Stefan Meier is Lead Engineer at Stanby - the search engine division at BizReach, Inc. Today, he explains why Stanby is moving from Amazon Web Services (AWS) to Google Cloud Platform (GCP) for data analysis.
What is the challenge with big data?
“Big data is data sets that are so voluminous and complex that traditional data-processing application software [is] inadequate to deal with them."1
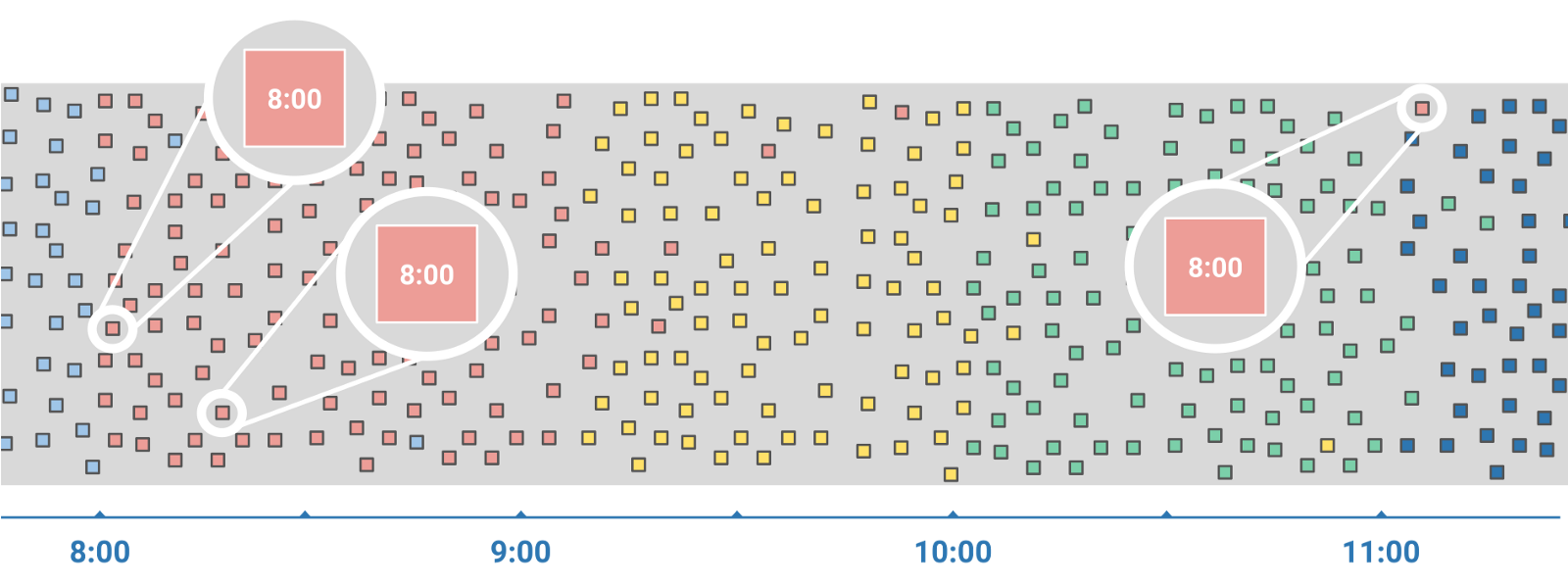
One of the most fundamental principles lies in the discrimination between streaming and batch processing. In batch processing, a set of events is collected over time and then processed later, whereas in the streaming model, data is processed in near real-time. Also, when dealing with streaming data new challenges appear, such as handling unordered data with unknown delays (see graph below). Indeed, the collected data events might originate from users with slow Internet connections, users accessing the site from multiple devices or there might be just network delays. Therefore, the gap between the time the event occurred (event time) and the time the event is observed by the system (processing time) ranges from a few milliseconds up to several hours. In order to combine and group related data, methods such as windowing are used.
2 Streaming data
Additional aspects when dealing with big data are:
- Removing the noise before processing the data (i.e. only process meaningful data).
- Breaking down the different problems (or steps) into small problems (and smaller sets of data) that are easier to process and need less computing resources (see also divide and conquer). Even if big data infrastructure becomes more and more performing, the problem should be broken down in order to decrease processing time and cost.
What is Google Dataflow?
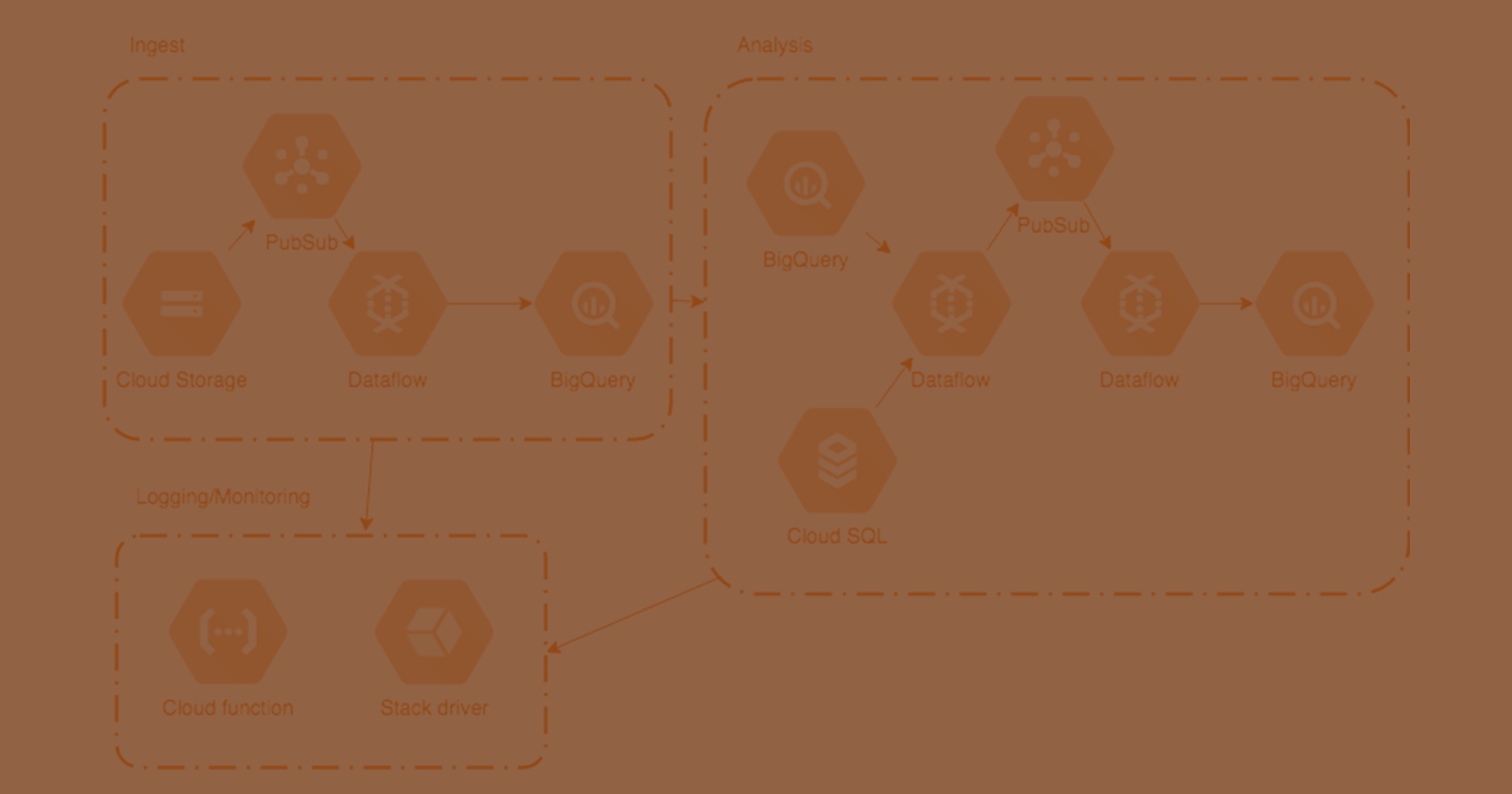
One of the products that one might think of first is BigQuery - a serverless, highly scalable data warehouse. However, the Google ecosystem contains many other services related to big data. Most of them are fully managed services that integrate seamlessly with each other. Therefore, in most cases, there is no need to think about infrastructure management.
Google Dataflow is one such fully managed service related to big data analysis. Its main features are auto-scaling and the unified programming model for streaming data and batch processing: The Apache Beam SDK. Compared to Hadoop for example, there is no need to address common aspects of running jobs on clusters (e.g. work balancing, scaling, etc.) since it is automatically managed. Also, the unified programming model abstracts the code from the runner and enables application engineers to focus on the logic without thinking about the infrastructure. This makes the code runnable on different runners, including Spark. Currently, Apache Beam supports Java, Scala, Python and Go. However, the latter two don’t cover the whole SDK yet (as of July 2018). As a service, Dataflow integrates with BigQuery, Pub/Sub, Cloud Storage and Cloud SQL, which makes it a core service.
How did Stanby manage big data in the past?
At Stanby, we are accumulating a massive amount of data points every day, broadly categorized into two categories:
- Business-related data, such as search quality, search engine usage, user behavior, SEO, and advertisement.
- Service-related data, such as infrastructure and application logs.
Prior to moving to the Google Cloud Platform (GCP) for data processing, we relied solely on AWS infrastructure for processing and analyzing.

This workflow is based on the following technologies and tools:
- AWS S3 for data storing
- AWS EMR for combining/cleaning data in Hadoop clusters
- Apache Airflow for scheduling tasks and data pipelines
- AWS Athena for preparing data for visualization
In addition, we used Elasticsearch and Kibana for logging and service monitoring.
In the current workflow, we had to deal with various challenges:
- Application engineers are dependent on infrastructure engineers when working with big data for managing the runners (e.g. infrastructure scaling, modifying pipelines, testing new features or services, etc.)
- Laborious process of updating existing workflow/processing logic
- Log data becomes too voluminous to manage in Elasticsearch
- Impossible to connect with data stored in Google services (Google Analytics, Adwords, Search console, etc.)
Why did we move to the Google Cloud Platform?
In order to solve the problems mentioned, we started looking for alternative services and solutions. Since we mainly build programs with Scala, we were looking for a technology or a tool that is well used and that would not take too much time to learn and to adapt.
We finally came up with a solution that fits our needs best: Use AWS in combination with GCP. The former is used for managing the existing infrastructure, the latter for processing big data.

The new workflow is based on the following technologies/tools:
- Google Transfer Service (for batch processing) or AWS Lambda (for real-time processing) for transferring data from AWS S3 to Cloud Storage
- Cloud Dataflow to process/analyze the data
- BigQuery as the data warehouse (also as a replacement of logs in Elasticsearch)
- Apache Beam Model and Scio from Spotify as the programming framework
- Redash and Google Data Studio for visualization
- Stackdriver and Cloud functions for logging/monitoring of GCP services
With the new workflow, we are able to use the strength of AWS and GCP. Indeed, GCP has many advantages regarding big data, especially the fact that application engineers don’t depend on infrastructure engineers and can focus on implementing new solutions. Also, the Apache Beam SDK makes it easy to combine streaming and batch processing. Nevertheless, AWS remains as the main service that we use for the infrastructure. Even if we are very happy with GCP, there are many features available in AWS which are currently not available in GCP (especially in terms of networking and security).
Key results
By refining our data analytics strategy and moving from AWS to GCP for big data processing, we gained the following key benefits:
- Application Engineers can focus on enhancing big data analytics workflows without relying on infrastructure engineers
- Decrease infrastructure complexity
- Decrease the amount of code by moving code from Spark to Apache Beam (because of the unified programming model for batch and streaming)
- Benefits of the Google ecosystem
- Connection with Google Analytics and other Google services related to SEO and search
At Stanby, we will continue to actively develop data pipelines with Dataflow and move big data processing to the GCP ecosystem. We are for example working on moving our logging data pipeline from Elasticsearch/Kibana to BigQuery.
References
- 1 Wikipedia, (https://en.wikipedia.org/wiki/Big_data), fetched on 2018/07/11
- 2 Medium, Give meaning to 100 billion analytics, fetched on 2018/07/03







