
ビズリーチの検索基盤グループ(以降、検索基盤G)でマネージャーをしている山本です。
私たち検索基盤Gは、検索技術や生成AIを活用し、「ビズリーチ」におけるマッチング機会の質を向上させることをミッションとしています。
HR領域の検索には「企業と求職者の双方が選び合う」という特有の難しさがあります。 私たちの取り組みをより深く知っていただく前提として、本記事ではこの難しさの背景にある課題の全体像をご紹介します。HR領域のマッチング全体の構造的な課題から、現場の実務的な課題、そしてシステム実装の技術的な課題へと、段階的に掘り下げていきます。
- HR領域のマッチングに共通する課題
- 採用担当者の課題
- システムの課題
1. HR領域のマッチング機会創出に共通する課題
HR領域のマッチング(以降、HRマッチング)は、企業と求職者が互いに選び合うプロセスです。以下のように双方の行動が段階的に収束し、その中央でマッチングが始まります。
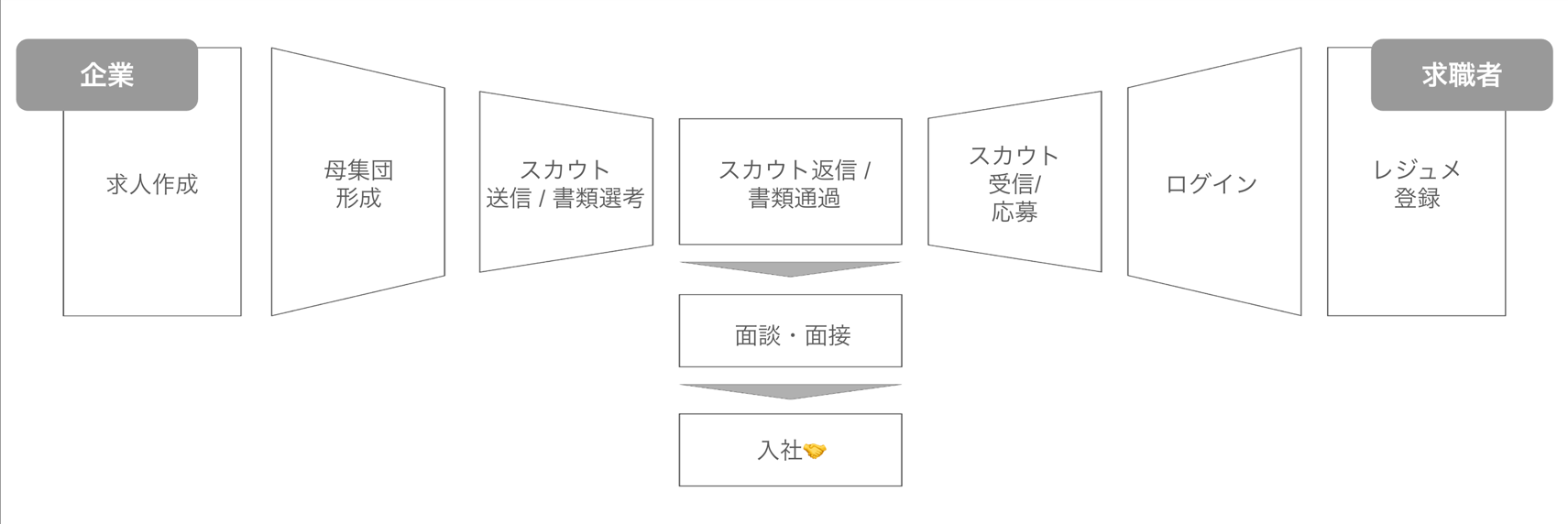
「ビズリーチ」であれば、以下のいずれかが起点となりマッチング機会が創出されます。
- スカウト返信: 企業が求職者にスカウトを送り、求職者がそれに返信する
- 書類通過: 求職者が求人に応募し、企業が書類選考を合格とする
その後、面談・面接の過程で双方によるスクリーニングが行われ、最終的に内定・入社に至ります。
この前提を踏まえ、HRマッチングにおける代表的な課題を紹介します。
1-1. 企業と求職者、双方の意思決定を考慮する必要性
HRマッチングの特徴を理解するため、まずECサイトと比較してみます。
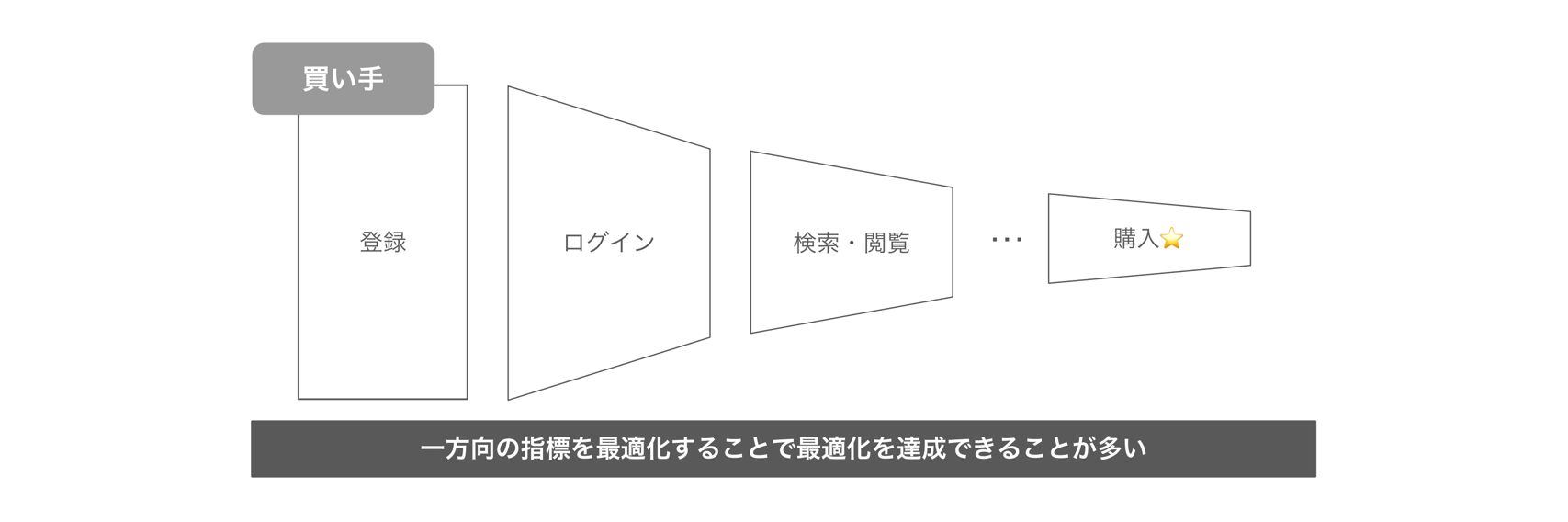
ECサイトでは「購入率」を高めることが重要な目標です。 ユーザーが欲しいと思う商品を上位に表示することで、検索・閲覧から購入に至る確率を高めることができます。 この場合、意思決定を行うのは買い手のみであり、片方の指標を最適化することで目標を達成できます。
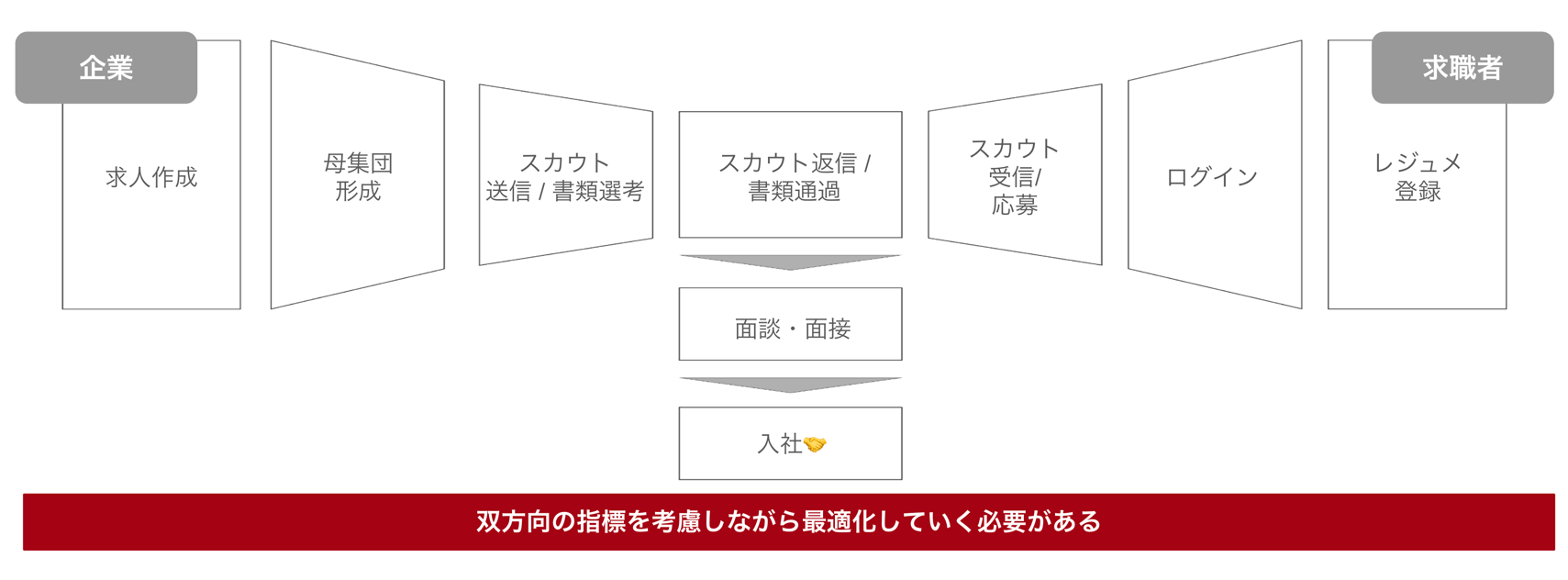
一方、HRマッチングでは企業と求職者の双方が能動的に意思決定を行うため、片方の指標に最適化しすぎると、もう片方の指標が下がってしまう可能性があります。
| 最適化対象 | 結果 | 問題点 |
|---|---|---|
| 企業視点で「スカウト送信数」を最大化 | 求職者に興味のない求人が増加 | スカウト返信率が低下 |
| 求職者視点で「応募数」を最大化 | 企業の要件に合わない応募が増加 | 書類通過率が低下 |
マッチング機会を最大化するためには、以下の2つの条件を同時に満たす必要があります。
- 企業側が「ぜひ会いたい」と思うこと
- 求職者側が「ぜひ選考に進んでみたい」と思うこと
さらに理想を言えば、面談・面接で判断されるスキルやカルチャーの合致度、入社後の活躍までを考慮すべきです。 この長期的な時間軸も見据えたマッチングはHRマッチング従事者が挑戦し続ける課題であり、研究開発領域でもあります。
2. 採用担当者の課題
「ビズリーチ」は、求職者からの「応募」だけでなく、企業の採用担当者による「スカウト」が起点となることが多いです。 そのため、採用担当者が求職者を見つけ出し、スカウトを送るまでの一連の活動、いわゆる「母集団形成」がマッチング機会の質を大きく左右します。
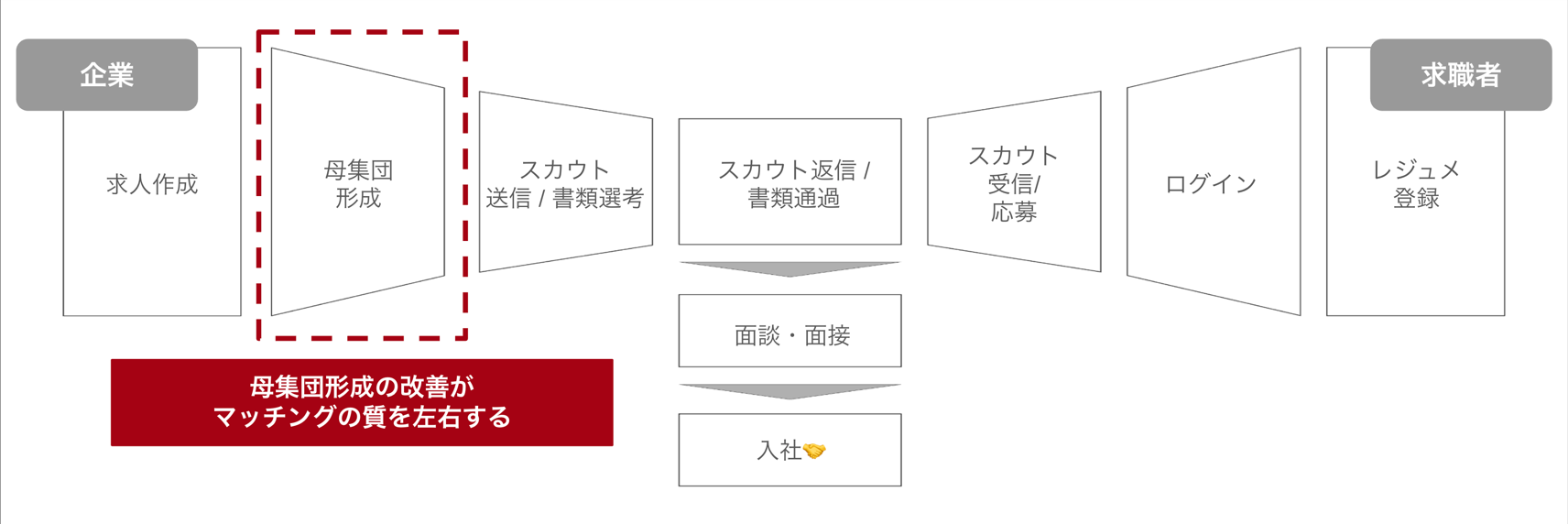
採用担当者の母集団形成プロセス(4ステップ)
母集団形成は、大きく以下の4ステップで構成されます。
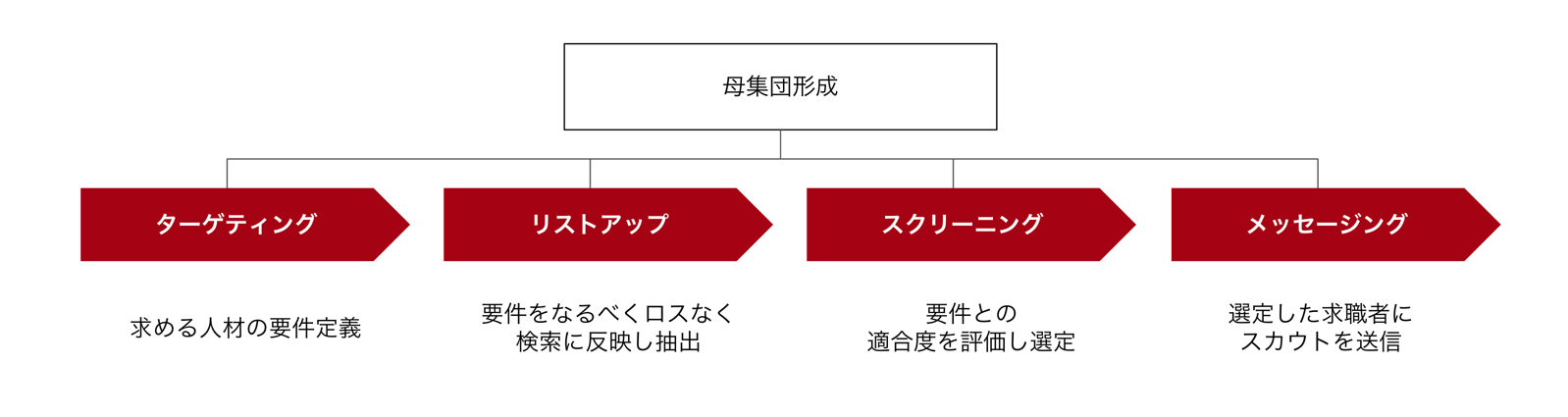
ここからは、具体的なケースを通じて、各ステップでどのような課題が生じるのかを考えてみます。
ケース: RAG開発エンジニアの採用
ある日、事業責任者から採用担当者(エンジニア採用未経験)に下記の依頼が来ました。
事業責任者: 「生成AIを活用した新規事業を始めるから、RAGを用いたアプリケーションを作れるエンジニアを採用してほしい」
この依頼を受けた採用担当者が、4ステップを進める中でどのような課題に直面するのか、順を追って見ていきます。
※以降の例は仮想的なHRサービスでのケースであり、弊社サービスの実データではありません
2-1. ターゲティング: 曖昧な人材要件を検索条件に落とし込む難しさ
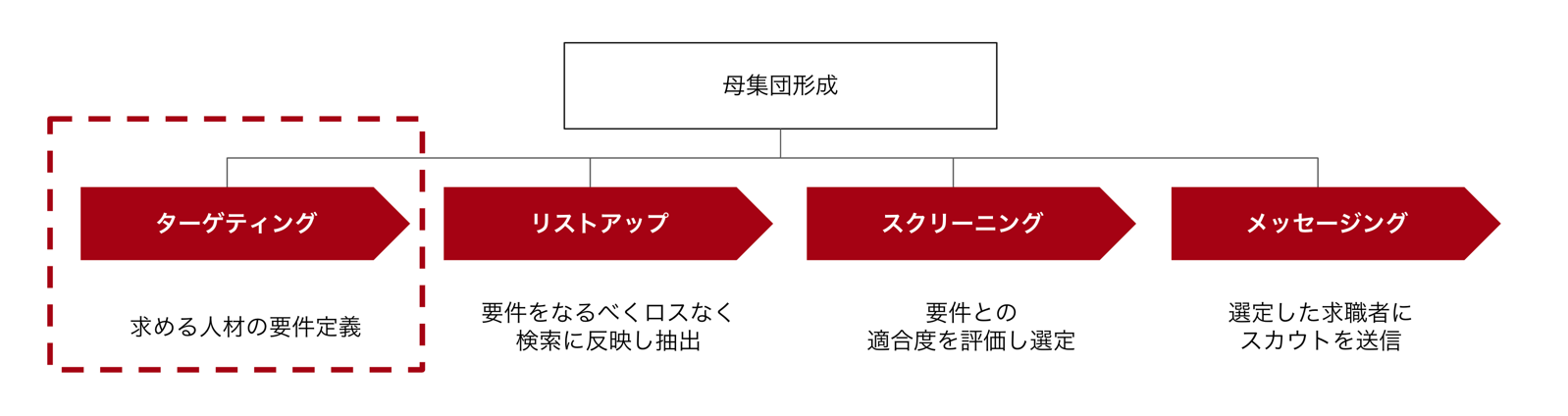
ターゲティングとは、「どんな人を採用したいか」という人材要件を定義するステップです。さらにこの要件を検索条件に落とし込む必要があります。
採用担当者は、事業責任者から以下の要件を受け取りました。
事業責任者: 「RAGの開発運用経験があって、ベクトルDBの運用経験もあって、モデル開発もできる人。年収は600-1000万くらいで、カルチャーフィットしそうな人が良い」
採用担当者: 「RAG…? ベクトルDB…? まず何を検索すればいいんだろう?」
エンジニア採用未経験で知識も乏しく、曖昧な要件を検索条件に変換する際に以下のように悩みました。
| 要件 | 検索条件への変換課題 |
|---|---|
| RAG開発運用経験 | どのキーワードで検索すべきか?(「RAG」だけ?「ベクトルDB」「LLM」も含めたほうがいい?) |
| モデル開発 | どこまでの範囲を指すのか?(研究レベル?本番運用レベル?) |
| カルチャーフィット | どう検索条件に反映するのか?(うちのカルチャーって?職務経歴にどう現れる?) |
人材要件は抽象・曖昧なことが多く、システムが理解できる具体的な検索条件に変換する必要があり、多くの場合、最初に直面する課題となります。
2-2. リストアップ: 検索条件の調整における網羅性と確認コストのトレードオフ
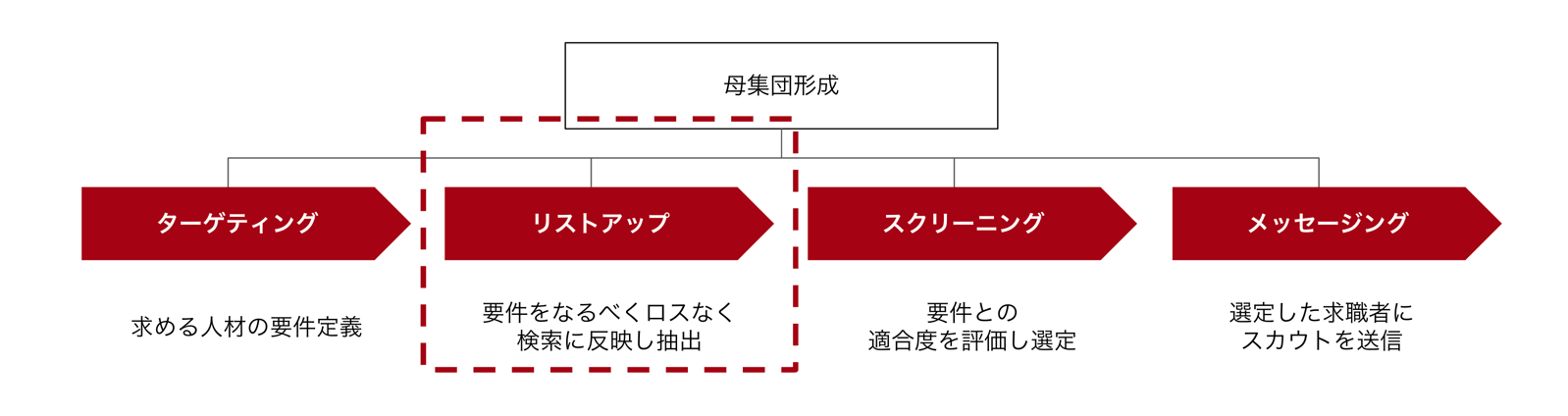
リストアップとは、定義した要件をなるべく取りこぼさない(ロスしない)よう検索条件を調整しながら、スカウト対象となる求職者を抽出するステップです。
採用担当者は、実際に検索をしてみると、2つの要求のトレードオフに悩みながら検索条件を調整することになります。
- 出会うべき求職者を見逃したくない
- 求職者を確認するコストを下げたい
そして以下のような検索条件の試行錯誤を行います。
| 検索条件 | ヒット件数 | 採用担当者の心の声 |
|---|---|---|
| 「RAG」「ベクトルDB」「モデル開発」すべて必須 | 15件 | 「求職者が少なすぎる。もっと広げるべきか?」 |
| 「RAG」OR「ベクトルDB」OR「LLM」OR「機械学習」 | 800件 | 「増えすぎた。全部は確認できない…」 |
検索条件をAND条件にすると求職者が少なすぎ、OR条件では多すぎるなど、適切なバランスを見つけることが難しい場面が多くあります。
要件を適切に検索条件に反映し、確認コストとのバランスを取ることは、経験と勘に頼ることが多く、ドメイン知識がない領域では特に難しいです。
2-3. スクリーニング: 職務経歴書の文脈を読み解き、求職者との適合性を判断する難しさ
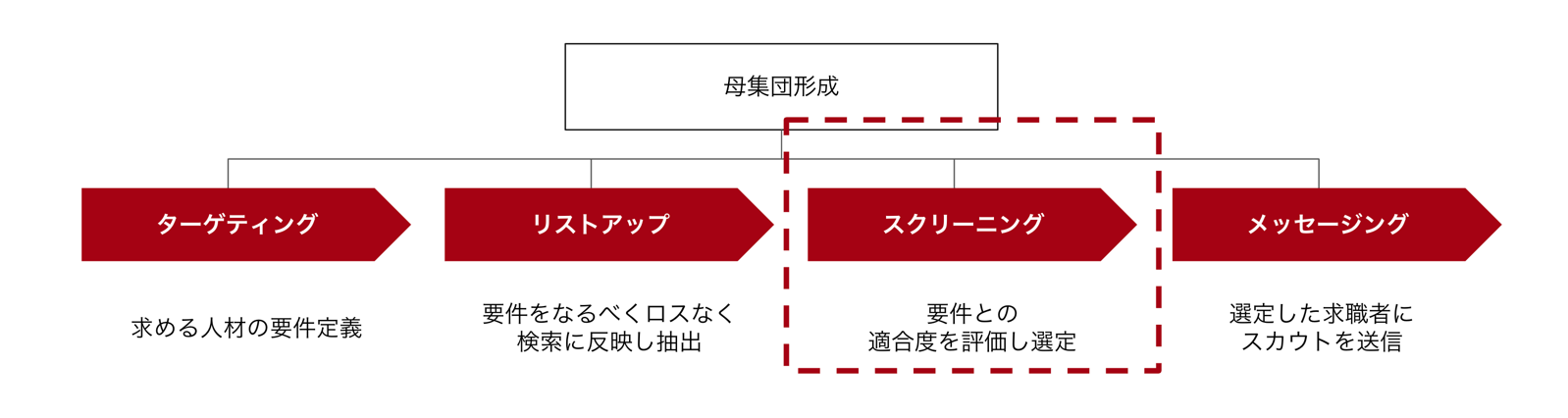
スクリーニングとは、リストアップした求職者の職務経歴と要件との適合度を評価し、スカウト対象者を選定するステップです。
職務経歴書はフォーマットや表現の粒度が様々で、同じキーワードでも文脈で意味が変わります。
例えば、以下の2人の求職者がいたとします。
- 求職者A: 「月間100万クエリを処理する本番環境でRAGを開発・運用」(希望年収: 1200万円)
- 求職者B: 「社内ドキュメント検索の試作でRAGを検証」(希望年収: 800万円)
いずれも “RAG” というキーワードを含みますが、採用担当者は以下のように悩みます。
「求職者Aは明らかに経験豊富だけど、希望年収1200万円は予算オーバー…。求職者Bなら年収800万円で予算内だけど、この実験レベルの経験で事業責任者が求める要件を満たせるのだろうか?」
採用担当者は、企業側の求める要件を深く理解しつつ、求職者の職務経歴の裏にある経験レベルを読み取る必要があります。
さらに、年収や他の条件との兼ね合いも考慮しながら、この双方のコンテキストの適合度を判断することは高度な業務であり、日に何十、何百という職務経歴書と向き合う中で大きな負荷となります。
2-4. メッセージングによる仮説検証: 試行錯誤しながら人材要件を明確にしていく難しさ
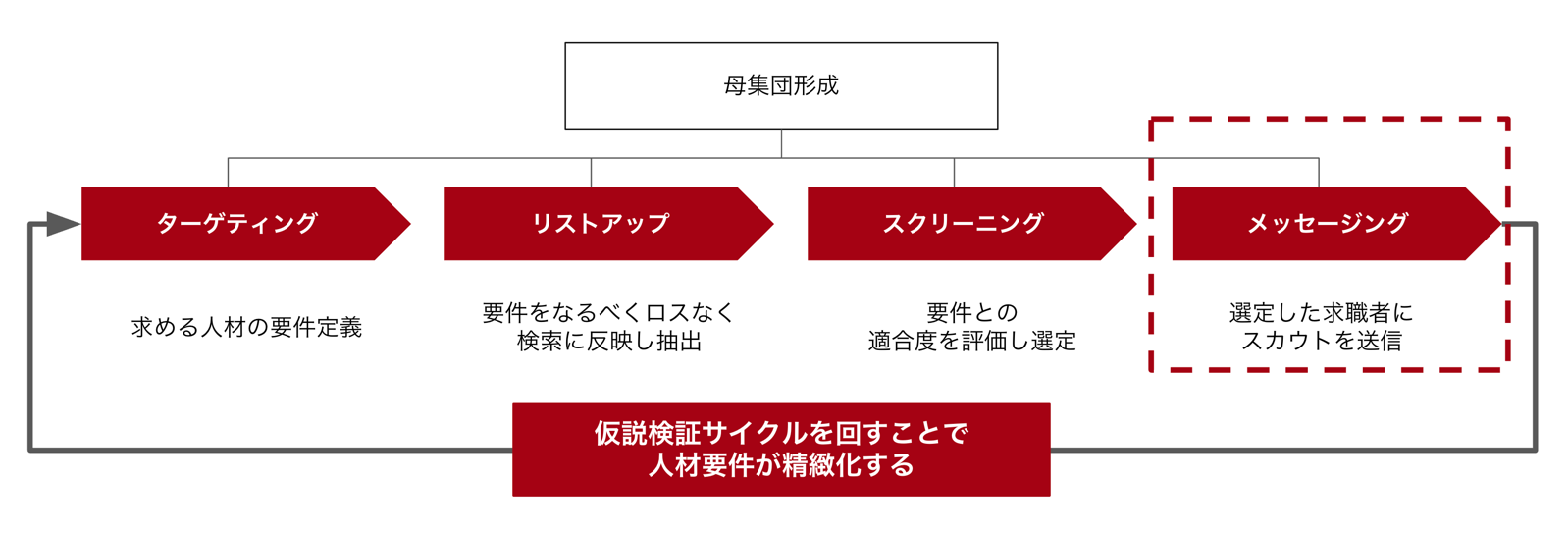
メッセージングとは、スクリーニングで選定した求職者にスカウトを送信するステップです。 そして、スカウトへの反応(返信の有無など)をもとにターゲティングから4ステップを回し直す。この仮説検証サイクルによって、人材要件が精緻化されていきます。
例えば採用担当者は以下のような学びを得て、次のアクションにつなげていける可能性があります。
| 学び | アクション |
|---|---|
| 要件の現実性: 「モデル開発」まで求めると求職者がほぼいない | 要件から外す |
| 市場の相場観: RAGを本番適用した経験者は年収1000-1500万円を希望 | 年収レンジを見直す |
| 代替となる人材像: 関連スキル保有者からも関心が示された | スカウト対象を広げる |
今回のケースのようにドメイン知識が乏しい領域の場合、最初から上手くいくことは稀です。
採用担当者が、限られた時間の中でこのサイクルをいかに効率的に回せるかは、採用成功の可能性を大きく左右します。
3. システムの課題
2章で紹介した母集団形成課題に対して検索システムを構築するにあたり、技術的にも多くの課題があります。 ここでは、その中でも特に重要な課題をいくつか紹介します。
3-1. 多様な検索ニーズに対応し、求職者を網羅的に抽出する
HRマッチングは採用決定までのファネルが長く、特にスカウト送信から返信までの段階で大きく絞り込まれます。 そのため、母集団形成フェーズでは十分な求職者を集める必要があり、検索システムには後段に進む可能性のある求職者を漏れなく抽出する高いRecall(再現率)が求められます。
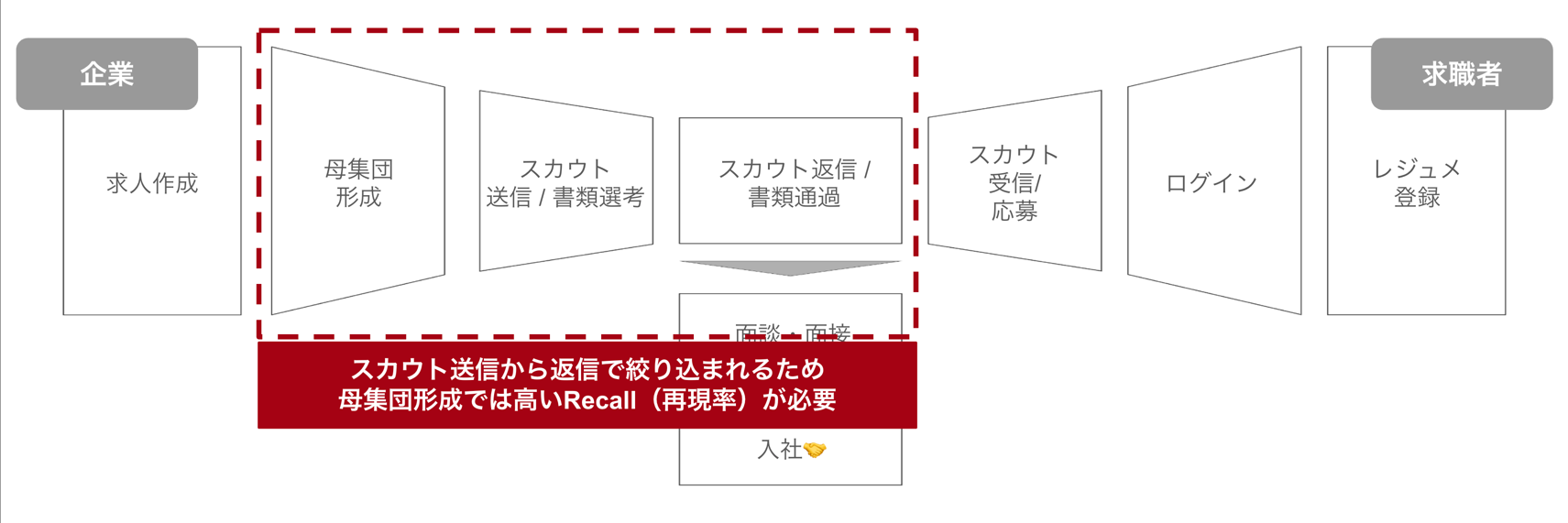
2-2で見たように、採用担当者は「RAG」エンジニアを探す際、「RAG」というキーワードだけでなく、「ベクトルDB運用」や「検索システム設計」といった関連する経験を持つ求職者も探す必要がありました。
これらの検索ニーズをクエリとして表現すると、明確なものと曖昧なものが混在し、単一の検索手法では十分なRecallを確保できません。
| クエリの性質 | 適した検索手法 | 具体例 |
|---|---|---|
| 明確 | 厳密な一致検索 | 「RAG」のような明確なスキルを厳密にマッチ |
| 曖昧 | セマンティック検索 | 「新規事業の推進者」→「0→1の経験」「スタートアップ経験」 「RAGの関連経験」→「ベクトルDB運用」「検索システム設計」 |
そのため、厳密な一致検索とセマンティック検索の両方を組み合わせたアプローチが必要になってきます。
3-2. 企業と求職者の双方にとっての価値を最大化するランキング
3-1で求職者を網羅的に抽出するだけでは、マッチング機会を最大化させることは難しいです。 要件がマッチする可能性が高い求職者を上位に提示するPrecision(適合率)が求められます。
このようなランキングを実現するには、以下の技術的課題があります。
課題1: 双方向性を考慮したスコアリング
1-1で述べたように、HRマッチングでは企業と求職者の双方の意思決定を考慮する必要があり、以下のような論点を考慮したスコアリングが必要です。
- 企業側指標と求職者側指標の重み付けをどう決定するか
- 双方で相反が発生する指標をどう扱うか
- 双方のスコアを最適化する統合関数をどうするか
双方向のスコアをどのように統合するかは、システム設計における重要な技術的課題となります。
課題2: 多様なデータを統合した適合度評価
HRマッチングでは求職者と企業双方に、下記のようなデータが混在します。
- カテゴリ値(スキル、年齢、勤務地)
- テキスト(職務経歴)
- 行動ログ(最近のログイン、返信履歴など)
具体例として以下のデータを考えてみます。
| データ | |
|---|---|
| 求職者の職務経歴書 | スキル: Java, Spring 希望勤務地: 東京都 職務要約: 「ECサイトのサーバーサイド開発を5年担当。」 |
| 企業の求人 | 勤務地: 東京都 要件: 「バックエンド開発経験が3年以上あること。」 |
勤務地のような構造化可能なデータであれば一致判定が容易です。 一方で、「Java, Spring」と「バックエンド開発経験」や「サーバーサイド開発5年」と「バックエンド開発経験3年以上」といった、性質や表現が異なるデータから適合度を評価するには工夫が必要になります。
非構造化データを上手く構造化データに変換したり、これらを一つの埋め込み表現として統合できるようなマルチモーダルなモデルを実装するなどして、適合度を算出する必要があります。
3-3. 応答速度と検索精度の両立
3-1、3-2の実現にあたっては、ベクトル検索などの意味理解を伴う検索技術が必要になってきます。
一方で、採用担当者は検索を繰り返し試行錯誤するため、ユーザー体験を損なわない応答速度と高精度な検索結果を両立させる、下記のようなアプローチが求められます。
- 多段階フェーズな検索アーキテクチャによる高速化と精緻な評価の両立
- 蒸留による低次元化やSparse Vector検索によるベクトル検索の高速化
課題を踏まえた検索基盤Gの取り組み
3章の課題に対して、検索基盤Gでは様々な実装や研究開発を進めてきました。 以下はその一部です。
| 取り組み | 概要 | 参考 |
|---|---|---|
| ランキング改善 | 企業と求職者の双方の指標を考慮したランキングロジックの継続的改善 | - |
| ベクトルランキング | 独自のアプローチで意味的な類似度をランキングに統合 | Qdrantを用いた検索改善施策の紹介 |
| インターリービング | 複数のランキングアルゴリズムをオンラインで比較評価する手法を導入 | 検索ランキングの比較のためにInterleavingの導入と評価をした際の工夫 |
| SPLADE | Sparse Vector検索モデルをベースにした検索モデルの研究開発 | light-splade |
Sparse Vector検索モデル(SPLADE)の研究開発
その中でも、SPLADEについて簡単に紹介します。 SPLADEは、BERTなどのTransformerモデルを用いて、文書やクエリの重要な単語を強調したSparse Vector(疎なベクトル)を生成するモデルです。 Dense Vector(密なベクトル)と比較して、以下の特徴があります。
- 転置インデックスを活用した高速な検索が可能
- どの単語が重要視されたかを解釈しやすい
このSPLADEの特性は、3章で述べた課題に対して以下のように寄与します。
- 3-1(Recall): 単語の完全一致に頼らず、意味的に関連する求職者を網羅的に抽出可能
- 3-2(Precision): 職務経歴書の検索条件の文脈を理解した適合度評価が可能
- 3-3(応答速度と精度の両立): Sparse Vector表現により転置インデックスを用いた効率的な計算が可能
SPLADEの詳細については、日本語に対応したSPLADEモデルの公開をご覧ください。
まとめ
本記事では、HRマッチングの構造的な課題から、採用担当者の実務的な課題、そしてシステムの技術的課題まで、検索基盤Gが向き合う課題の全体像を紹介しました。
これらに対し、ランキング改善やSPLADEをベースにしたベクトル検索など、様々な取り組みを進めています。 この取り組みに興味を持っていただけましたら、ぜひ一度お話しさせてください。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。









