
本記事は、情報検索・検索技術Advent Calendar 2025 の23日目の記事です。
はじめに
ビズリーチの検索基盤グループのDatです。
HR領域には特有の複雑な語彙があるため、汎用の検索モデルを使っても専門用語が正しく出力しないことがよくあります。 本記事では、そのような課題に対応するために、語彙の定義から作り直したHRドメイン特化SPLADEモデルの構築事例を紹介します。
本パイプラインは、「ドメイン適応事前学習(Domain Adaptive Pretraining)」によって基礎的な言語能力を高め、「知識蒸留(Knowledge Distillation)」によって高い検索精度を実現する構成となっています。 今回は、その具体的な設計と実装フローについて解説します。
背景と課題:汎用モデルにおける「言葉の壁」
私たちは、企業と求職者の最適なマッチング機会を最大化するため、日々検索品質の向上に取り組んでいます。 特に、職務経歴書(レジュメ)や求人票(JD)といった複雑なドキュメントの内容を深く理解し、関連性の高い候補者を提示することはプラットフォームの核心的な課題です。
この課題解決のアプローチとして、私たちはセマンティック検索の実装を進めています。
プロダクトへの導入にあたっては、「高精度」であることはもちろん、ユーザー体験を損なわない「低レイテンシ」、そして検索結果の妥当性を説明できる「高い解釈性」という3つの要件を満たす必要がありました。
これらの厳しい条件をクリアする技術として採用したのが、疎ベクトルベースのニューラル検索モデルSPLADE (Sparse Lexical and Expansion Model) です。
導入背景についての詳細は以前公開したブログをご覧ください。
「検索エンジニアMeetUP #2 -ドメインにディープダイブするLLMと検索 -」開催レポート
一般に公開されている日本語の事前学習済みモデルは、Web上の一般的なテキストを基に学習されています。そのため、HR領域で頻出する専門性の高い単語や特定のスキル名に対し、適切なトークン化が行えないケースが発生します。 例えば、「Kubernetes」や「法人営業」といった単語が、汎用トークナイザによって意味を持たない細かい文字列に寸断されてしまうことがあります。
SPLADEのような疎ベクトルモデルにおいて、この現象は致命的です。単語が細切れになると、モデルはそれらを「意味のある一つの単位」として認識できず、結果としてSPLADEの最大の利点である「どの単語に重みが置かれたかの解釈性」が損なわれるだけでなく、検索精度そのものも低下してしまいます。 こうした背景から、私たちは既存モデルをそのまま流用するのではなく、語彙の定義から見直し、社内のテキストデータを活用してHRドメインに特化した独自のモデル開発に着手することとしました。
パイプラインの全体像
今回構築したパイプラインは、大きく分けて以下の3つのフェーズで構成されています。
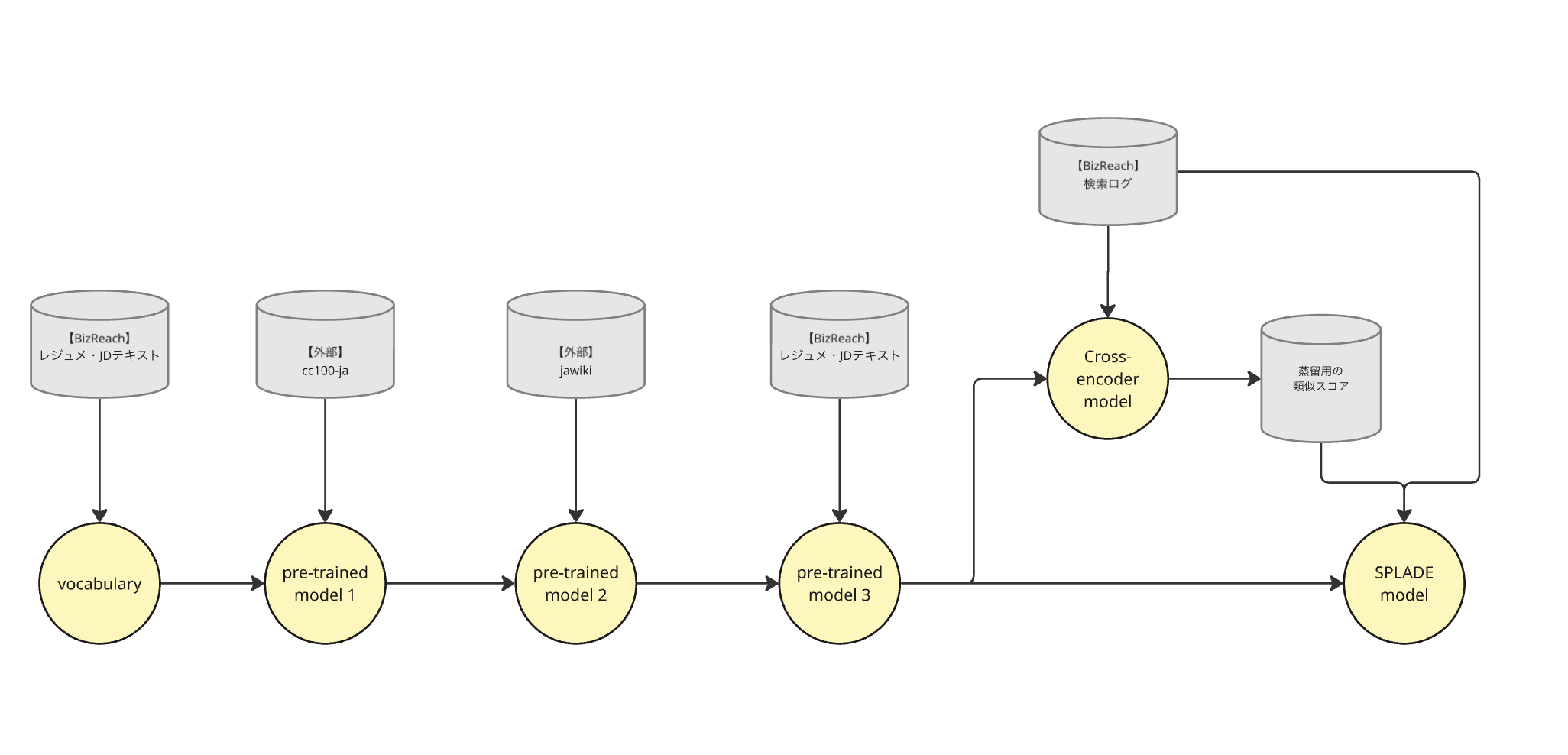
- Phase 1: HR-Domain Adaptive Pretraining:独自語彙の定義と、HRドメインに最適化したベースモデルの事前学習
- Phase 2: Knowledge Distillation: 検索ログとCross-Encoderを用いた学習データ作成
- Phase 3: SPLADE Fine-tuning: HR SPLADEモデルの学習と最適化
次節より、各フェーズの詳細を解説します。
Phase 1: HR-Domain Adaptive Pretraining
まず行ったのが、ベースモデルの構築です。ここでは、Hugging Face Transformersなどを活用し、以下の2ステップでドメイン適応を行いました。
- Step 1. 独自語彙の定義
- Step 2. 段階的な学習プロセス
Step 1. 独自語彙の定義
前述した汎用モデルにおけるトークン分割の粒度不整合を解消するため、公開されているモデルの既存の語彙を流用するのではなく、HRドメインに特化した語彙をゼロから再構築するアプローチを採用しました。
具体的な構築フローとして、まず学習データには社内に蓄積された膨大な「レジュメ」と「JD」を使用しています。 これにより、「ビズリーチ」のプラットフォーム上で実際に流通しているデータ分布を正確に反映した語彙の抽出が可能となります。
トークナイズのパイプラインは以下の2段階で構成されています。
- Pre-tokenization: 日本語の性質を考慮し、形態素解析エンジンMeCabを用いてテキストを形態素単位に分割します。
- Subword Segmentation: 分割されたトークン列に対し、WordPieceアルゴリズムを適用し、頻出する文字列を結合して最終的なサブワード語彙を学習・定義します。
トークナイズについての詳細は下記の記事をご覧ください。
トークナイザー入門! トークンから始めるLLM基礎解説
このプロセスを経ることで、HR領域特有の複合語や専門用語が、意味を成さない文字の羅列に分解されることを防ぎます。 結果として、モデルは専門用語を「意味単位を保持したトークン」として正しくエンコードできるようになり、後段のEmbedding層における表現力の向上や最終的なsparse tokenの解釈性の向上に寄与します。
Step 2. 段階的な学習プロセス
独自に構築した語彙を用いてモデルを初期化した後、汎用的な言語能力とドメイン特有の知識を段階的に獲得させるため、段階的な事前学習を通じてドメイン適応による学習を実施しました。
まず、「cc100-ja」や「jawiki (Wikipedia)」といった大規模なオープンコーパスを用いて学習を行います。このフェーズの目的は、日本語としての構文や、一般領域における意味表現をモデルに獲得させることにあります。
- pre-trained model 1: 巨大な多言語データセットの一部である「cc100-ja」を通じて、日本語の基礎的な文法、語彙、文脈が学習されます。
- pre-trained model 2: 構造化された正確な説明文が多い「jawiki」で、歴史、科学、ビジネス用語などの具体的な知識が学習されます。
続いて社内に蓄積された「レジュメ・JDテキスト」を学習データとし、継続事前学習(Continual Pre-training)を行います。これにより、モデルのパラメータをHRドメインのデータ分布へと適応させます。 こうして構築された「pre-trained model 3」は、HR領域に対する高い表現能力を備えることができます。
Phase 2: Knowledge Distillation
ドメイン適応事前学習を完了したモデルに対し、下流タスクである「検索ランキング」の性能を最大化するため、知識蒸留のアプローチを採用しました。
本パイプラインの設計は、SPLADE++ の論文で提案されている学習手法に準拠しています。Sparse Retrievalモデル(Studentモデル)の学習において、よりリッチな文脈理解能力を持つモデル(Teacherモデル)からの蒸留が、Zero-shot性能および検索精度の向上に決定的な役割を果たすことが実証されているためです。 私たちは、計算コストは高いものの極めて高精度なCross-EncoderをTeacherモデルとして採用し、その推論によって生成されたスコア分布を、Studentモデルの学習ターゲットとする構成をとりました。
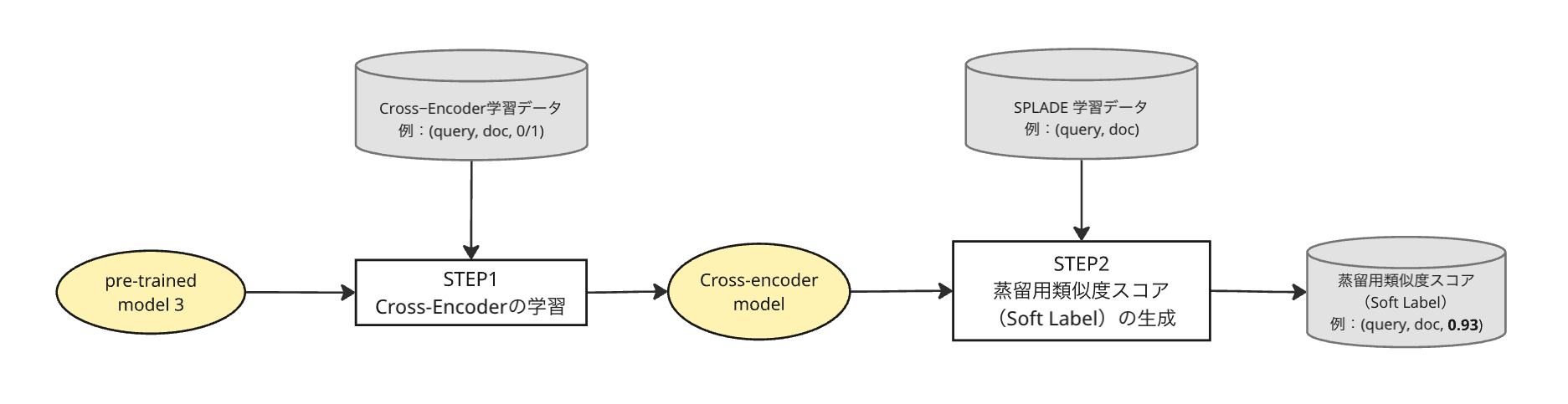
このフェーズは図2のように以下の2ステップで構成されます。
Step 1: Cross-Encoderの学習
まず、蒸留の「手本」となるTeacherモデル自体を、HRドメインのデータで最適化します。
Phase 1で構築した「Pre-trained model 3」を初期重みとして使用します。これにより、TeacherモデルもHR用語を正しく理解した状態からスタートします。 実際の検索ログから、クエリと候補者のペアをサンプリングします。ここでは、クリック等のユーザーアクションを伴うPositiveなペアに加え、検索結果には表示されたがクリックされなかったHard Negativesを含むペアも抽出します。 これらを用いてCross-EncoderとしてFine-tuningを行うことで、HRドメインにおける「理想的なランキング基準」を持つTeacherモデルを作成します。
Step 2: 蒸留用類似度スコア(Soft Label)の生成
次に、学習済みのTeacherモデルを用いて、Studentモデルのための学習データを作成します。
検索ログから抽出したクエリとレジュメ(ドキュメント)のペアに対し、Teacherモデルで推論を実行します。
Cross-Encoderは、[CLS] Query [SEP] Document の形式で入力を結合し、全トークン間の相互作用を計算するため、クエリとドキュメント間の複雑な文脈依存関係を捉えることが可能です。
この工程により、離散的な0/1のラベルではなく、Teacherモデルによるクエリとドキュメントのペアの類似度スコアが生成されます。この類似度スコアをStudentモデルのための学習データにします。
これにより、後続のPhase 3において、Studentモデルは単なる正誤だけでなく、Teacherモデルが捉えた「クエリとドキュメントの間の微細な意味的関連度」までを模倣するように学習することが可能となります。
Phase 3: SPLADE Fine-tuning
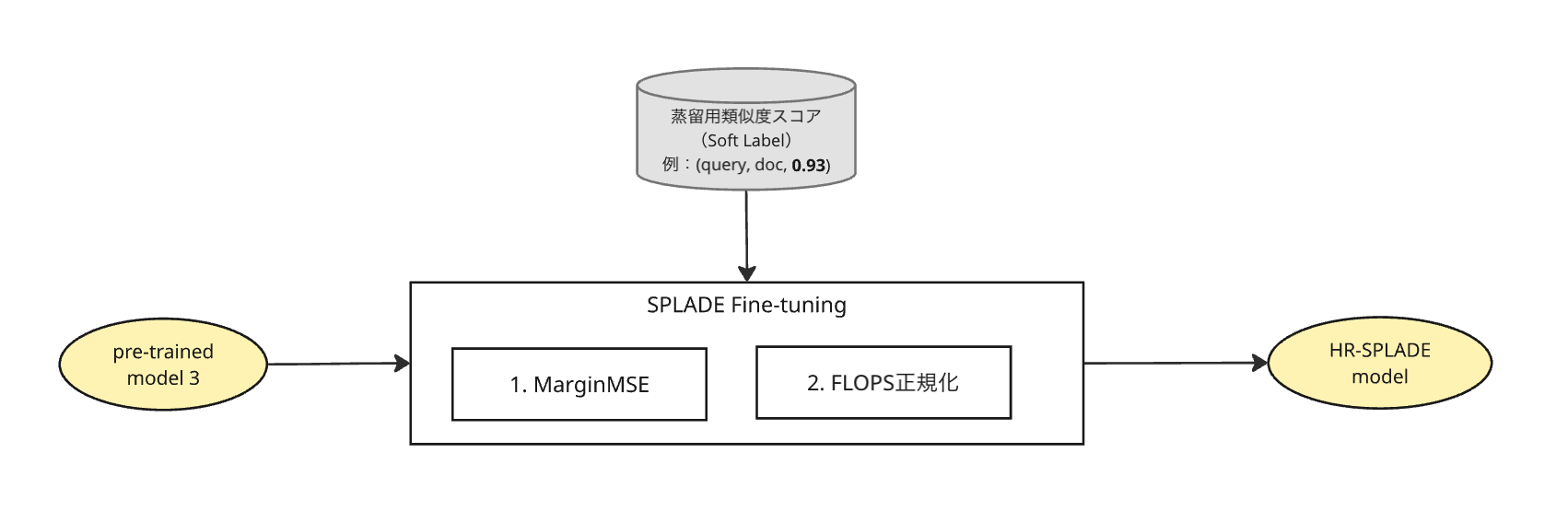
Phase 2で準備した「学習データ」とPhase 1の「事前学習モデル」を用い、プロダクトとして利用するHR SPLADEモデルの学習を行います。SPLADEの学習においては、「検索精度の追求」と「インデックスサイズの抑制(検索速度)」という、相反する要素のバランスを取る必要があります。 本フェーズでは、このバランスを最適化するために、図3のように以下の2つの要素を組み合わせた損失関数を利用します。
- Step 1: 知識蒸留によるランキング学習(Distillation Loss)
- Step 2: スパース正則化による活性制御(Regularization Loss)
Step 1: 知識蒸留によるランキング学習
学習の初期モデル(Studentモデル)には、Phase 1で作成した「Pre-trained model 3」を使用します。 学習データには、Phase 2でCross-Encoderが出力したクエリとドキュメントのペアの類似度スコアを利用します。
通常のランキング学習では、正例か負例か(0 or 1)の情報のみを使いますが、ここではTeacherモデルが出力した「スコア差(Margin)」をStudentモデルに再現させることを目的とします。具体的には、Teacherモデルが予測したPositiveドキュメントとNegativeドキュメントのスコア差と、Studentモデルが出力するスコア差の二乗誤差(MarginMSE)を最小化するように学習を進めます。
これにより、Cross-Encoderが持つ「複雑な文脈理解に基づくランキング能力」を、StudentモデルであるSPLADEが効率的に継承することが可能になります。
Step 2: スパース正則化による活性制御
SPLADEの最大の特徴は、BERTの数万次元の語彙数に及ぶベクトル空間の中で、ごく少数の次元のみを活性化(非ゼロ化)させる点にあります。しかし、精度を上げようとすればするほど、モデルは多くの単語(次元)を使って文書を表現しようとするため、ベクトルが密(Dense)になり、検索エンジンのインデックス肥大化や検索速度の低下を招きます。
そこで、学習時の損失関数に「FLOPS正則化項」を組み込みました。これは、活性化する次元が増えることに対してペナルティを与える仕組みです。
この正則化項の係数を調整することで、「表現力を高めるための単語拡張(Expansion)」と「高速な検索のためのスパース性(Sparsity)」のトレードオフをコントロールします。最終的に、HRドメインにおいて重要なキーワード(職種やスキルなど)はしっかりと拡張しつつ、検索に不要な一般的な語彙の重みはゼロに抑え込むことで、実運用に耐えうる推論モデルへと最適化させました。
SPLADEの学習の仕組みの詳細と、弊社が提供している商用利用可能なパッケージについては、こちらのブログをご覧ください。
日本語SPLADEモデルと学習コードのOSS公開
まとめと今後の展望
本記事では、HR領域に特化した疎ベクトルベースのニューラル検索モデルの構築パイプラインと、その背後にある技術的アプローチについて解説しました。
私たちが直面していた課題に対し、以下の2つの軸でアプローチすることで、実用性と精度を兼ね備えた検索モデルを実現しました。
- ドメイン適応の徹底: 独自語彙の再構築と段階的なPre-trainingにより、汎用モデルでは困難だった「HR専門用語の正確なトークン化」と「業界特有の文脈理解」を達成しました。
- 高精度と高速性の両立: SPLADE++のメソッドに基づく知識蒸留を採用することで、Cross-Encoderが持つ深い推論能力を、低レイテンシで動作する疎ベクトルモデルへと継承させました。
このパイプラインによって構築されたモデルは、従来のキーワード一致のみに頼る検索では拾いきれなかった「言葉の揺らぎ」や「文脈」を考慮した高度なマッチングを可能にします。
今後は、実際のプロダクト環境におけるA/Bテストを通じて検索精度の検証を進めるとともに、大規模なトラフィックに耐えうる推論環境の最適化や、更なるレイテンシの改善にも取り組んでいく予定です。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










