
はじめに
株式会社M&Aサクシードで法人限定M&Aプラットフォーム「M&Aサクシード」の開発をしている出村です。
私たちのチームは長らく、バックエンド開発における「偶発的な複雑さ」という深刻な課題に直面していました。調査した結果、この問題は「コンポーネント」「モジュール」「クラス」それぞれの境界設計にあると結論付け、各境界に応じた施策を行いました。
本稿では、これら3つの境界設計のうち「モジュール」の設計に着目し、「エンティティ中心」から「ユースケース中心」のパッケージ設計へ転換した事例を紹介します。この取り組みにより、コードベースが 「密結合で低凝集」から「疎結合で高凝集」な状態に改善され、開発効率や品質が大きく向上しました。
※ 結合度:モジュール間の相互依存の強さ/変更の波及しやすさ (低いほうが望ましい)
※ 凝集度:モジュール内の要素が同じ目的・変更理由でまとまっている度合い(高いほど望ましい)
私たちが直面していた「謎の複雑さ」
私たちのバックエンド開発には「謎の複雑さ」とも呼ぶべき厄介な課題が存在していました。この「謎の複雑さ」は次のような具体的課題として表面化していました。
小さな変更でも影響範囲が大きい
軽微な仕様変更や機能追加であっても、多くのパッケージをまたがって多数のクラスやファイルに修正が広がり、影響範囲の調査や修正作業の工数が増加し、コードレビューの負担も増大していました。
コードリーディングによる疲弊
呼び出し階層が非常に深く、DTO変換のような単純な処理でさえ、何層ものクラスを経由する「バケツリレー」状態でした。時には意図せずDBアクセスが実行されるなど、処理の追跡が困難でした。
コンフリクトと遅延
複数人が同じファイルを変更する頻度が高く、Pull Request(PR)のコンフリクトが発生していました。 変更対象が被ることで、バグが発生した際にどのPRによるものかの把握に時間がかかり、工数見積もりがブレやすく遅延の要因になっていました。
ユニットテストが困難
あるクラスのユニットテストのために10以上のモックが必要だったり、クラスごとの責務が多すぎてテストケース作成コストが大きく、テストカバレッジの低下を招きました。
実装の不統一と属人化
エンジニアによってコードスタイルや設計方針が異なり、コードレビューや新メンバーのオンボーディングに大きな負担が生じていました。
謎の複雑さの原因
私たちが採用しているバックエンド開発の技術スタック(Kotlin/JVM + Spring)はごく一般的なものであり、ビジネスロジックも特別複雑なものはありませんでした。そのため、私たちが直面していた謎の複雑さの本質的な原因は、「何を使っているか」や「ドメイン固有の複雑さ」ではなく、「どう作ったか」、つまり設計や実装のやり方そのものに原因があると考えました。
当初私は、この複雑さは「DRY原則(Don’t Repeat Yourself)の過度な適用」が原因だと推測しました。しかし分析を進めると、実際には「意識的にDRY原則を過剰に守ろうとしたわけではないが、なぜか過剰な抽象化や共通化が起きていた」という状態であることがわかりました。
つまり、DRY原則の過剰適用は「原因」ではなく、複雑さの「表面的な現れ方」に過ぎなかったのです。そこで、より深く分析した結果、この現象を引き起こしていた真の根本原因が見えてきました。
表面的に現れていた問題:早すぎる抽象化と安易な再利用
私たちのチームでは、「将来的に再利用できるかもしれない」「似ている処理だから共通化した方がよい」と考える傾向がありました。また、「すでに動いている処理を少し変更するだけで再利用できる」という利便性から、安易な再利用も頻繁に行われました。
その結果、気づけば過剰に抽象化された汎用的な処理が多く作られ、複数のユースケースがそれに依存する構造となりました。こうした構造は変更の影響範囲を拡大させ、保守性を大きく低下させました。
実際にパッケージ間の依存関係を可視化すると、複雑に絡み合っており、ある機能の修正時に影響範囲を直感的に把握できないほどでした。
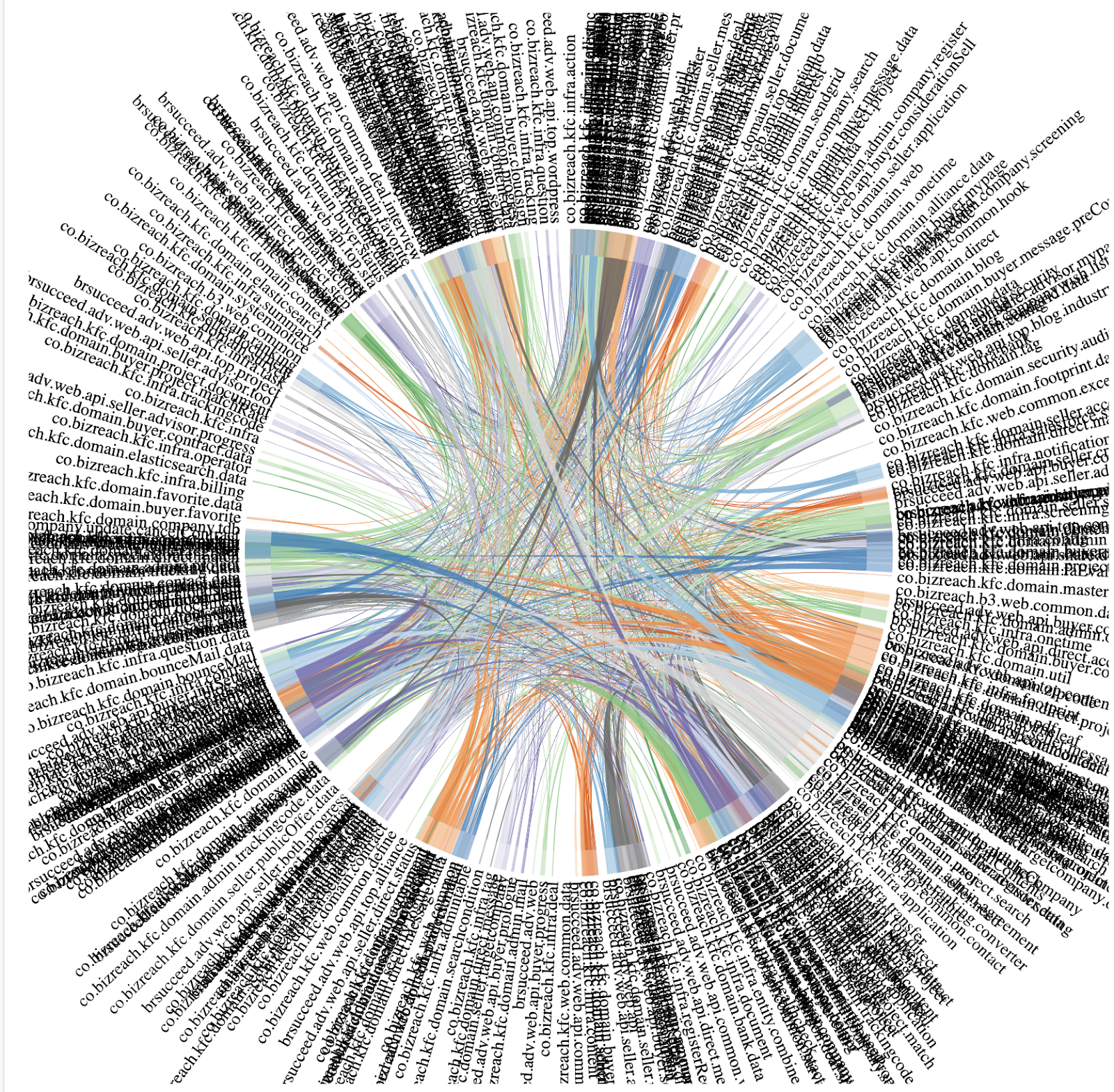
本質的な原因:エンティティ中心のパッケージング
私たちが直面した複雑さの根本原因を深掘りしてみると、そもそもの出発点となった「過度なDRY原則の適用」という問題は、実は表面化した症状にすぎないことがわかりました。本質的な問題は、コードをどのような単位(軸)で整理するかというモジュールの設計思想そのものに潜んでいたのです。
当時、私たちのチームでは「Account」「Company」といったエンティティを軸にしてパッケージを分割していました。この方法は、一見すると整理された構造に見えます。しかし、実際にシステムが成長していく中で、次第にパッケージ間の依存が複雑化し、偶発的な複雑さが急速に増大しました。
つまり、私たちが直面した偶発的複雑さの本質は、「エンティティ単位でモジュール化」という設計思想そのものに起因していたのです。この設計思想が、なぜ汎用的な共通処理を生みやすく、またそれが頻繁に再利用されるのか、という具体的なメカニズムについて、詳しく見ていきます。
なぜ汎用的な抽象クラスが生まれやすくなるのか?
エンティティ単位でパッケージを整理すると、「そのエンティティに関係する処理はパッケージ内でまとめるべき」という無意識的なプレッシャーが開発者に働きます。その結果、個別のユースケースごとの具体的な処理を作成するよりも、「エンティティに関連するあらゆるユースケースを最初から想定した抽象的で広範囲な処理」を作る傾向が強まります。 こうした心理的かつ構造的な影響により、汎用的な共通処理が自然と生まれやすくなるのです。
なぜ汎用的な関数が再利用されやすくなるのか?
汎用的な関数が再利用されやすい最も本質的な理由は、少しの修正を加えるだけで手軽に短期的な目的を達成できるという利便性にあります。 具体的には、既存の汎用関数は元々さまざまなユースケースを想定して設計されているため、引数の追加や条件分岐の挿入といった「少しの変更」で容易に自分の目的に合わせることができます。
開発者にとっては、新たな関数を一から作るより、すでに動作しているという実績のある汎用な関数に簡単な修正を施す方が心理的にも工数の面でもハードルが低く感じられます。この「手軽さ」が、汎用的な関数の再利用を自然に促進する最大の動機になっています。
結果として起こる悪循環
エンティティパッケージングによって生み出された汎用的な処理は、当初は「複数のユースケースに対応可能で再利用性が高い理想的な処理」に見えます。しかし実際には、この汎用処理を本当の意味で成功させるためには、将来にわたって発生しうるあらゆるユースケースや要件変更を正確に予測し、設計段階から適切に対応しておく必要があります。
ところが、現実にはこの予測はほぼ不可能です。そのため、システムが成長する過程で後から細かな例外ケースや新たな要件変更が次々と生じます。開発者はそのたびに新しく専用の処理を作ることを避け、既存の汎用処理にわずかな変更(パラメータの追加や条件分岐)を加える形で対応を繰り返します。
結果として、もともとはシンプルで汎用的だった処理は次第に複雑な条件分岐や大量のパラメータが追加されていき、本来の単純さや汎用性を失い、理解や保守が困難な処理へと姿を変えてしまいます。このように汎用処理が複雑化していくと、各ユースケースは「本当に必要な部分がどこにあるのか」が見えにくくなり、コードを理解し修正するためのコストは著しく増大します。
また、共通処理に依存するユースケースが増えることで、ちょっとした変更であっても影響範囲が非常に広くなり、コード変更のリスクが飛躍的に高まります。
これこそが、私たちが直面していた「偶発的な複雑さ」の正体です。汎用的な共通処理の失敗やDRY原則の過度な適用は、表面的な症状にすぎません。その本質は、「エンティティ中心の設計」が持つ構造的な問題が、複雑さを招くという点にあったのです。
偶発的な複雑さを解決するための取り組み
これまで述べてきた課題を踏まえ、私が目指すべきは、「過度な抽象化・共通化とその再利用による負のサイクルを断ち切る構造を作る」ことでした。そのために実際に行ったアクションはシンプルでした。
ユースケース単位でのパッケージ構造への変更
従来の「エンティティ単位」のパッケージ構造を、「ユースケース単位」のパッケージ構造へ変更する決定を行いました。 具体的には、以下の2つの実装方針を設けました。
1. パッケージ単位を「ユースケース」へ
従来の「エンティティ単位」を捨て、ユースケースごとにパッケージを切ることにしました。「1ユースケース = 1 APIエンドポイント」としました。
2. 重複の許容
ユースケース間で実装が重複しそうでも、まずは重複を許容し、パッケージをまたぐ依存関係を徹底的に排除しました。
狙い
このアプローチにより、各パッケージは「特定のユースケースの実現」という単一の責務を持つ自己完結型のモジュールとなります。これにより、早すぎる抽象化が抑制され、自然と疎結合で高凝集な構造が実現されると考えました。
成果
今回の取り組みは、チーム全体にポジティブな変化をもたらしました。 私たちが施策を通じて最も期待していたことは、「過度な抽象化や共通化、そしてその再利用による負のサイクルを断ち切る構造の実現」に寄与する成果でした。この期待通りの成果に加え、予想外の副次的成果も得ることができました。
期待通りの成果
変更影響範囲の劇的な局所化
変更の影響が該当ユースケースのパッケージ内に限定されるようになりました。例えば、「ユーザー登録機能」の修正は、その専用パッケージ内で完結し、他機能への副作用を心配する必要がなくなりました。
健全な抽象化・共通化の促進
重複を許容したことで、コードベースに類似実装が複数現れた際に、初めて共通化の是非を検討できるようになりました。実際の実装を見てから「これは明確に抽象化できる」と自信を持って判断できたときのみ、適切な共通化を行いました。これにより、現実のニーズに基づいた意味のある抽象化が行われるようになりました。
予想外の副次的な成果
コードレビューの効率改善によるチーム生産性の向上
従来は共通化によって影響範囲が広がり、レビューアーは変更箇所に関連する多数のモジュールや機能を理解し確認する必要がありました。変更範囲が局所化されたことで、レビュアーの負担が激減し、迅速かつ正確なレビューが可能になりました。
並行開発の促進によるチーム生産性の向上
私たちのチームでは、ある特定のユースケースの実装がそのまま1タスクになることが多いです。今回の施策により、パッケージの単位がユースケースとなり、すなわちタスクの境界とパッケージの境界が一致することが増えました。
これにより今までのようなお互いに同じ共通クラスに変更を加えてしまい副作用を与え合う状況などが大幅に減少し、安全な並行作業が可能となりました。
生成AIとの高い親和性によるチーム生産性の向上
実装が標準化され、影響範囲も明確かつユースケース内に閉じるように限定的になったため、生成AIによるコーディング支援の精度が向上し、開発効率がさらに高まりました。
こうした変化により、私たちのチームは開発の生産性を一段階引き上げることができたと実感しています。
おわりに
本稿では、境界設計の取り組みの一つとして、エンティティ中心ではなくユースケース中心でパッケージを構成する方法を紹介しました。シンプルな施策ではありますが、予想以上に大きな効果を生み、チームにとって大きな学びとなりました。
特に良かったのは、これまで「謎の複雑さ」として感じていた問題を言語化し、その正体を設計上の課題として捉え直せたことです。曖昧な不満を構造的な問題として理解できたことで、初めて再現性のある改善に取り組むことができました。
今回の経験を通じて、技術選定や実装力以上に、境界をどう設計するかという“設計力”の重要性を改めて実感しました。もちろん改善はまだ途上ですが、この気づきは今後のシステムづくりにおける確かな指針になると考えています。本稿が、同じように謎の複雑さに悩む方々の参考になれば幸いです。









