
株式会社ビズリーチでAIプラットフォームグループに所属している佐藤光です。
本記事では、長年運用されてきた転職意向予測モデルのVertex AI Pipelinesへの移行について紹介します。
本記事は、2026年3月30日に開催された 第62回MLOps/LLMOps/AgentOps勉強会 で登壇した 資料 をベースに、ブログ向けに再構成したものです。
プロジェクトの概要:Vertex AI Pipelinesで目指したMLOpsの土台
「ビズリーチ」のAIチームでは、「1人1アプリ」のように個々のエンジニアが担当モデルを抱え込む体制でした。しかしAIモデルの数が増えるにつれて属人化・可観測性不足・改善サイクルの非効率といった課題が顕在化しており(詳細は「渋谷Biz × AI」第4回の登壇資料でも紹介しています)、各アプリをチーム全体で運用できるよう標準化を進めています。今回の転職意向予測モデルも優先的に継続的な改善を行う対象となったモデルの一つです。
この移行で目指したのは、「パイプライン分割による可観測性の獲得」と「中間状態を保存して品質を見える化すること」の2本柱です。次の章以降では、なぜこの2つが必要だったのかという背景から順に説明していきます。
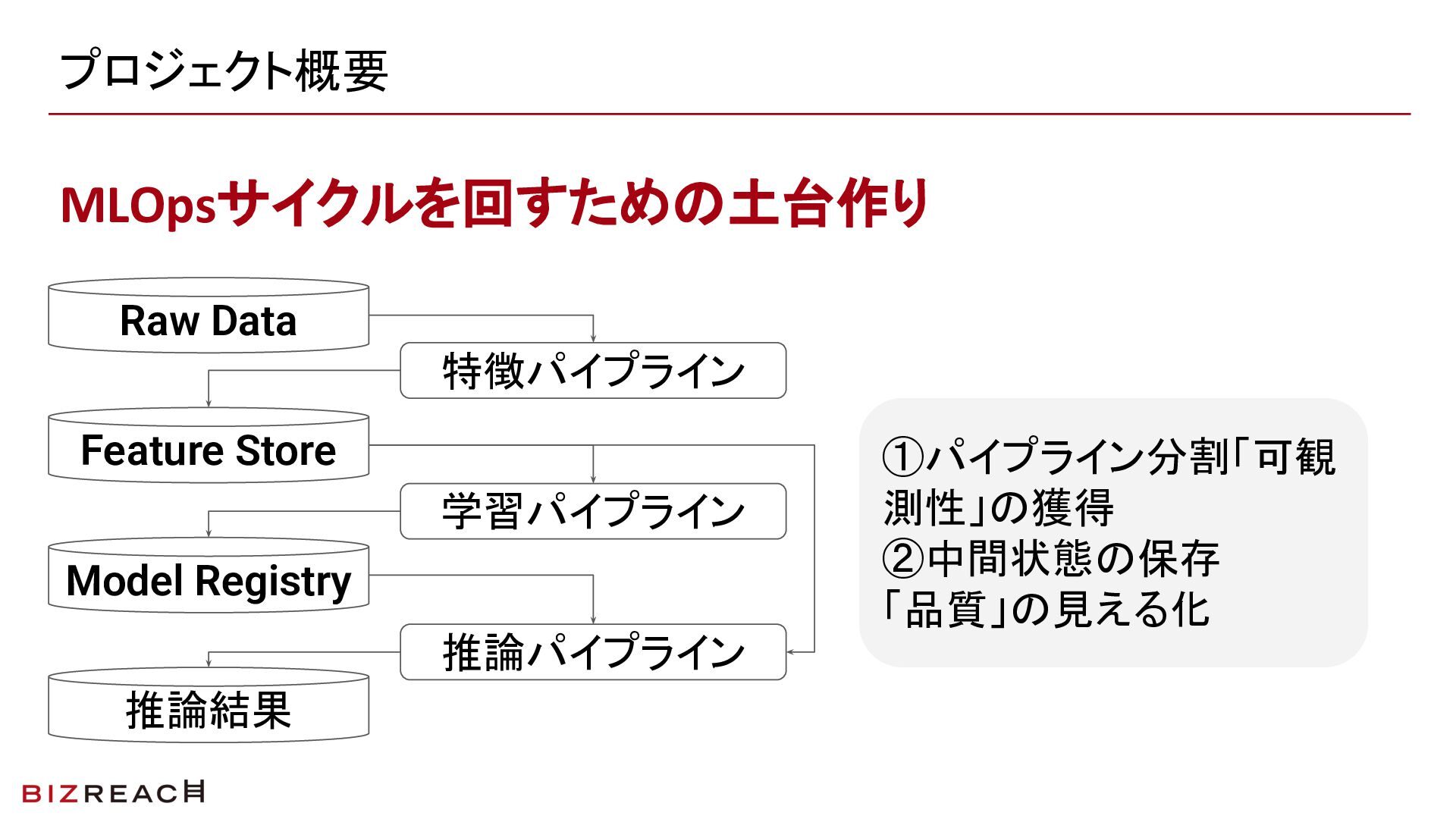
ブラックボックス化したMLシステムの実態
対象となった転職意向予測モデルは、企業と求職者のマッチング機会を最大化するために使われているモデルで、複数のアプリケーションから参照され、継続的に推論結果が配信されてきました。
長年の運用を経て、このモデルは「可観測性0%」の状態になっていました。具体的には以下の3点です。
- 推論結果の分布や精度指標を日常的に見るダッシュボードが存在せず、精度劣化を検知できなかった
- 学習や推論を再実行したときに同じ結果を再現できる仕組みが整っておらず、中間ファイルも残っていなかった
- モデルの出力がどの配信先で、どのように利用されているかを把握できていなかった

構造的な要因は大きく3つです。単一のDockerイメージに前処理・学習・推論・後処理がすべて詰まっていたこと、長年の部分最適な修正が積み重なってきたこと、仕様に関するドキュメントが更新されていなかったこと。その結果、全体像を把握できない状態になっていました。
この状況を受け、解決すべき課題を2つに整理しました。
- 継続的なモニタリング体制の整備:モデルの性能を定常的に監視し、継続的にモデル改善を続けられる体制を作ること
- ブラックボックスの解消:ロジックを解明しドキュメント化して、チームによる運用を可能にすること
これらの課題を踏まえ、移行先としてVertex AI Pipelinesを選びました。主な理由は、サーバーレスで動くためインフラ管理の負荷を下げられること、アーティファクト管理やリネージ(データやモデルの来歴を追跡する仕組み)によって中間状態を追いかけやすくなること、そしてSDKでパイプラインを柔軟に組めることの3点です。
Vertex AI移行の実践:アプリケーション編
一気に全部を書き換えないことを最初の原則に置きました。既存の挙動を保ちながら、以下の4STEPで段階的にコードを分割していきました。
- STEP1:モノリスをそのままVertex AI(Custom Job)に載せる
- STEP2:前処理を切り出しFeature Store化する
- STEP3:後処理を分離する
- STEP4:学習パイプラインと推論パイプラインを完全に切り分ける
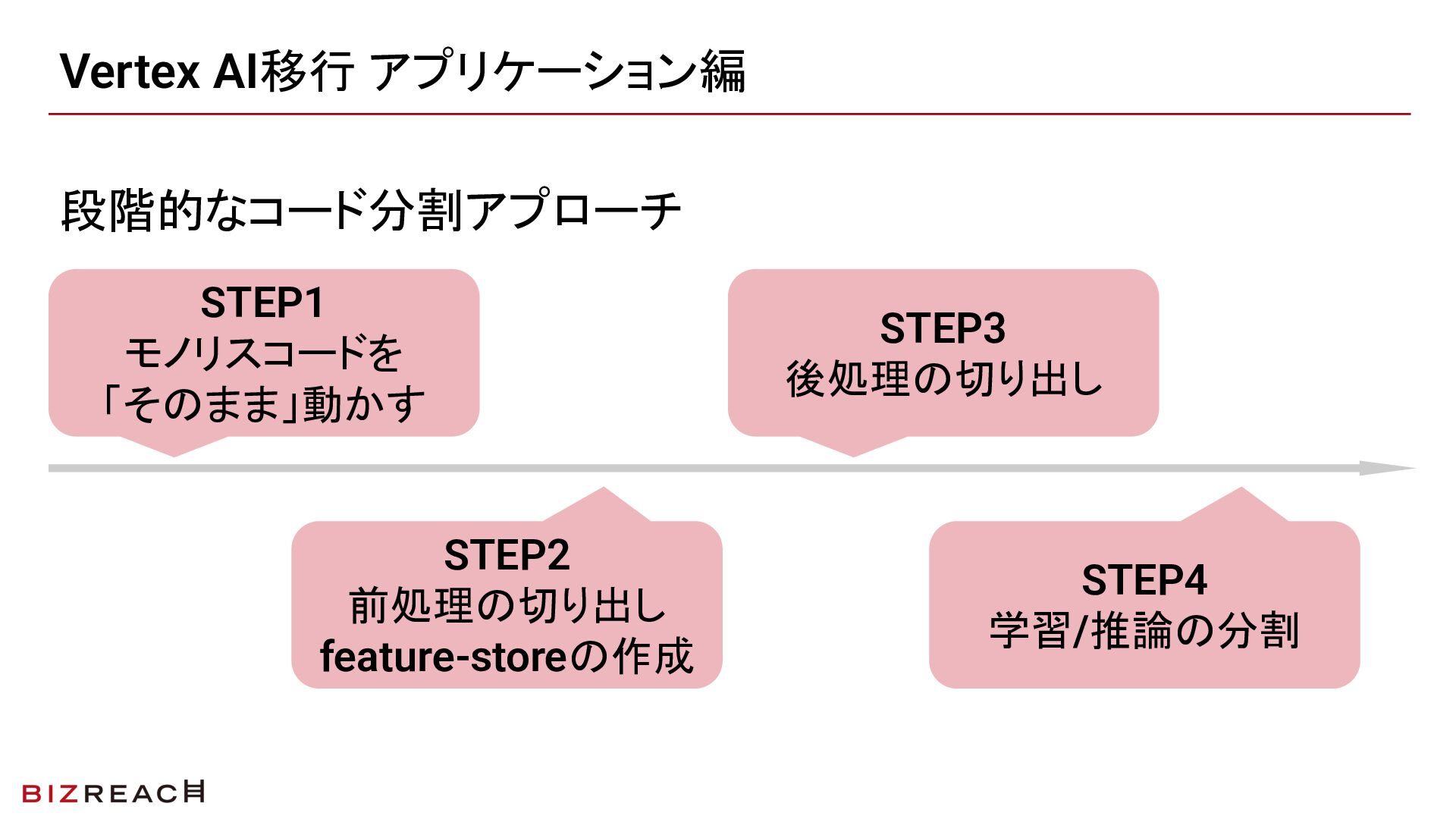
STEPを刻んだことで各段階のコードレビューを小さく保てた結果、レビューがボトルネックになりにくく、全体の完了を早めることができました。また、STEP2のFeature Store化と同時に前処理出力のI/Fテストを追加し、各ステップの出力が期待通りかを確認できる仕組みも整えました。
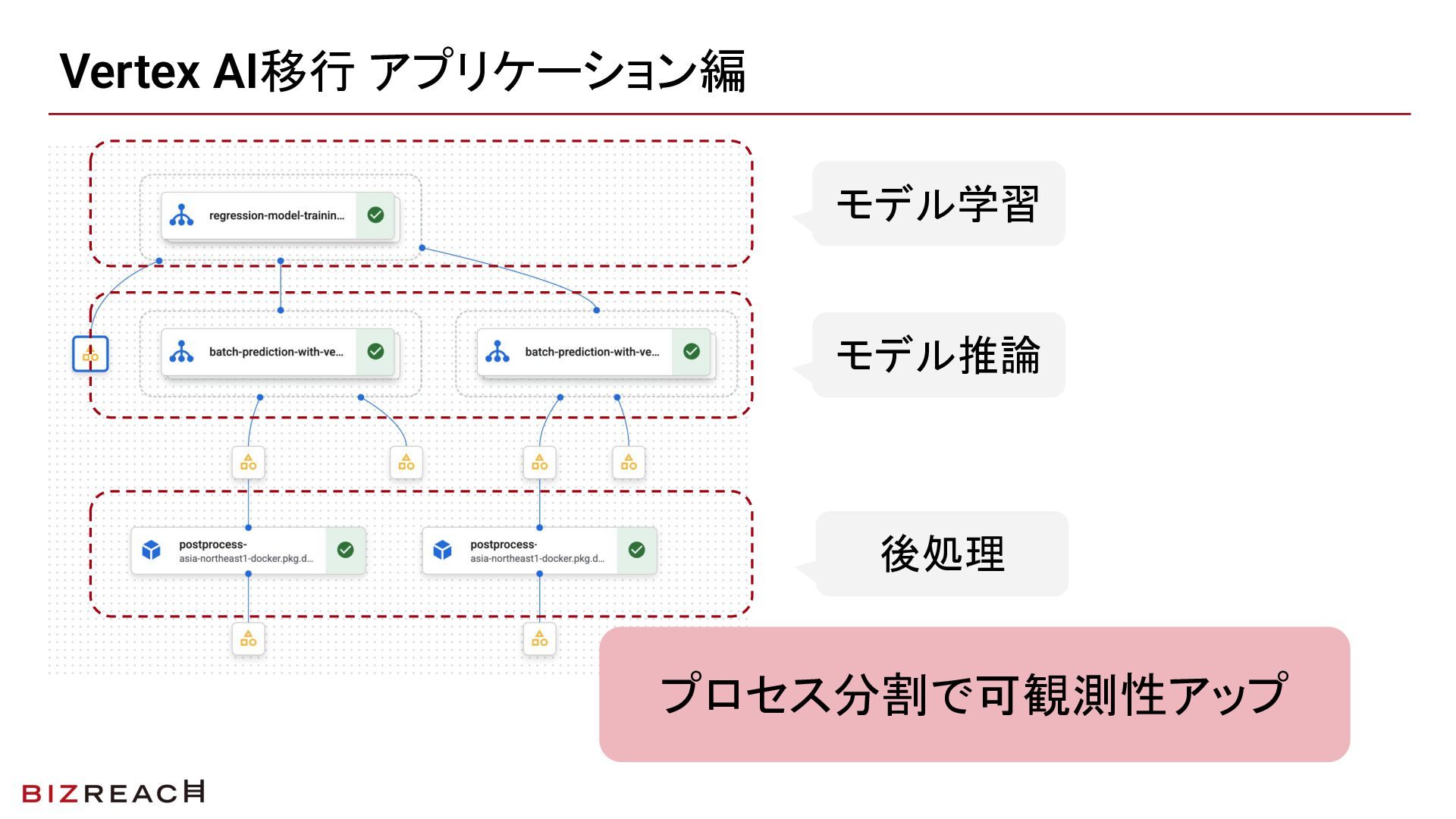
Vertex AI移行の実践:システム構成編
「誰が何を読んでいるか」の全容把握
アプリケーションコードと並行して、モデルの出力がどの配信先に流れているかの棚卸しを進めました。全容を把握しているメンバーがいない状態からのスタートでした。
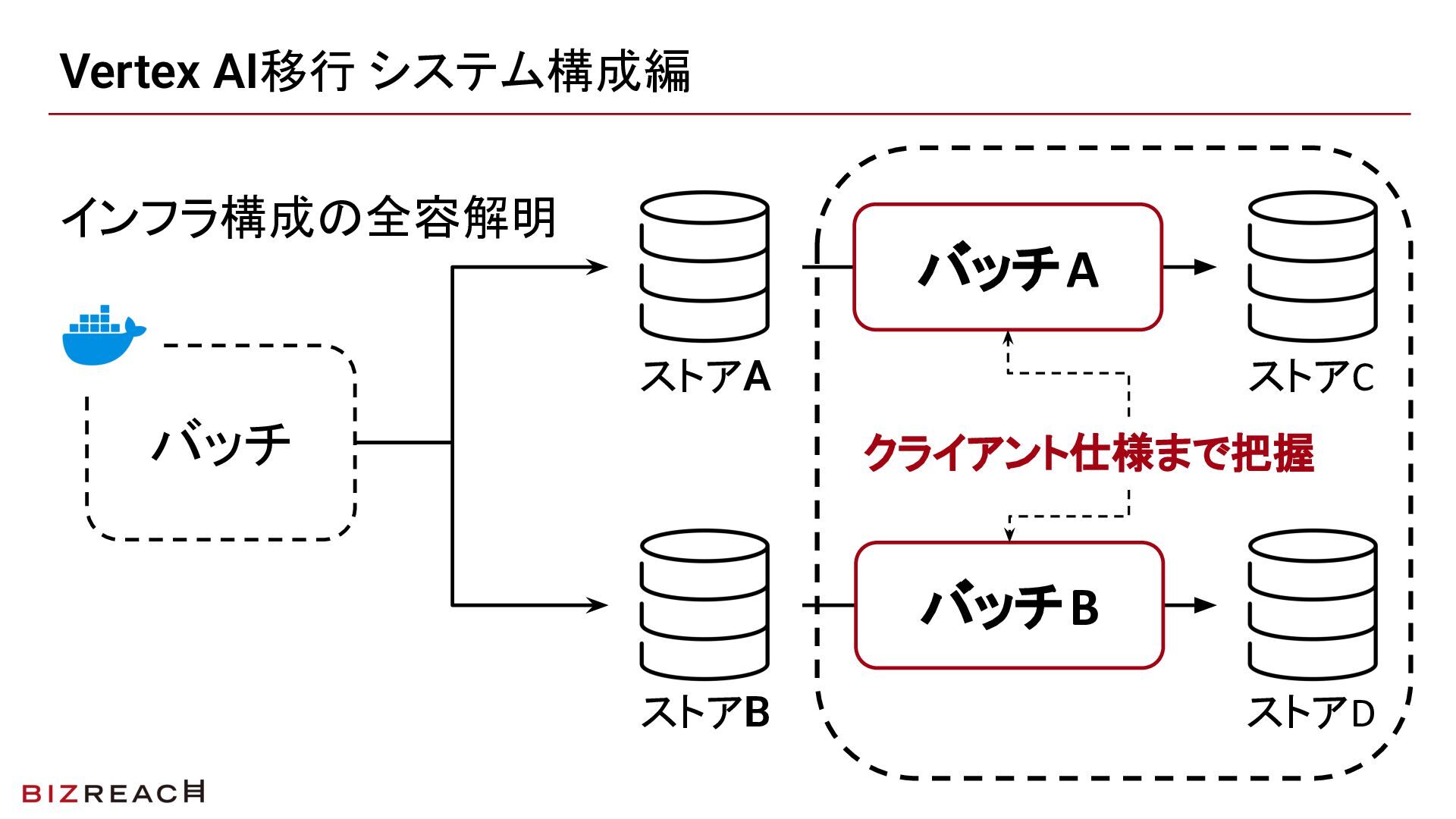
「使われていないクライアント」の発見
棚卸しの過程で、配信されているものの実際には参照されていない経路があることがわかりました。この発見が次章の合意形成につながります。
振り返ると、アプリケーション編とほぼ同じくらいの工数を「誰が何を読んでいるか」の調査に使いました。モデルの実装だけでなく、周辺システムとの接続面の整理が工数の大きな部分を占めました。
Vertex AI移行の実践:プロジェクトマネジメント編
移行を進める上で、事前に各種ステークホルダーとの合意形成を行いました。
不要リソースの整理方針を事前共有
棚卸しで見つかった未使用の配信先は、「移行時に削除するもの」「残すもの」の2パターンに整理し、削除する旨を関係者に事前に伝えました。事前にシステム全体の構成を明らかにしていたので、合意をスムーズに取ることができました。
切替前に障害対応の手順を決めておく
本番切替の前に、想定される問題・検知方法・切り戻し手順・連絡先を1枚のドキュメントにまとめ、関係チームにレビューしてもらいました。事前に合意しておくことで、リリース当日も関係チームと認識を揃えた状態で臨めました。
まとめ:得られた成果
この移行を通じて、チームでMLシステムを自律的に運用できる状態を作ることができました。
冒頭に設定した2つの課題は、次のように回収されました。
- 継続的なモニタリング体制の整備:パイプライン分割とアーティファクト保存により、モデルの状態を継続的に追いかけられる基盤が整いました。精度劣化の早期検知や再現性のある実験が可能になっています。
- ブラックボックスの解消:パイプライン定義とあわせて設計の背景や運用手順をドキュメントとして残せたことで、チームの誰でも全体像を追える状態になりました。また、インフラ棚卸しの過程で未使用の配信先を発見・整理でき、システム全体をスリムにできました。
この移行が土台となり、現在は後続のアプリケーション最適化プロジェクトも進んでいます。ブラックボックスを解消しチームで運用できる状態を作ったことが、継続的な改善サイクルを回し始める出発点になりました。
おわりに
ブラックボックス化したシステムへの対応は、コードだけでなくインフラや合意形成も含めたトータルの取り組みでした。同じような課題に取り組む方の手がかりになれば幸いです。
本記事のベースとなった登壇資料と勉強会の詳細は、以下から参照できます。
ビズリーチでは、新しい仲間を募集しています。
お客様にとって価値あるモノをつくり、働く環境の変革に挑戦する仲間を募集しています。
募集中のポジションやプロダクト組織の詳細は、ぜひキャリア採用サイトをご覧ください。










