
はじめに
こんにちは。株式会社ビズリーチの検索基盤グループで機械学習エンジニアをしているDatと申します。
求職者検索の高度化とセマンティック検索への挑戦
「ビズリーチ」では、企業と求職者との最適なマッチング機会を最大化するため、日々検索品質の向上に取り組んでいます。特に、求職者の職務経歴書や企業の求人票の複雑な内容を深く理解し、関連性の高い候補者を見つけ出すことは、プラットフォームのコアな課題です。この課題を解決するため、我々はセマンティック検索の開発を進めています。
セマンティック検索は、単語の一致だけでなく、意味的な類似性に基づいて結果を返す技術です。この技術のプロダクトへの展開において、我々は高精度かつ低レイテンシと高い解釈性というプロダクト要件を満たす検索モデルの採用が必要でした。その解決策として着目したのが、SPLADE (Sparse Lexical AnD Expansion) という疎ベクトルベースのニューラル検索モデルです。
本記事では、我々が独自に実装し、GitHubに公開したSPLADEの学習コードと、そのコードで学習した日本語SPLADEモデルについて詳細に解説します。
背景
なぜ「疎な(Sparse)」ニューラル検索モデルが必要だったのか?
近年、セマンティック検索の主流はBERTなどの事前学習言語モデル(PLM: Pre-trained Language Model)を用いた密ベクトル検索 (Dense Retrieval) にシフトしています。しかし、密ベクトル検索には、実プロダクトへ適用する際に避けて通れない課題が存在しました。
1. 大規模データにおけるレイテンシの懸念
数百万件規模のドキュメントを対象とする求職者検索において、密ベクトル検索では大規模データセット上での検索速度が課題となる場合があります。 近似近傍探索(ANN) は密ベクトル検索を高速化するための有効な手法ですが、データセットの規模が増大するにつれて、その高速化効果にも限界があります。
一方、疎ベクトル表現を用いることで、ベクトル内の非ゼロ要素が少ないという特性を活かし、従来の転置インデックス (Inverted Index) を利用した高速な検索基盤(例:ElasticsearchやOpenSearch)を適用できます。これにより、さらなるスピードアップとスケーラビリティの両立が可能となります。
2. 結果に対する解釈性の確保
我々が提供するマッチングプラットフォームの特性上、「なぜこの求職者(または求人)が関連性の高い検索結果として表示されたのか」という説明性(解釈性)が非常に重要になります。密ベクトルは意味的な情報を高密度に圧縮するため、結果がなぜ関連したかを人間が理解することは困難です。これに対し、疎ベクトルは非ゼロ要素が特定の単語や概念に対応しているため、モデルが出力したトークンをタグのように扱い、検索結果の根拠として利用することができます。
これらの課題を解決し、プロダクト要件を満たすために、我々はSPLADEというスパースなアプローチを選択しました。そのアプローチの詳細を次項で説明します。
SPLADEの概要
Sparse Lexical AnD Expansionとは
SPLADEは、Sparse Lexical AnD Expansionの略であり、BERTなどのTransformerモデルを用いて、クエリやドキュメントを疎な語彙ベースのベクトルに変換するモデルです。
これは、従来のBM25のような語彙ベースの検索が持つ高速性と解釈性を保ちつつ、BERTによる意味的な拡張の恩恵を受けることを目指しています。
具体的なメカニズムとしては、BERTによる単語拡張機能により、入力されたテキストは元の単語だけでなく、関連する概念や同義語を含む疎ベクトルへと変換・拡張されます。
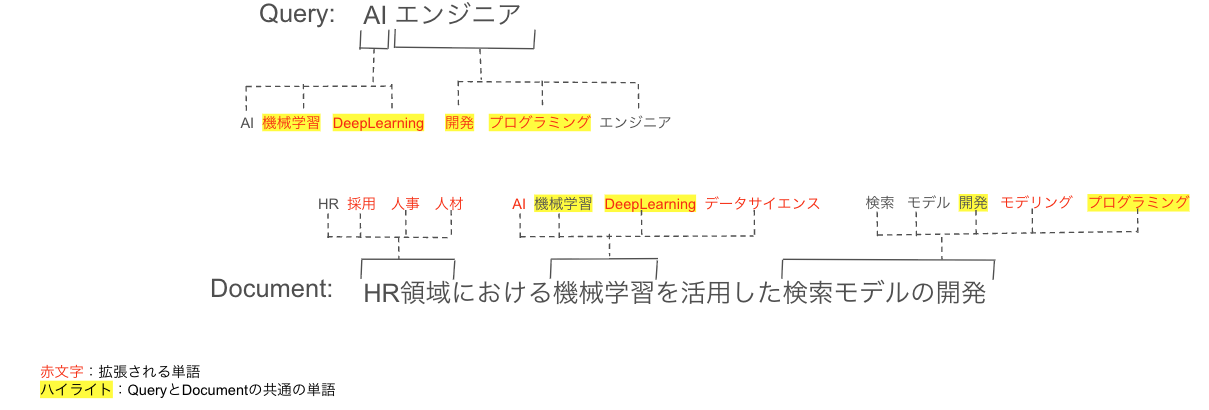
例えば、図1に拡張のイメージを示します。Queryが「AIエンジニア」である場合、Documentが「HR領域における機械学習を活用した検索モデルの開発」というテキストだったとしても、SPLADEは「AIエンジニア」を「機械学習」「DeepLearning」「開発」「プログラミング」などの関連単語(赤文字部分)に拡張するため、共通の単語(ハイライト部分)が増え、より適切にマッチングできるようになります。
SPLADEのアーキテクチャと疎ベクトル生成メカニズム
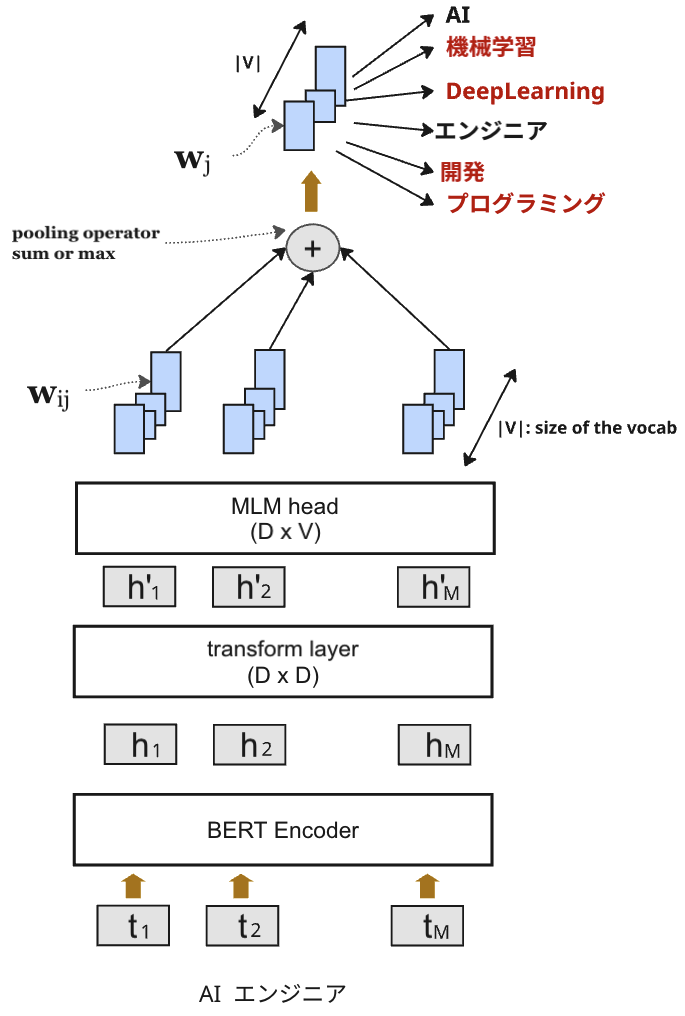
SPLADEモデルの核となるのは、BERTの最終出力から、語彙全体に対応する疎ベクトルを生成する部分です。SPLADE v2をベースとしたアーキテクチャを図2に示します。
1. BERTによる埋め込みと語彙への射影
まず、入力テキストのトークン $t = (t_1, t_2, \dots, t_M)$ ($M$はトークン数)をBERTエンコーダーに入力し、隠れベクトル $(h_1, h_2, \dots, h_M)$ を取得します。 次に、それぞれの隠れベクトル $h_i$ をtransform layerで変換し、BERTの語彙数 $|V|$ に対応する次元へ射影します(MLM head*)。 この射影により、入力トークン $t_i$ が語彙内の各トークン $j$ に与える重要度 $w_{ij}$ を以下の式で計算します。
$$ w_{ij} = \text{transform}(h_i)^T E_j + b_j $$
ここで、$E_j$ は語彙内のトークン $j$ に対応する埋め込みベクトルで、$b_j$ はbiasのパラメーターです。
通常のBERT学習では、これらの出力にsoftmax層を適用し、次のポジション(i+1)のトークンを予測します。一方、SPLADEではsoftmaxの代わりに Pooling層を通して、入力全体に対する各語彙のスコア $w_j$ を集約します。
* MLM Head(Masked Language Model Head):BERTがマスクされたトークンを予測するために使用する出力層です。
2. 疎ベクトル生成
最終的な疎ベクトル $w = (w_1, w_2, \dots, w_{|V|})$ を得るために、語彙内の各トークン $j$ のスコア $w_j$ を計算します。
$$ w_j = \max_{i \in t} \log (1 + \text{ReLU}(w_{ij})) $$
これは、入力テキスト内の各トークン $t_i$ が語彙トークン $j$ に与える重要度 $w_{ij}$ の中から、各語彙に対して最も高い値をMax Poolingにより抽出していることを意味します。このMax Pooling操作によって、各入力トークンが生成する複数の語彙スコア分布を統合し、入力全体としての語彙スコアを得ることができます。その結果、入力テキストに対する スパース表現 (語彙レベルの重要度ベクトル) が得られます。
スパース性を確保する正則化と損失関数
SPLADEを効果的に学習させるには、適合性(Relevance)を高めるだけでなく、ベクトルが過度に密になることを防ぎ、スパース性を保つための工夫が必要です。
1. 損失関数
適合性を学習するための損失関数として、SPLADEでは In-Batch Negatives (IBN) を用いた損失関数を採用しています。
$$ L_{\text{rank-IBN}} = \log \frac{e^{\text{sim}(q_i, d^+_i)}}{e^{\text{sim}(q_i, d^+_i)} + e^{\text{sim}(q_i, d^-_i)} + \sum_j e^{\text{sim}(q_i, d^-_{i,j})}} $$
ここで、
- $q_i$: クエリのベクトル
- $d^+_i$: $q_i$ の正例ドキュメントのベクトル
- $d^-_i$: $q_i$ の負例ドキュメントのベクトル
- $d^-_{i,j}$: バッチ内の $i$ 以外のクエリに対する正例ドキュメント(クエリiの負例ドキュメントとする)の該当のベクトル
- $\text{sim}(q, d)$: クエリベクトル $q$ とドキュメントベクトル $d$ の類似度を計算する関数です。 SPLADEでは、類似度には内積を用います。
2. スパース正則化
疎ベクトル検索の利点である低レイテンシ(高速性)を維持するためには、ベクトル内の非ゼロ要素の数を制御する(=スパース性を高める)必要があります。
この 「非ゼロ要素」(=重みを持つ単語)だけがスコア計算の対象 となるため、非ゼロ要素の数が多すぎると、その分だけ計算コストが増えてしまい、検索速度が低下します。
そのために、FLOPS正則化(Floating-Point Operations Per Second)を導入します。これは、実質的に各語彙トークンの重みの二乗和を最小化することで、ベクトル全体の活性化を抑制し、結果的にスパース性を高めます。これにより、検索時の計算コストの増加を抑制することが可能になります。
$$ L_{\text{FLOPS}} = \sum_{j \in V} \left(\frac{1}{B} \sum_{i=1}^B w_j^{(d_i)}\right)^2 $$
ここで、
- $B$: バッチサイズ
- $w_j^{(d_i)}$: ドキュメント $d_i$ における語彙 $j$ の重みです。この値は非負です。
この正則化項を損失関数に加えることで、モデルは必要な単語のみを拡張するように学習します。
3. 全体の損失関数
最終的な損失関数は、クエリとドキュメントの両方に対して正則化項を加えたものとなります。
$$ L = L_{\text{rank-IBN}} + \lambda_q L^q_{\text{reg}} + \lambda_d L^d_{\text{reg}} $$
$L^q_{\text{reg}}$ と $L^d_{\text{reg}}$ はそれぞれクエリとドキュメントのFLOPS正則化項であり、ハイパーパラメータ $\lambda_q, \lambda_d$ によってクエリとドキュメントのベクトルのスパース性を調整できます。
日本語SPLADEモデルと学習コードのOSS公開
我々は、上記のアーキテクチャと学習の工夫を適用し、日本語でのセマンティック検索を可能にするSPLADEモデルを独自に実装しました。そして、この取り組みを通じて得られた知見をコミュニティに貢献するため、モデルと学習コードをOSSとして公開しました。
公開モデル
学習した日本語SPLADEモデルは、Hugging Face Hubで公開しています。このモデル自体はApache 2.0ライセンスで提供しており、商用利用を含めて安心してご利用いただけます。
推論レイテンシを削減するために、現在は小さいモデルサイズの 14M・28M・$\text{56M}^{(※)}$ の3種類のモデルを公開しています。モデルサイズによって、適合性(精度)とレイテンシの間にはトレードオフが存在します。
詳しくは各モデルのページを御覧ください。
- bizreach-inc/light-splade-japanese-14M
- bizreach-inc/light-splade-japanese-28M
- bizreach-inc/light-splade-japanese-56M
(※)「M」は「Million(ミリオン)」を意味します。
モデル利用サンプルコード
以下に、公開モデルを利用して入力されたテキストから疎ベクトルを生成するサンプルコードを示します。
|
|
上のコードを実行すると、以下のように「日本の首都は東京です。」という文章から疎ベクトル(キーワードとその重み)を抽出できます。
|
|
この疎ベクトルを、Elasticsearch、OpenSearch、Qdrantなどの疎ベクトル検索に対応した検索エンジンに渡すことで、スパースな表現に基づいたドキュメント検索を実行できます。
公開コード
上記のSPLADEモデルを学習するために独自に実装したコードを、Apache 2.0ライセンス(商用利用可能)で、light-splade リポジトリとして公開しています。
light-spladeは、PyTorchベースで実装された、軽量かつ拡張性の高いSPLADEモデル学習用OSSです。 SPLADEモデルの学習から疎ベクトルの生成までを一貫してサポートしており、ElasticsearchやOpenSearchなど既存の検索エンジンに統合できるスパース表現を出力します。現在、light-spladeは SPLADEv2 および SPLADE++ に対応しています。
light-spladeの主な特徴は以下の通りです:
- PyTorch + Hugging Face Transformers によるSPLADE学習パイプライン
- SPLADE++ で提案された蒸留学習(Distillation) に対応し、ColBERTやdense BERTなどの教師モデルから効率的に学習可能
- 学習済みモデルをIR (Information Retrieval) システム互換のスパース表現にエクスポート
- 軽量・シンプルな構造で、研究・実験から実運用まで柔軟に対応
また、 examples ディレクトリにはトイデータセットを用いたSPLADEv2のサンプルコードが含まれており、以下のように簡単に学習を実行できます:
|
|
light-spladeを使ってSPLADEモデルで文章を推論し、疎ベクトルを抽出するサンプルコードは以下の通りです。
|
|
まとめと今後の展望
本記事では、「ビズリーチ」における候補者検索の品質向上を目指したセマンティック検索導入の背景を説明しました。そして、低レイテンシと高い解釈性というプロダクト要件を満たすために採用したSPLADEモデルについて、アーキテクチャやFLOPS正則化を用いた学習の工夫を解説しました。
最後に、我々が独自実装した日本語SPLADEモデルと学習コードをOSSとして公開したことを報告しました。これにより、日本語でのセマンティック検索に取り組むエンジニアの皆様の一助となれば幸いです。
今後の展望としては、SPLADEを実際の検索システムに組み込んだ上でのA/Bテストによる継続的な効果検証、およびドメイン固有の知識を取り入れたさらなるモデルの改善を進めていきます。また、SPLADEが出力する疎ベクトルを活かした解釈性向上機能をユーザー体験に組み込むことにも挑戦していきます。
おわりに
ビズリーチでは、このような先端的な機械学習モデルの導入と、それを支える大規模検索システムの開発・運用に情熱を燃やすエンジニアを募集しています。ご興味をお持ちいただけた方は、ぜひ弊社採用ページをご覧ください。
検索基盤エンジニア/ビズリーチプロダクト 機械学習エンジニア/リクルーティングプロダクト本部
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










