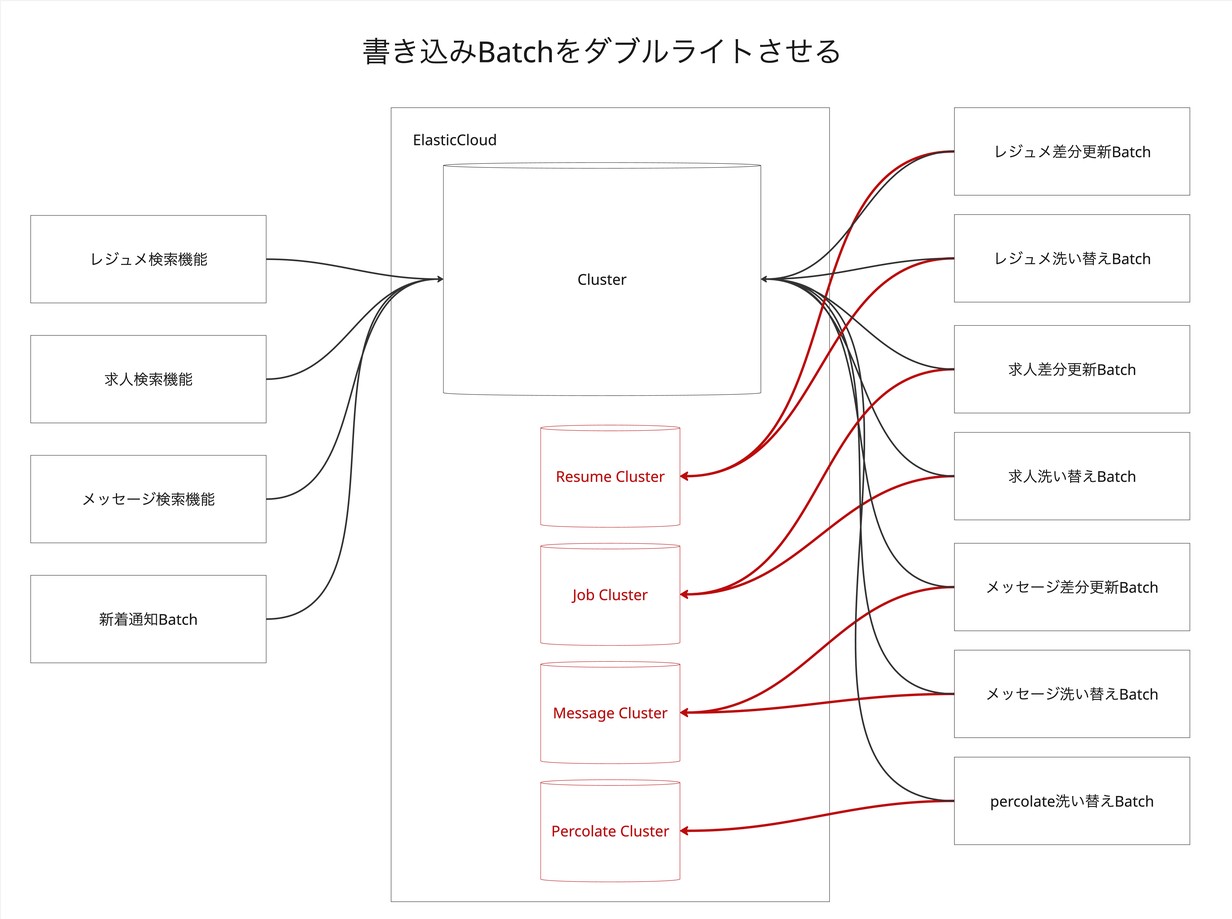
- Step 3: データ同期(ダブルライト)開始
- アプリケーションからのデータ書き込みを、既存のモノリスクラスターと新しい機能別クラスターの両方に行う「ダブルライト」を開始しました。
- これにより、新旧両方のクラスターでデータの一貫性を保ちます。
 移行手順2
移行手順2
- Step 4: 新クラスターへのデータ同期
- 過去のデータを、新クラスターへ移行しました。
- このタイミングで新旧両方のクラスターでデータが完全に同期されます。
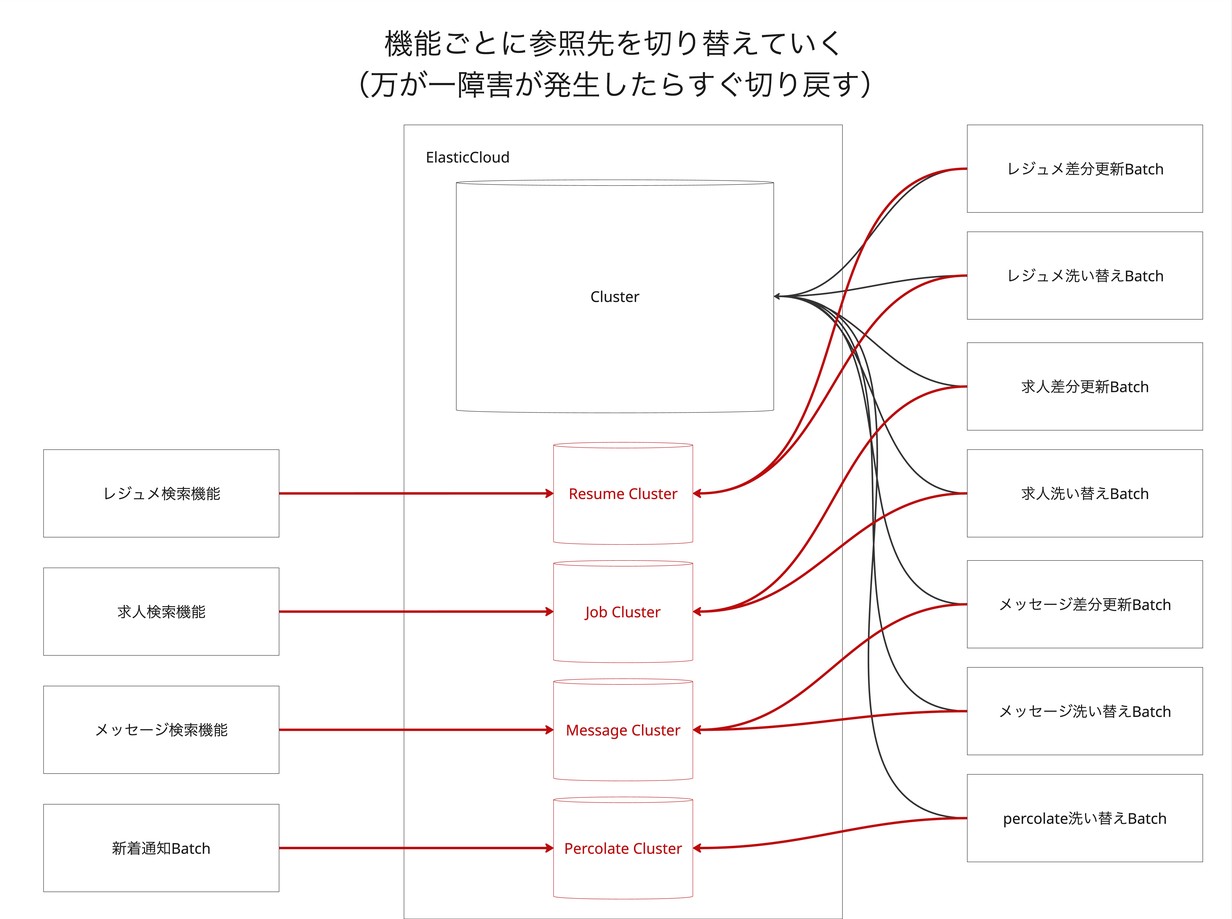
- Step 5: アプリケーションの参照先切り替え
- ダブルライトとデータ洗い替えが完了し、新旧クラスターのデータが一致していることを確認した後、アプリケーションのデータ参照先をモノリスクラスターから新しい機能別クラスターへと切り替えました。
- 機能ごとに段階的に切り替えを実施し、問題発生時の影響範囲を限定しました。
- ポイント: 参照先の切り替えは機能ごとに段階的にリリースすることが重要です。これにより、万が一障害が発生した際、影響範囲を最小限にとどめることができます。事前に綿密なテストをすることはもちろん重要ですが、影響範囲が膨大になる場合は、障害時の影響範囲と影響時間を最小限に抑えられるフローを選択することも大切です。
 移行手順3
移行手順3
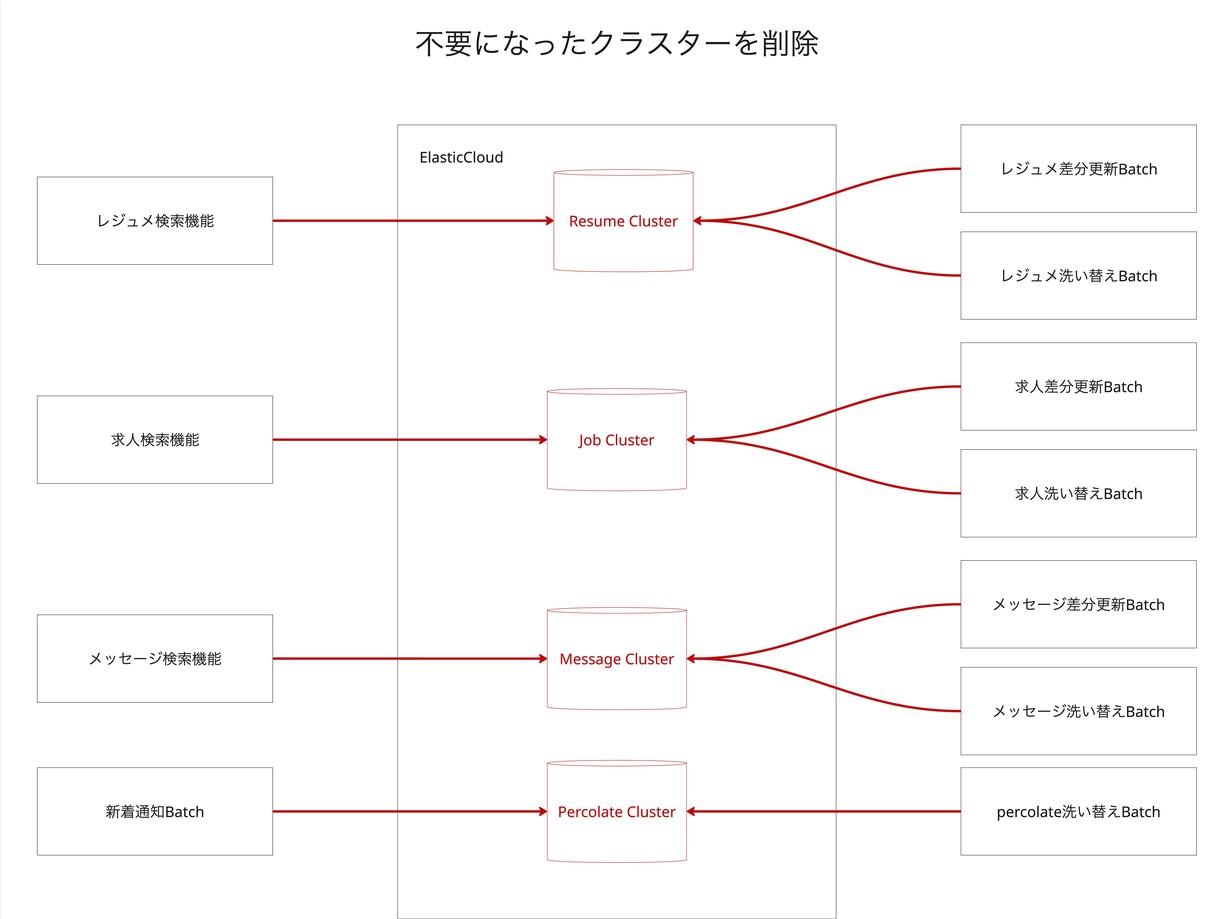
- Step 6: 旧クラスターの廃止
- 移行完了後、モノリスクラスターは不要となり、廃止しました。
 移行手順4
移行手順4
- 移行完了後、モノリスクラスターは不要となり、廃止しました。
クラスター分割の結果:得られたメリット
クラスター分割によって、当初抱えていた課題は解消され、多くのメリットを得られるようになりました。以下に、各課題に対応する形で得られたメリットを説明します。
- キャパシティプランニングの困難さの解消:
- 機能ごとに独立したクラスターとなったことで、各機能の負荷特性に合わせた適切なリソース配分が可能になりました。
- 各機能に最適なインスタンスタイプを選択できるようになり、過剰なリソース割り当てを避けつつ、必要な性能を確保できるようになりました。
- 結果として、リソースの無駄を削減し、全体で25%のコスト削減に成功しました。
- メトリクス監視の改善:
- クラスターごとに監視対象が明確になり、どの機能でどれだけの負荷がかかっているかが一目瞭然になりました。
- CPU、メモリ、レイテンシなどのメトリクスから、ボトルネックの特定やパフォーマンスチューニングが格段に容易になりました。
- 問題発生時の原因究明が迅速化され、トラブルシューティングの効率が大幅に向上しました。
- ノイジーネイバー問題の解消:
- 機能ごとにクラスターが分離されたことで、ある機能の高負荷や障害が他の機能に影響を与えなくなりました。
- 特定の機能のためのメンテナンスも、他機能のサービスレベルを気にすることなく実施できるようになりました。
- これにより、システム全体の可用性と信頼性が大幅に向上しました。
- バージョンアップの容易化と迅速化:
- バージョンアップの影響範囲が機能単位に限定されるため、事前調査やテストのスコープが大幅に縮小されました。
- これにより、より迅速かつ安全にバージョンアップを実施できるようになり、セキュリティパッチの適用や新機能の早期導入が可能になりました。
- 万が一、バージョンアップ後に問題が発生した場合でも、影響を受けるのはその機能クラスターのみとなり、リスクを限定できます。
これらのメリットは、サービスの安定性向上、運用効率の改善、コスト最適化、そして開発サイクルのスピードアップに大きく貢献しています。モノリスクラスターが抱えていた構造的な課題を根本から解決することで、より持続可能なElasticsearch運用体制を確立することができました。
今後の展望と新たな課題
クラスター分割は多くのメリットをもたらしましたが、一方で新たな側面も考慮する必要があります。
- 運用対象クラスター数の増加:
- 管理すべきクラスターの数が増えるため、プロビジョニング、設定管理、監視設定などの運用タスクは若干増加します。
- 将来的なElasticsearchのアップデート作業は、クラスター数分だけ必要になりますが、前述の通り、影響範囲が限定されるため、一つ一つのリリース作業は格段に行いやすくなっています。
- Kibana運用の分散:
- 各クラスターに個別のKibanaが存在する場合、データの横断的な可視化や分析がやや煩雑になる可能性があります。
- 対策として、監視・運用専用のクラスターを設け、そこから各機能クラスターに対してCross-Cluster Searchを行う構成を検討しています。これにより、単一のKibanaから複数のクラスターデータを横断的に検索・可視化できるようになります。
まとめ
Elasticsearchのモノリスクラスター運用は、初期段階では有効な場合もありますが、システムの成長と共に多くの課題を生み出す可能性があります。機能や特性に応じてクラスターを分割することで、以下のような非常に大きなメリットをもたらします。
- 監視性の向上
- スケーラビリティとコスト効率の改善
- 障害影響範囲の局所化
- バージョンアップの容易化
もしモノリスクラスターの運用に課題を感じているのであれば、クラスター分割は検討に値する強力な選択肢となります。本記事が、Elasticsearch運用改善の一助となれば幸いです。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










