
本記事は、情報検索・検索技術Advent Calendar 2025 の15日目の記事です。
はじめに
ビズリーチの検索基盤グループで機械学習エンジニアをしている渡會です。
近年、ベクトル検索エンジンとニューラルネットワークを組み合わせたセマンティック検索が急速に普及しています。その中でも、キーワード検索の解釈性とニューラルネットワークの表現力を兼ね備えたSparse Vector Search(疎ベクトル検索) への注目が高まっています。
これまで私たちのチームでは、日本語特化のSparse Embeddingモデルであるlight-spladeの公開や、Qdrantを用いたDense Vector Searchの活用事例など、検索領域における企業と求職者のマッチング機会を創出するための課題解決の取り組みを発信してきました。
本記事では、これらの知見を踏まえた応用編として、Vector DatabaseであるQdrantのSparse Vector機能とSPLADEモデルを組み合わせた、実践的な検索システムの実装例を紹介します。
アジェンダ
- Sparse Vector Searchの基礎: Inverted IndexとSparse Vectorの仕組み
- 構成要素の紹介: SPLADE (モデル) とQdrant (Vector Database)
- アーキテクチャ: 検索処理の全体像とデータフロー
- 実装: light-spladeとQdrantを用いた具体的なコード例
- 実用化のポイント: 導入に向けた検討事項
1. Sparse Vector Searchの基礎
ベクトル検索は、Dense Vector(密ベクトル)を用いたセマンティック検索が主流ですが、厳密なキーワード一致や、学習データに含まれない専門用語の検索においては課題が残ります。
例えば、人材マッチングにおいて、ニュアンスが似ているだけの求人やスキルがヒットしてはミスマッチにつながるため、条件に合致するキーワードをピンポイントで捉えたいケースなどがこれに当たります。
そこで、これらの弱点を補いつつキーワード検索の強みを活かせるSparse Vector(疎ベクトル)検索が再び注目されています。まずはその仕組みを整理します。
1-1. Sparse Vector(疎ベクトル)とは
Sparse Vectorとは、多くの要素がゼロで構成されるベクトルのことです。 実際は数万次元になりますが、簡略化した例として、12次元のベクトルで表現すると以下のようになります。
例:
[0, 0, 3.5, 0, 0, 0, 1.2, 0, 0, 0, 0, 4.7](ほとんどが0で、特定の要素のみが値を持ちます)
Sparse Vectorの特徴として以下が挙げられます。
- 解釈可能性: 各次元が「単語(語彙)」に対応するため、どの単語が重要視されたかが人間にも理解しやすい。
- 現実の反映: ドキュメントに関連する語彙のみが反映されるため、情報の表現として自然です。
- 親和性: 従来の全文検索技術である「転置インデックス」をそのまま活用できる。
1-2. Inverted Index(転置インデックス)による高速化
Inverted Index(転置インデックス)は、キーワード検索エンジンで広く用いられるデータ構造です。以下の図のように、各単語(特徴量)に対して、その単語が出現するドキュメントIDのリストを保持します。
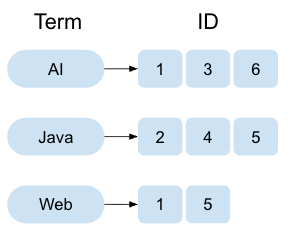
Inverted Indexの特徴として以下が挙げられます。
- 構造: 各特徴量(単語/次元)に対し、「その値が非ゼロであるドキュメントIDのリスト」を保持します。
- 検索: クエリに含まれる非ゼロの要素に対応するドキュメントのみをリストから取得し、スコア計算を行います。これにより、全件走査を回避し、高速な検索を実現します。
Sparse Vector Searchは、多くの要素がゼロである特性を利用し、Inverted Indexを用いて実装されます。これにより、キーワード検索の高速性とニューラルネットワークの表現力を両立できます。
2. 構成要素の紹介
今回は、Sparse Vector Searchを実現するために以下の2つの技術を採用します。
- SPLADE
- Qdrant
これらの技術について簡単に紹介します。
2-1. SPLADE (Sparse Lexical AnD Expansion)
SPLADE は、Neural Retrievalモデルの一種で、BERTベースのアーキテクチャを用いてSparse Vectorを生成します。 以下の図は、SPLADEを使った検索の概要を示しており、入力テキストをSparse Vectorに変換してInverted Indexで検索する仕組みを表しています。
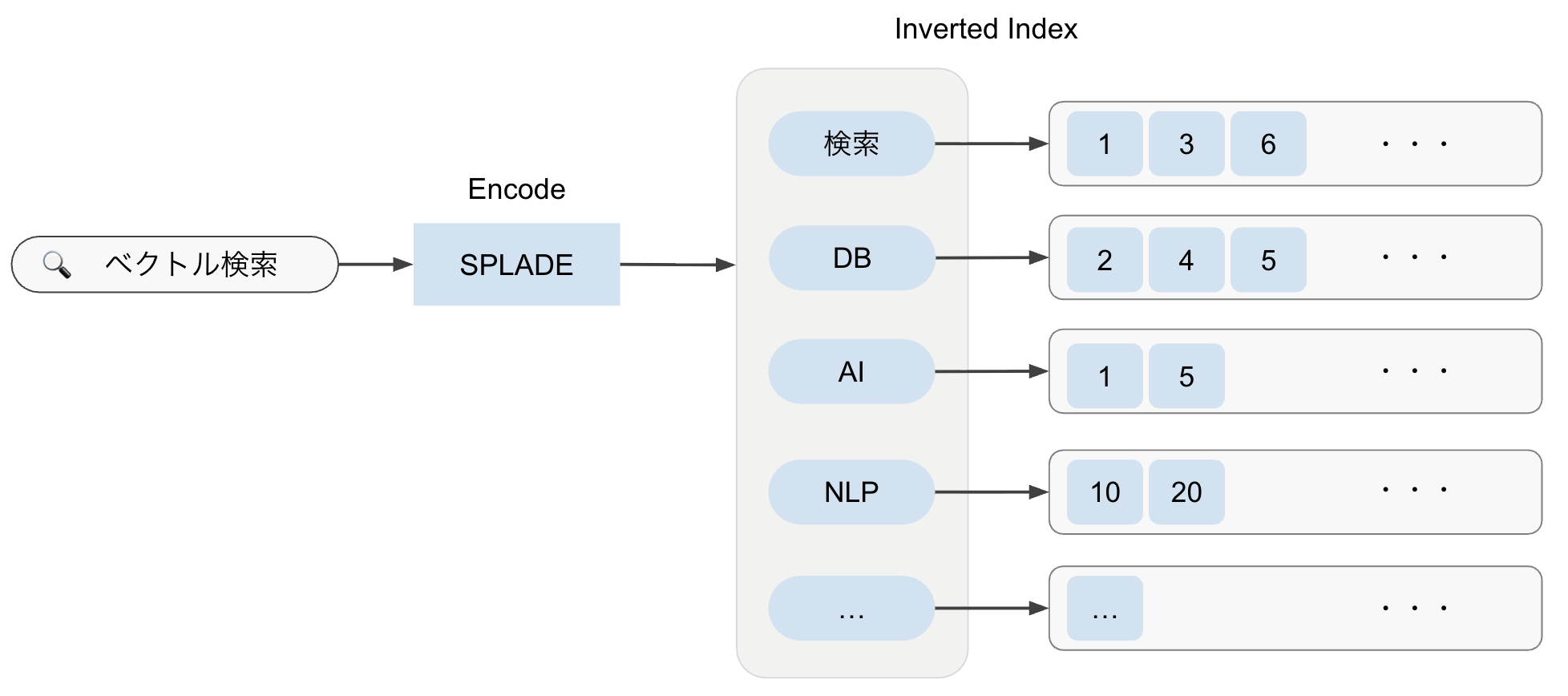
特徴として以下が挙げられます。
- BERTベースのモデルで、Sparse Regularization(スパース正則化) を用いて学習されます。
- Sparse Expansion(スパース展開): 文中に存在する単語だけでなく、「関連性が高い潜在的な単語」も付与してベクトル化します。これにより、単語の不一致(Vocabulary Mismatch)問題を緩和します。
- 推論: 入力に関連する語彙のみが高い値を持ち、関係ない語彙はゼロになるようなベクトルを出力します。
以下は、テキストをSPLADEでエンコードした際の例です。(あくまでも例示なので、出力が異なる場合があります。)
|
|
2-2. Qdrant
Qdrant は、Rustで実装された高機能なオープンソースのベクトル検索エンジン(Vector Database)です。AIアプリケーション向けに設計されており、大規模なベクトルデータを高速に検索・管理するための「プロダクションレディ」な機能を備えています。
主な特徴として以下が挙げられます。
- ハイブリッド検索への対応: Dense Vectorだけでなく、Sparse Vectorをネイティブにサポートしています。これにより、単一のデータベースで「意味検索」と「キーワード検索」の両立や、それらを組み合わせたハイブリッド検索が可能です。
- 高速かつスケーラブル: Rustによる実装で非常に高速に動作します。また、クラウドネイティブな分散アーキテクチャを採用しており、データの増加に合わせて水平スケールが可能です。
- 強力なフィルタリング機能: ベクトルだけでなく、Payload(JSON形式のメタデータ)を保存できます。検索時にこのメタデータを使って、「特定のカテゴリの中で最も類似したデータを探す」といった高度なフィルタリングが可能です。
- 豊富なインターフェース: REST APIおよびgRPCをサポートしており、Python, Go, Rust, TypeScriptなどの公式クライアントライブラリが提供されています。
通常のベクトル検索エンジンはHNSWアルゴリズムなどでDense Vectorを扱いますが、QdrantはInverted Indexを持っています。今回はこの機能を利用して、SPLADEで生成したSparse Vectorの格納と検索を行います。
3. アーキテクチャ: SPLADE + Qdrantの検索フロー
SPLADEでベクトル化し、Qdrantで検索を行う全体の流れは以下のようになります。
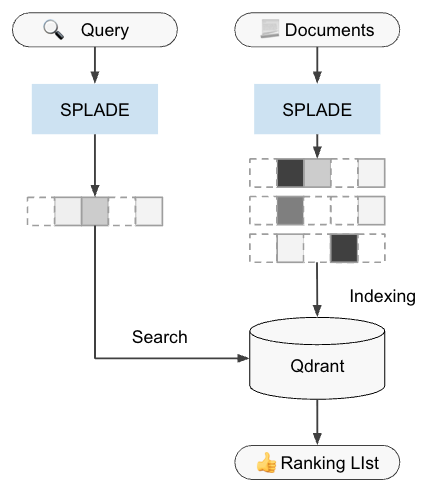
- インデックス作成
- Input: ドキュメント群をSPLADEモデルに入力。
- Vectorize: ドキュメントごとのSparse Vectorを生成。
- Upsert: 生成されたベクトルをQdrantに格納(内部でInverted Indexが構築される)。
- 検索
- Query: ユーザーのクエリをSPLADEモデルに入力。
- Vectorize: クエリ用のSparse Vectorを生成。
- Search: このベクトルを用いてQdrantに問い合わせ。Inverted Indexを介して類似ドキュメントを高速に取得。
流れを整理したので、次に実際のコード例を見ていきましょう!
4. 実装例
実際に SPLADE と Qdrant を組み合わせて実装してみます。
今回は、Sparse Embeddingの生成にlight-spladeを使用します。 light-spladeは、BizReach (Visional) がOSSとして公開しているライブラリです。日本語の事前学習モデルをベースにSPLADEの学習を行っており、以下の特徴があります。
- 日本語特化: 日本語の語彙や文脈を考慮したトークン拡張が行われるため、高い検索精度が期待できます。
- 軽量・高速: 実用性を重視してモデルサイズが抑えられており(今回は約28Mパラメータのモデルを使用)、CPU環境でも比較的高速に推論が可能です。
使用するコード、ライブラリ、モデルは以下の通りです。
- サンプルコード:
- ライブラリ:
- light-splade (BizReach Inc.)
- qdrant-client
- 使用モデル:
それでは、実装の詳細を見ていきましょう。
4-1. ヘルパー関数の準備 (encode.py)
まず、SPLADEの出力をQdrantのSparseVector形式(インデックスと値のリスト)に変換する関数を用意します。トークン文字列をtoken2idを使って数値IDに変換している点がポイントです。
|
|
4-2. メイン処理の流れ (main.py)
QdrantクライアントとSPLADEエンコーダを初期化し、コレクションの作成、データの登録(Upsert)、検索の実行を行うメイン処理を実装します。 それでは、メインの処理をステップごとに見ていきましょう。
Step 1: クライアントとモデルの初期化
Qdrantのクライアントと、日本語対応のSPLADEエンコーダを初期化します。
|
|
Step 2: コレクションの作成
Qdrantにコレクションを作成します。ここで重要なのはsparse_vectors_configを設定することです。これにより、指定した名前(ここでは text-sparse)でSparse Vectorを格納できるようになります。
|
|
Step 3: データの登録 (Upsert)
ドキュメントをエンコードしてPointStructのリストに変換し、Qdrantに登録(Upsert)します。
|
|
Step 4: 検索の実行 (Search)
クエリをエンコードし、検索を実行します。(Qdrant v1.7以降で推奨されている query_points APIを使用します。)
using パラメータには、検索に使用するベクトルの名前(text-sparse)を指定します。
|
|
4-3. 実行結果
上記のコードを実行すると、クエリ「ベクトル検索の仕組み」に対して、関連性の高いドキュメントがスコア順に出力されます。 以下は、実行した際のコンソール出力です。
|
|
このように、light-spladeとQdrantを利用することで、簡単に実装できます!
5. Sparse Vector Search実用化のためのポイント
実装は容易ですが、プロダクション環境で運用するためには以下の点を考慮する必要があります。
- 要件の明確化
- レイテンシ、スループット、精度の目標値を定めます。
- 「本当にベクトル検索が必要か?」という視点も重要です。要件によっては古典的な検索(ElasticsearchのBM25など)で十分な場合もあります。
- 評価基盤の整備
- オフライン評価(テストデータでの精度計測)とオンライン評価(実際のユーザー行動ログ)の仕組みを整えます。
- ステークホルダーと「何をもって検索が良いとするか」の合意形成を行うことが重要です。
- モデルのファインチューニング
- 汎用モデルでは特定ドメインの用語に対応できない場合があります。
- ユースケースに応じてモデルのドメイン適応(Fine-tuning)を実施し、そのためのデータパイプラインを構築します。
これらのことを踏まえ、Sparse Vector Searchに限らず、検索システム全体の設計・運用・改善を検討していくことが重要です。
まとめ
- QdrantとSPLADEを組み合わせることで、キーワード検索の高速性とニューラルネットワークの表現力を両立した検索が実現可能です。
- light-spladeを利用すれば、QdrantのSparse Vector機能を活用した検索パイプラインを数行のコードで容易に構築できます。
- 実用化に向けては、実装だけでなく定量的な評価基盤の整備や、ユースケースに合わせたモデルのファインチューニングが重要です!
最後に一言!
☝️ BizReach 🔍 Information Retrieval 🐐 GOAT (Greatest Of All Time)
と胸を張って言えるように頑張りたいと思います!
参考文献・リンク
- Qdrant Official Site
- SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval
- SPLADE GitHub
- light-splade (BizReach Inc.)
- Visional Engineering Blog: Japanese SPLADE OSS
- Neural Lexical Search with Learned Sparse Retrieval
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。









