
HRMOSプロダクトのPlatform SREチームは、採用、評価、サーベイなどマルチプロダクトな「HRMOS」シリーズの信頼性獲得、デリバリーパフォーマンスに対する横断的な改善活動に日々取り組んでいます。 改善活動を行う際には、多くのプロダクトや開発プロセスの中から何に注力すべきか、現状を正しく把握し判断する必要があります。 この記事ではデリバリーパフォーマンスに焦点を当て、指標としているFour Keys計測の仕組みとその活用事例について紹介します。
Four Keysとは
Four KeysはGoogleのDORAチームが明らかにした、組織の収益、生産性、従業員満足度等と相関のある指標および基準です。
- 変更リードタイム: コードがコミットされてから本番環境で正常に実行されるまでの時間
- デプロイ頻度: コードが本番環境にデプロイされた頻度
- サービス復元時間: 本番環境で障害が発生したときに、回復までにかかる時間
- 変更障害率: 変更によって本番環境で障害が起きた割合
組織のパフォーマンスを測る指標は他にもありますが、以下の理由からFour Keysを採用しました。
- ビジネス指標と相関がある。
- 定義が明確でわかりやすい。
- 指標が4つとシンプルであり計測コストが低い。
これは、計測を小さく始められ、さらに容易に組織全体に広げていくことを可能にします。 Four Keys計測はもともとSREメンバーの有志活動として始まっており、この性質はとてもマッチしていました。
各指標の計算方法
Four Keysの具体的な計算方法は、組織の開発フローや使用しているツールによって異なります。 「HRMOS」における計算方法を以下に紹介します。
変更リードタイム
「HRMOS」ではGitHubを使用しており、多くのプロダクトは以下のフローで開発を進めています。
- 複数のコミットを含むプルリクエストを作成する。
- プルリクエストをマージする。
- マージトリガーでGitHub Actionsのデプロイフローが実行される。
- 本番環境に変更がデプロイされる。
変更リードタイムは、GitHub Actionsの完了時刻と各コミットの作成時刻との差分を計算し、過去3か月間の中央値としました。
一部のプロダクトでは、GitHub Releasesを使って特定のタイミングでデプロイが行われる場合もあります。 その場合は、GitHub Actionsの完了時刻からそのリリースに含まれる各コミットの作成時刻との差分を計算します。
デプロイ頻度
DORAチームのドキュメントをみると以下のように書かれています。(ここでは翻訳したものを載せます。Monthly, Yearlyは省略します。)
Daily: 過去3か月間における、週あたりのデプロイ日数の中央値が3以上です。つまり、ほとんどの平日にデプロイが行われています。
Weekly: 過去3か月間における、週あたりのデプロイ日数の中央値が少なくとも1です。つまり、ほとんどの週には少なくとも1回はデプロイが行われています。
上記から、1週間のうちデプロイがあった日数を計算し、過去3か月間の中央値をデプロイ頻度としました。 GitHub Actionsの実行履歴から計算します。
なお、デプロイ頻度として、1日あたりのデプロイ数という指標も考えられますが、今回は以下の理由で採用しませんでした。
- 特定の期間で見たときに毎日2回デプロイと金曜日に10回デプロイが区別できない。
- DORAチームが公開しているDevOpsの能力の継続的デリバリーによれば、いつでもデプロイできる状態が重要とされている。
今後、1日あたりのデプロイ数やd/d/d等を計測する可能性はありますが、1週間のうちデプロイがあった日数と合わせて計測していく予定です。
サービス復元時間
障害が発生した時刻と解決した時刻との差分を計算し、過去3か月間の中央値をサービス復元時間としました。 「HRMOS」では障害管理システムとしてAtlassian Jiraを使用しています。 障害が発生すると以下の情報がJiraに登録されます。
- 障害の原因となるコミットが存在するリポジトリ名
- 障害の発生時刻
- 障害の解決時刻
変更障害率
過去3か月間の、障害の回数をデプロイ回数で割った値を変更障害率としました。 GitHub Actionsの実行履歴とJiraの障害情報から計算します。
計測の仕組み
次に、上記の計測を継続的に行う仕組みを構築します。
全体像は以下の図のようになります。
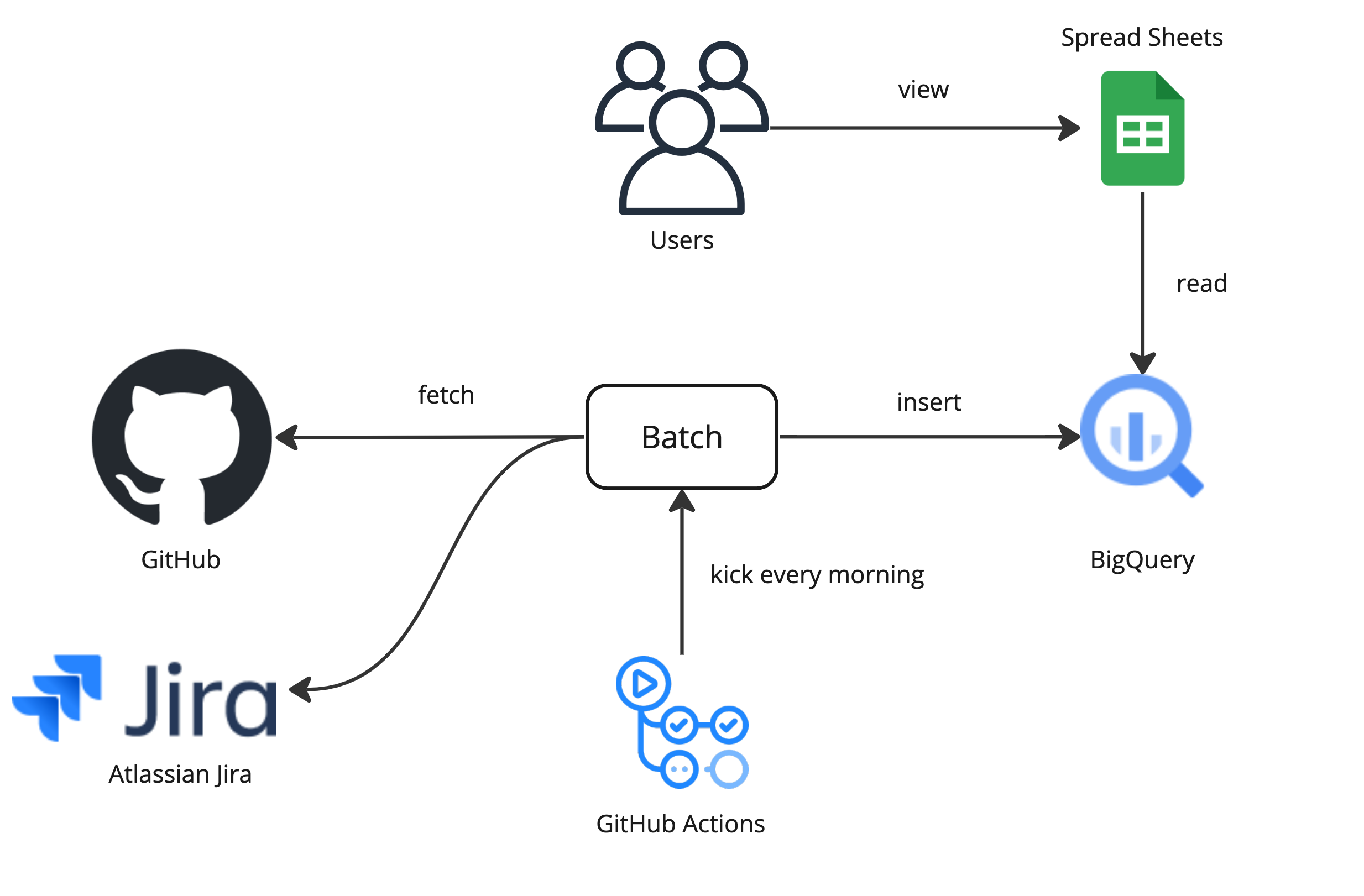
Batchプログラムで各種サービスからデータを取得し、BigQueryに格納します。 そして、SQLでFour Keysを計算し、Spread Sheetsなどを使って可視化を行います。
データ取得時に加工や計算などは行わず、計算に必要なデータを全てBigQueryに格納し、SQLでFour Keysを計算する方針を取りました。 以下の図は、BigQueryのテーブルとFour Keysの関係を示しています。
この記事では、計測の中心となる各テーブルおよびSQLによる計算方法に焦点を当てて説明します。
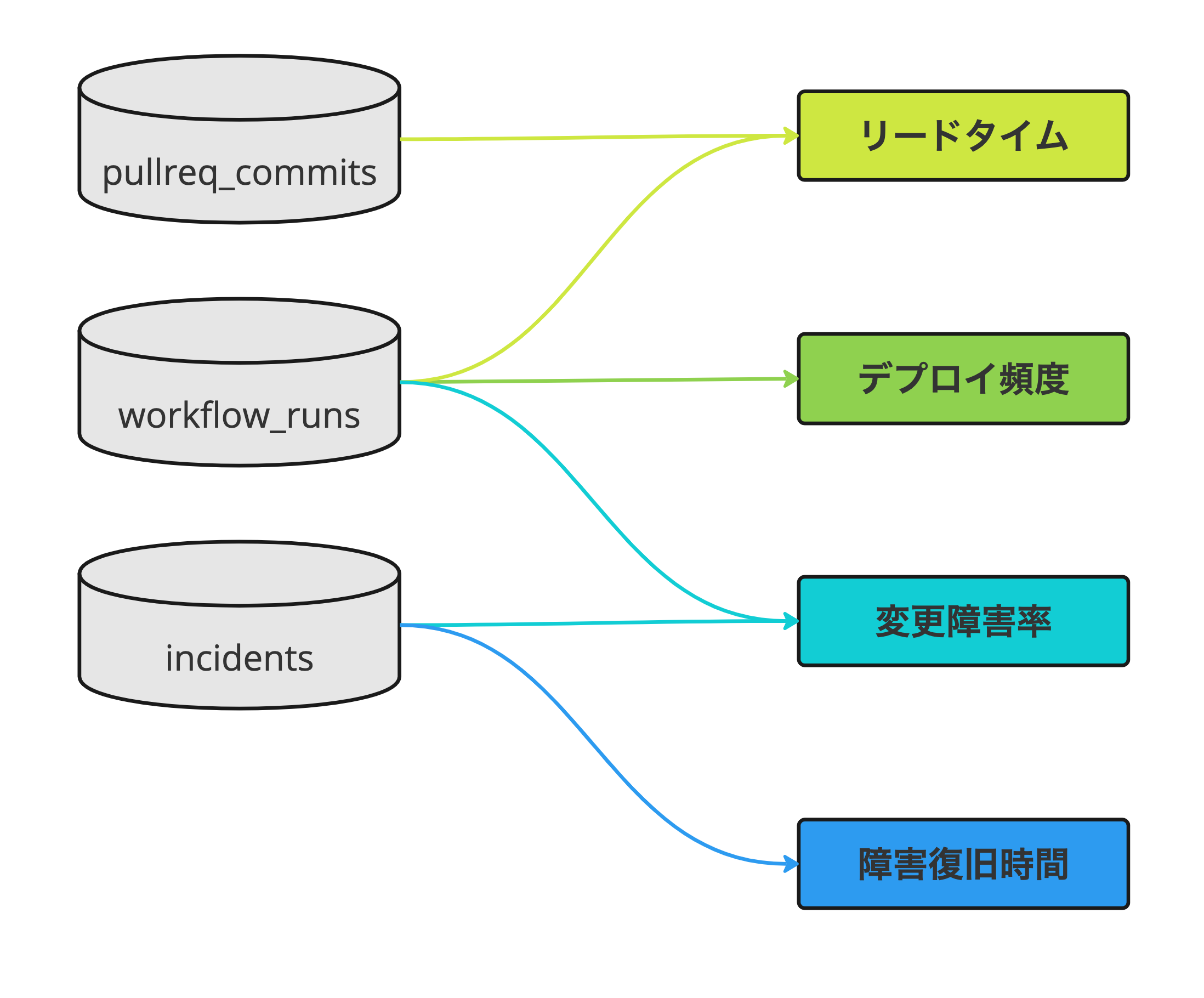
テーブル構造
まず、BigQueryのテーブル構造を示します。 主に計算に必要なフィールドを記載しています。
pullreq_commits
プルリクエストのコミット履歴を格納するテーブルです。
| フィールド名 | 種類 | 説明 |
|---|---|---|
| repository | STRING | リポジトリ名 |
| id | INTEGER | プルリクエストのID |
| title | STRING | プルリクエストのタイトル |
| merge_commit_sha | STRING | プルリクエストのマージコミットのSHA |
| sha | STRING | プルリクエストに含まれるコミットのSHA |
| committed_at | TIMESTAMP | コミットが作成された時刻 |
| merged_at | TIMESTAMP | プルリクエストがマージされた時刻 |
workflow_runs
GitHub Actionsの実行履歴を格納するテーブルです。 デプロイの実行履歴として利用します。
| フィールド名 | 種類 | 説明 |
|---|---|---|
| repository | STRING | リポジトリ名 |
| id | INTEGER | ワークフローのID |
| run_id | INTEGER | ワークフローの実行ID |
| head_sha | STRING | ワークフロー実行のトリガーとなったコミットのSHA |
| started_at | TIMESTAMP | ワークフローが開始した時刻 |
| completed_at | TIMESTAMP | ワークフローが完了した時刻 |
incidents
障害の情報を格納するテーブルです。
| フィールド名 | 種類 | 説明 |
|---|---|---|
| repository | STRING | リポジトリ名 |
| occurred_at | TIMESTAMP | 障害が発生した時刻 |
| resolved_at | TIMESTAMP | 障害が解決した時刻 |
Four Keysの計算
次に、Four Keysの計算を行うSQLを示します。
ここではプルリクエストのマージのタイミングでデプロイが行われる場合について説明します。 これらのSQLは説明のためのもので、実際よりも簡略化されています。
変更リードタイム
プルリクエストのコミット履歴とGitHub Actionsの実行履歴をJOINして計算します。
|
|
デプロイ頻度
まず、過去3か月のデプロイのあった日を抽出し、そこから各週に何回デプロイがあったかを計算します。
|
|
次に、過去3か月分の週のカレンダーを生成します。
|
|
カレンダーとデプロイ日数をLEFT JOINして、デプロイがなかった週のデプロイ日数を0とします。
|
|
これで、各週のデプロイ日数が計算できました。 結果は以下のようになります。
| week | days |
|---|---|
| 2023-04-09 | 3 |
| 2023-04-16 | 0 |
| 2023-04-23 | 0 |
| 2023-05-30 | 4 |
| 2023-05-07 | 4 |
| … | … |
最後に中央値を計算します。
|
|
サービス復元時間
incidentsテーブルのデータを使って計算します。 障害が発生した時刻と解決した時刻との差分を計算し、過去3か月の中央値を計算します。
|
|
変更失敗率
過去3か月の障害の発生回数とデプロイ回数をそれぞれ集計し、失敗率を計算します。
|
|
活用事例
計測結果
実際に計測した結果、多くのチームがエリートまたはハイパフォーマーの基準に達しており、「HRMOS」の開発組織は全体的にパフォーマンスが高いことがわかりました。 一方、いくつかのチームで変更リードタイムがミディアム(コミットからデプロイまでに1週間以上)でした。 今回はこの変更リードタイムについて分析します。
変更リードタイムの分析
変更リードタイムがミディアムのチームについて、各リポジトリへのコミットの割合および各リポジトリの変更リードタイムの内訳を調べました。 (実際の分析では、他にもいくつかのデータの可視化を行っています。ここではわかりやすく説明できるグラフを2つ選んでいます。)


この2つのグラフから以下が読み取れます。
- 各チームともリポジトリAへのコミットの割合が多い。
- リポジトリAはマージしてからデプロイされるまでの時間の割合が多い。
したがって、各チームで個別に検討・実施する必要はなく、リポジトリAに対して改善を行えば、全てのチームの変更リードタイムを改善できる可能性があることがわかります。
「HRMOS」の多くのプロダクトはプルリクエストベースのデプロイフローを採用しており、プルリクエストがマージされたタイミングで本番環境にも変更がデプロイされます。 一方、リポジトリAに含まれるプロダクトに関しては、あらかじめ決められた日にデプロイするフローとなっており、小さな変更でも次のデプロイ日まで待つ必要がありました。 この待ち時間が、各チームのパフォーマンスを阻害している要因であることが明らかになりました。
今後の展望
DORAチームは、Four Keysと関連するDevOpsの能力を公開しています。 その中の一つである継続的デリバリーについて、以下のように述べられています。(強調は筆者によるものです。)
継続的デリバリーは、すべての変更を必要に応じて、迅速に、安全に、かつ継続的にリリースする機能です。継続的デリバリーをうまく実践するチームは、ユーザーに影響を与えることなく、通常の営業時間を含むあらゆるタイミングで、ソフトウェアをリリースし、本番環境に変更を加えることができます。
この継続的デリバリー能力の獲得(例えば、他のプロダクトと同様にプルリクエストベースのデプロイフローに変更する。)が、私たちの次のアクションになると考えています。
また、今回紹介したこれらの仕組みは、弊社で取り組んでいるSODA構想(SODA : Software Outcome Delivery Architecture)のデータソースの一つとして活用され、「HRMOS」だけでなく企業レベルで状況把握や課題発見に活用される予定です。
まとめ
この記事では、Four Keysの計測方法、仕組み、および分析によってパフォーマンスを阻害している要因を特定する事例について紹介しました。 開発組織におけるパフォーマンス改善を行おうとしている方の参考になれば幸いです。
「HRMOS」では定量的な測定に基づく改善活動を行なっています。 少しでも興味をお持ちいただいた方は、ぜひご連絡ください!
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










