BizReachプロダクト開発部、SREグループの久保木です。
今日は連載の最後の「AWS S3に蓄積したlogをGoogleのBigQueryに投入する仕組み作り」の七転八倒編をお送りしたいと思います。どうぞよろしくお願いします。
- 前編: 概要
- 中編: 技術調査・設計
- 後編: 七転八倒ログ
そして七転八倒が始まった
当然そんなすんなりいくわけなかったのである。
Triggerは1つだよ!
S3からGCSにlogを送る時にLambdaをtriggerすると書いてあるけど、いきなりここに罠がある。
というのもここには元々S3からRedshiftにlogを送るlambdaがある。
で、S3は仕様上、同じprefixに複数のtriggerを設定することは出来ない。
それをするには、S3=>SNS=>Lambda1,Lambda2,...という風に間にSNSを挟む必要があった。もう早速使うserviceが増えたぞぅ(実は元々SNS使ってたからそこに追加するだけで良かったことが後でわかる)。
LambdaからGCSへ書き込むには……
まずLambdaを書くとしてlibraryはPythonで書くならこういうものがあるのでサクッと使うことにする。参考例としてはこちら。さすが本家。
では実際にcodeを書いてみたのでdeploy……あ、command経由なのか。CIに組み込みたいけどとりあえず今はいいか。
このあたりは割とトントン拍子。さあdataを送ってみよう!
|
|
あ、権限何も設定してなかった。ごめん……。
GCSにdataを送るための権限の設定
サービスアカウント認証情報というものがあるらしい。
サービス アカウントとは、ユーザーではなくソフトウェアを表す特殊なアカウントです。これは、アプリケーションがCloud Storageを使用して認証するための最も一般的な方法です。各プロジェクトにはいくつかのサービス アカウントが関連付けられています。これらは、さまざまな認証シナリオで使用できる以外に、署名付きURLやPOSTを使用したブラウザへのアップロードなど、高度な機能を有効にする場合にも使用できます。
サービス アカウントを使用してアプリケーションを認証する場合は、ユーザーを認証してアクセス トークンを取得する必要はありません。代わりに、Google Cloud Platform Consoleから秘密鍵を取得でき、このキーを使用してアクセス トークンの署名付きリクエストを送信します。これで、通常と同じようにアクセス トークンを使用できます。詳細は、Google Cloud Platform Authガイドをご覧ください。
これを使うとどういう動きをするかというと、
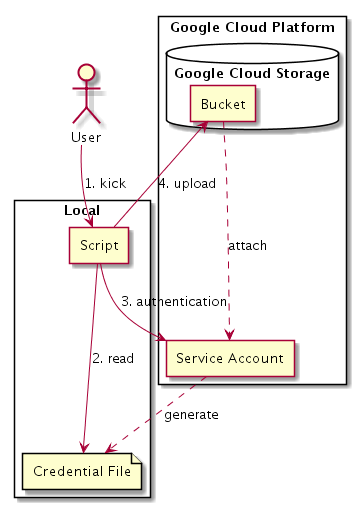
こんな風に、localでScriptを実行したとすると、まずService Accountで認証して、そこで通ると、Service Accountに紐付けられたGCP内のServiceへaccessできるというものらしい。
これを設定して上げたらさっくりlambdaからのuploadは成功した。
trigger設定するだけであとはもうlog移送はできるので、なんか大体出来た気になってきた。
Functionsの作成
もちろんそんなわけがない。というかGCS送っただけで、GCSからBigQueryへの動線作り終わってないじゃないか。んもう。
Cloud Functionsを書くを参考に定番のhello worldから。
|
|
で、画面上からdeployしてみた分には普通に動作した。
あとはCloud Storageからのデータの読み込みの概要とnodejs-bigquery/samples/tables.jsを参考にざっくり実装。
で、完成。
そして1日1回の書き込みでいいと思っていたけれど、試しにfileが転送される都度BigQueryに書き込んでみようか、なんていう遊び心がふと湧いてきた。それが出来れば転送から書き込みまで一気に片がついてしまうやったぁーなんていう打算があった。
そのように実装してみた。
めっちゃErrorを吐き始めた。何故に。
制限というものをよく見ようという話
https://cloud.google.com/bigquery/quotas?hl=ja
BigQueryでは、受信するリクエストの最大レートが制限され、プロジェクト単位で適切な割り当てが適用されます。具体的なポリシーは、リソースの可用性、ユーザー プロフィール、サーバー使用量の履歴などの要因に応じて異なり、予告なく変更される場合があります。
あっ。
えっと。max rateは?
宛先テーブルの日次更新回数制限 - 1日あたりテーブルごとに1,000回の更新
おおっと? いや僕がこの文面の解釈を間違えているのかもしれない。
http://wondershake.hatenablog.com/entry/2016/08/18/120000
BigQueryはテーブル毎に1日にInsertするJobを作れる制限が決まっており、それが1,000件になっています。 それを超えてしまい、どうしようもなくなった!という状態でした。
間違ってなかったよ……。
どうもBigQueryは、なるべく少ない回数で、大きなdataを一気に取り込んだり、取り扱う、という(小さなdataをstreamのように送ってちまちまと処理させる、という方向性とは逆)の方針で利用するのが仕様に叶う利用方法らしい。
ちなみにgoogleの方に聞いてみたところ、その方針であっているとのこと。それと、
サイズは100MB〜1GBの範囲になるとき、BigQueryのパフォーマンスが最も良いと思われます。
とのことだった。ほほうほほう。
ということでGCSからBigQueryへの書き込みは1日1回のBatch処理として解決することにした。
Batch的に取り込む
Batch的に実行するとして、どうすればいいのか。
いやまあ、まずはcron job風に特定時刻で実行させよう。大体そんなにたくさんのlogじゃないから大きく詰まるということもないし。
が、しかし。残念。
どうやらFunctionsにはcron jobみたいな仕掛けはないらしい。いやGAEを利用すればできるようだけど、このためだけにGAEを立ち上げて管理するというのも何か違う気がする。というかInfrastructure担当としては管理するServiceを増やしたくない。
なので今回はちょっと遠回りだけど、AWSのCloudWatchからCronでlambdaを動かして、triggerとなるfileをGCSに配置して、それをtriggerにfunctionsを動かして取り込ませるようにしよう。
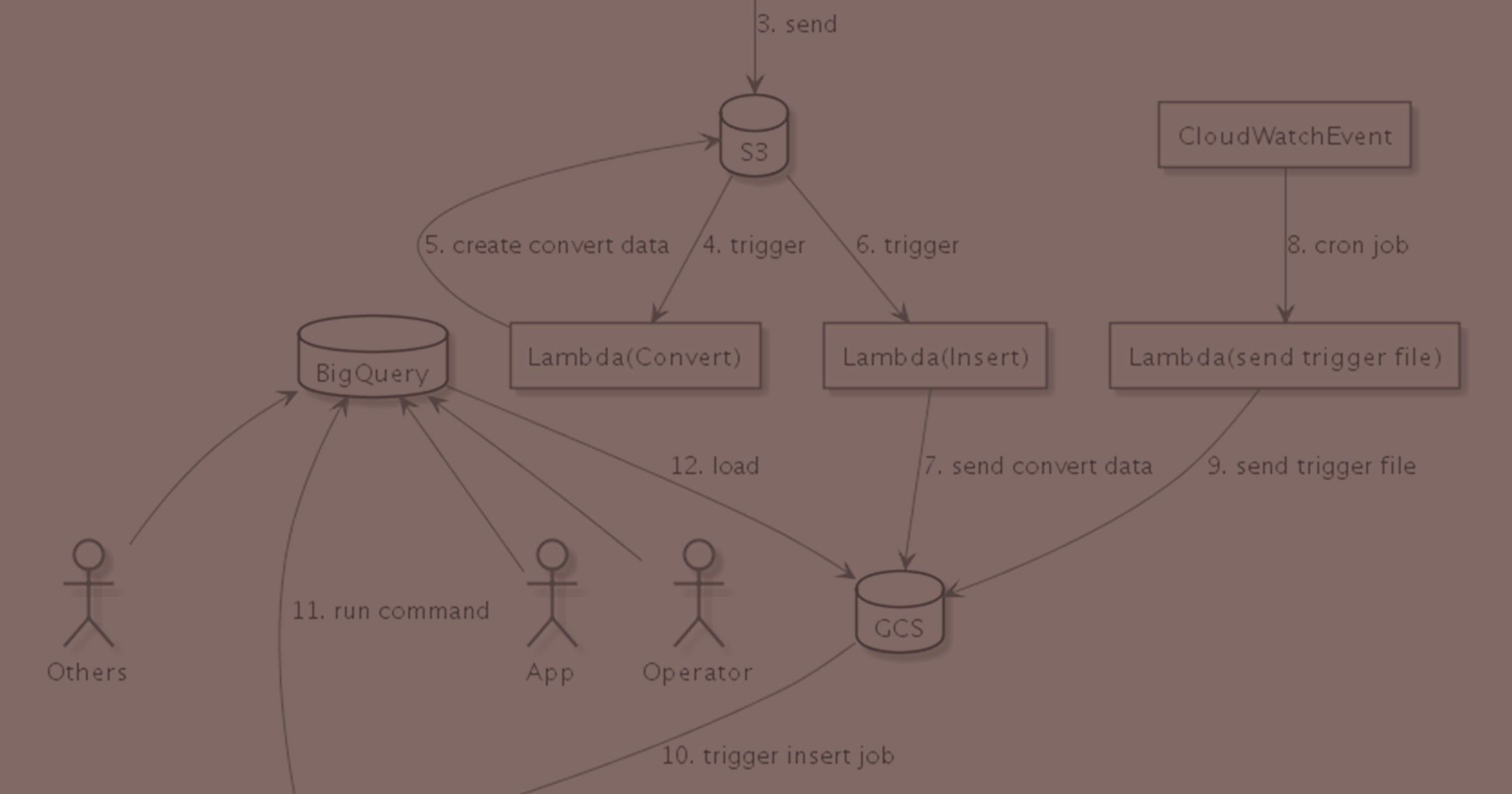
図にするとこんな形になる。
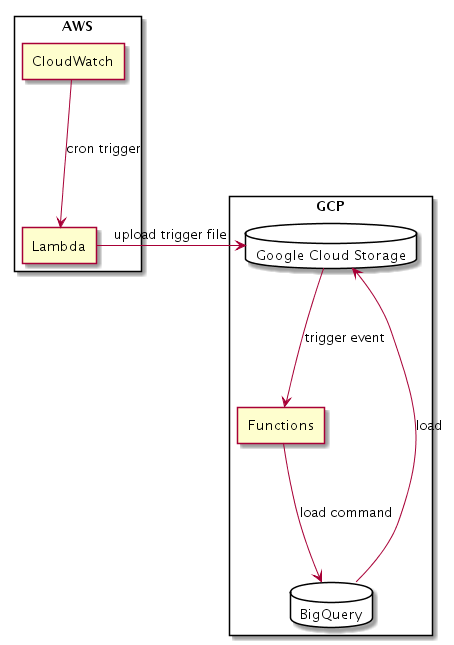
おお。よし。なんだか全然洗練されてない……。(<よしじゃない)
あれ。でもあれだ。これ、ついでにtrigger fileで何月何日のdataを取り込めばいいかなどを指定すればそれでrestoreの仕組みも完成しちゃうのでは? おお天才(調子に乗っています)。
結果的に実装の手間が一つ減ったので、ひとまずはこれで行ってみよう。うん。何かもっといい手順を思いついたらまた書き換えようとdocumentにmemoを残しつつ……。
結果全体像としてはこういうものになった。
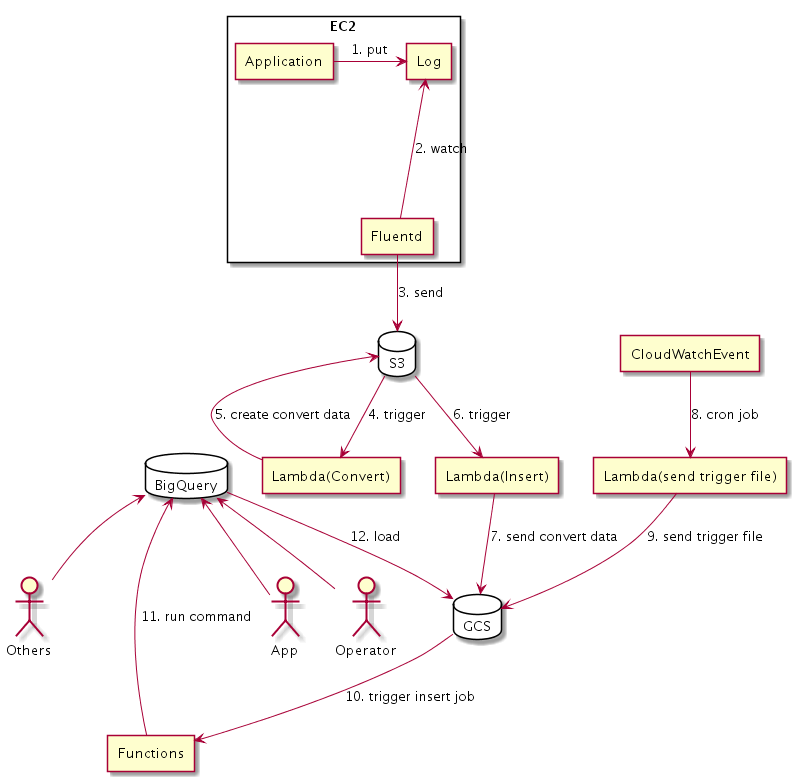
そしてErrorは消えた。悪は滅びたのだ。
過去logの投入
次に過去logの投入という課題がやってくるのだけれど、ここであることに気づいてしまった。
Google Cloud Platformのweb consoleからMenu -> Storage -> 転送というところを見てみよう。
実は他のCloud等からdataを持ってくる転送jobの設定ができたらしい。
S3からも。
S3からも。
このときの僕の気持ちがわかるだろうか。うぉん……悲しい。いやでも、今はありがたい。そんな喜怒哀楽入り交じったあれこれがあった。なお表面上は数秒硬直して設定をポチポチ進めて動作確認していた。
これでさくっとfile共有して、あとは専用のFunctionなりを書いてBigQueryに投入すれば終わりだとやってみたら、うん、終わった。
実際にはlogの中にvalidation error的な物もあっていろいろお掃除することになって数日かかったけれど、これで終わったのだ……うん……はぁ…………。
だが待って欲しい
ということは、だ。
jobの設定でfile共有が出来ると言うことは、だ。
それも定期的に実行するとかもできると言うことは、だ。
S3からLogを転送するのに、Lambdaを使う必要、無かったのでは……?
まあ転送がどこまで終わったかを判断するのに少し気を遣う必要があるくらいだけれど、割とそれでも、いけそうな気がする。
今回に限っては動くようになったからひとまずそれでいいとして、今後の改修課題として考えておこう……。
終わった後で振り返って
ということですごく長くなりましたが、無事、S3に蓄積されていたlogをBigQueryにも投入できるようになりました。
七転八倒は実際にはcode実装時にもたくさんあったのですが(nodeで並列処理させるためにPromise調べて一日終わったとか)、今回は大枠の話でまとめてみました。
それにしても最後の最後で気づいた転送jobが思ったより早くて手軽だったあたり、datalake architectureでさえあれば、もう現代ではどのCloudを利用するかはあまりこだわらなくてもいいのかもしれない、と思えてきます。こうして転送さえしてしまえば、それぞれのCloudの専用のServiceを使えるわけですし。
そうすると、今後Cloud Platformはどういう風に差別化していくのかな、というのが気になってくるところです。簡単とはとてもいえないですが、類似機能はどんどん増えていくでしょうし。
じゃあ一体どんな点からCloud Platformを使い分けるのかと考えていくと、やっぱりそのCloudごとの得意分野に着目することになるんだろうなぁと思っています。
僕個人の感覚ですが、Web Serviceを作るならAWSに大抵のものがそろっているのですごく手軽です。Data解析だって、提供しているServiceの範囲で解決することなら、そこでやった方が手軽です。というのも、今回のbatch処理の入れ込みみたいに、設計段階での変更がいきなり入ってもServiceを組み合わせるだけでわりと簡単にすぐ試せるからです(新規作成の機能なら。動いているものの置き換えはまた別の話……)。
一方でGCPの便利さはGKEやBigQuery等のComputing Powerを盛大に使うときにすごく便利な気がしています。Data解析基盤としての道具一式がそろっている、という……。BigQuery MLなんかもありますしね。いじってみたいな。そうでなくてもGKEのようなものを使えば並列処理を気軽に組める気がします(実際にそういうものを組んだわけではないので印象論。実例とかあれば是非見てみたいな)。
しかしこうなってくると、もう、DBというのはData解析や集計のためのServiceであって、Dataを蓄積する最終到達点ではないのだな、蓄積の仕事はS3やGCSのようなStorageに役割が置き換わっているんだな、という気がしてきます。
Cloudが無かった頃と比べると、DBに求められる役割も少しずつ変わってきているのかも……と思うと結構な変化を感じました。
よし。楽しかった。いろいろ考えるところもあったし、ためになった。
次は何を作ろうかな(とか言ってたらなかなか重いtaskを抱えている本執筆現在なのだった)。
以上です。ここまでお付き合いいただきありがとうございました。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。









